NLP中的预训练语言模型(四)—— 小型化bert(DistillBert, ALBERT, TINYBERT)
bert之类的预训练模型在NLP各项任务上取得的效果是显著的,但是因为bert的模型参数多,推断速度慢等原因,导致bert在工业界上的应用很难普及,针对预训练模型做模型压缩是促进其在工业界应用的关键,今天介绍三篇小型化bert模型——DistillBert, ALBERT, TINYBERT。
一,DistillBert
论文:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
GitHub:暂无
DistillBert是在bert的基础上用知识蒸馏技术训练出来的小型化bert。整体上来说这篇论文还是非常简单的,只是引入了知识蒸馏技术来训练一个小的bert。具体做法如下:
1)给定原始的bert-base作为teacher网络。
2)在bert-base的基础上将网络层数减半(也就是从原来的12层减少到6层)。
3)利用teacher的软标签和teacher的隐层参数来训练student网络。
训练时的损失函数定义为三种损失函数的线性和,三种损失函数分别为:
1)$L_{ce}$。这是teacher网络softmax层输出的概率分布和student网络softmax层输出的概率分布的交叉熵(注:MLM任务的输出)。
2)$L_{mlm}$。这是student网络softmax层输出的概率分布和真实的one-hot标签的交叉熵
3)$L_{cos}$。这是student网络隐层输出和teacher网络隐层输出的余弦相似度值,在上面我们说student的网络层数只有6层,teacher网络的层数有12层,因此个人认为这里在计算该损失的时候是用student的第1层对应teacher的第2层,student的第2层对应teacher的第4层,以此类推。
作者对student的初始化也做了些工作,作者用teacher的参数来初始化student的网络参数,做法和上面类似,用teacher的第2层初始化student的第1层,teacher的第4层初始化student的第2层。
作者也解释了为什么减小网络的层数,而不减小隐层大小,作者认为在现代线性代数框架中,在张量计算中,降低最后一维(也就是隐层大小)的维度对计算效率提升不大,反倒是减小层数,也提升计算效率。
另外作者在这里移除了句子向量和pooler层,在这里也没有看到NSP任务的损失函数,因此个人认为作者也去除了NSP任务(主要是很多人证明该任务并没有什么效果)。
整体上来说虽然方法简单,但是效果还是很不错的,模型大小减小了40%(66M),推断速度提升了60%,但性能只降低了约3%。
二,ALBERT
论文:ALBERT: A LITE BERT FOR SELF-SUPERVISEDLEARNING OF LANGUAGE REPRESENTATIONS
GitHub:https://github.com/brightmart/albert_zh
ALBERT主要是从模型架构上做的改变,能极大的减小模型大小,但是没有提升推断速度。ALBERT主要做了三点改变:Factorized embedding parameterization ,Cross-layer parameter sharing ,Inter-sentence coherence loss 。我们先来介绍这三个改变:
Factorized embedding parameterization
在bert中采用的是embedding层的嵌入词向量大小E等于隐层大小H,但是作者认为embedding层只是做了词嵌入,在这一层词与词之间是相互独立的,词嵌入后得到的向量包含的信息也仅仅只有当前词的信息,因此向量长度不需要那么大(我们常用的word2vec向量长度一般不超过300),但是隐层因为会和其他词计算self-attention,因此隐层词对应的向量是包含了上下文信息的,此时含有的信息是非常丰富的,用小的向量容易丢失信息,需要将隐层大小设大一点。针对这样的分析,作者认为像bert中embedding层和隐层大小设置为相等是不合理的(bert-base中,E=H=768)。而且在embedding层,有一个大的词嵌入矩阵V x E。在这里V为vocab size(通常比较大,bert中就是20000多),因此当E很大时,这里的参数就非常多,又基于上面的分析,E可以不用设这么大,因此作者在这里做了一个矩阵分解,将矩阵V x H(E)分解为两个小的矩阵V x E,E x H,E << H。在这里不再将E=H,而是将E设置为一个远小于H的值,然后再经过一个矩阵E x H将词向量维度映射到H。
Cross-layer parameter sharing
再Transformer结构中,我们也可以选择共享一些参数,不如共享self-attention中的参数,或者是共享FFN层的参数,在这里作者共享了encoder中所有的参数(包括self attention和FFN),结合上面的矩阵分解,模型参数得到了极大的减小,具体结果如下图:

另外这种层之间的参数共享机制,也让各层的输入输出的L2距离和余弦距离变化的更加平滑,如下图所示:

Inter-sentence coherence loss
上面两种改变主要是在减小模型的参数,而这里的改变主要是提高模型在下游任务上的性能,作者认为在bert中的NSP任务实际上是有问题的,当初设计这个任务时,是希望能学到句子一致性的,但事实上由于当初在构造句子对负例时,是从不同的document中选择的句子,因此网络并不需要学到句子的一致性,而只要学到句子的主题(因为不同的document,主题很可能不一样),就可以判断两个句子是否是负例,因此作者认为NSP任务只学到了句子的主题,而主题分类是一个浅层语义的NLP任务。
因此在这里作者提出了一种新的任务SOP(句子顺序预测),在这里构造正例和bert中一样,而负例就是将正例中两个句子的顺序颠倒,这里应为负例中的句子都来自于同一文档,所以通过句子的主题是无法区分正例和负例的,需要理解句子的深层语义才能区分,作者也给出了实验证明:

如上面表中所示,学习SOP(86.5)任务,也能在NSP(78.9)任务上取得不错的效果,但是学习NSP(90.5)任务,是无法在SOP(52.0)任务上取得效果的。
以上就为这篇论文改变的三个点,因此矩阵分解和参数共享,模型参数减小了很多,但是因为层数没有变,在推断时的计算量并没有下降,因此推断速度没啥提升,但是训练时的速度有提升。引入SOP任务也能提升模型的效果。此外,ALBERT中的mask方式,采用的是n-gram mask,其实和SpanBert中的span mask是一样的,只是span中将mask的最大长度控制在10,而这里将最大长度控制在3。另外优化算法采用了LAMB优化器。
最后上一个ALBERT的模型效果:
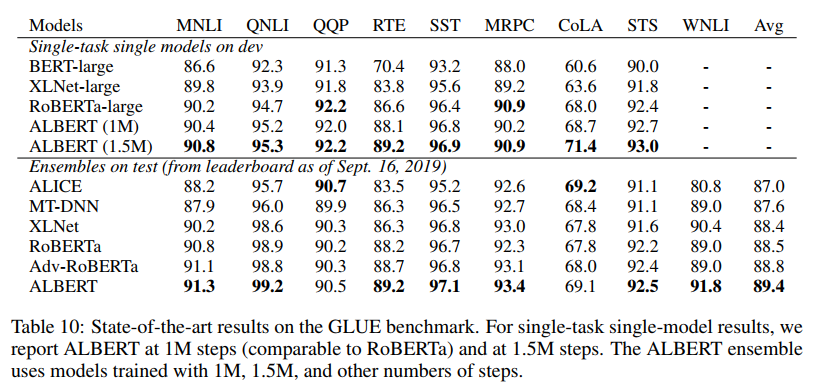
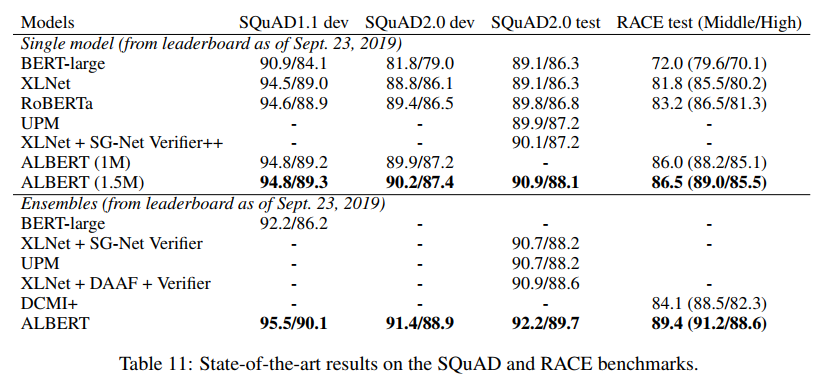
这里的ALBERT是用的ALBERT-xxlarge,其参数如下:
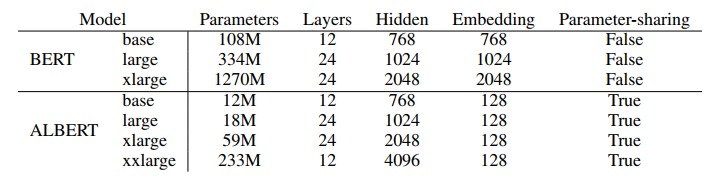
增大了隐层大小到4096,但实际上在这里作者证明了并不是所有的模型增大隐层大小,模型的效果都会提升,比如作者在bert-large上证明了提升隐层大小到2048时,模型下降很多:

三,TINYBERT
论文:TINYBERT: DISTILLING BERT FOR NATURAL LANGUAGE UNDERSTANDING
GitHub:暂无
TINYBERT也是采用了知识蒸馏的方法来压缩模型的,只是在设计上叫distillBert做了更多的工作,作者提出了两个点:针对Transformer结构的知识蒸馏和针对pre-training和fine-tuning两阶段的知识蒸馏。
作者在这里构造了四类损失函数来对模型中各层的参数进行约束来训练模型,具体模型结构如下:
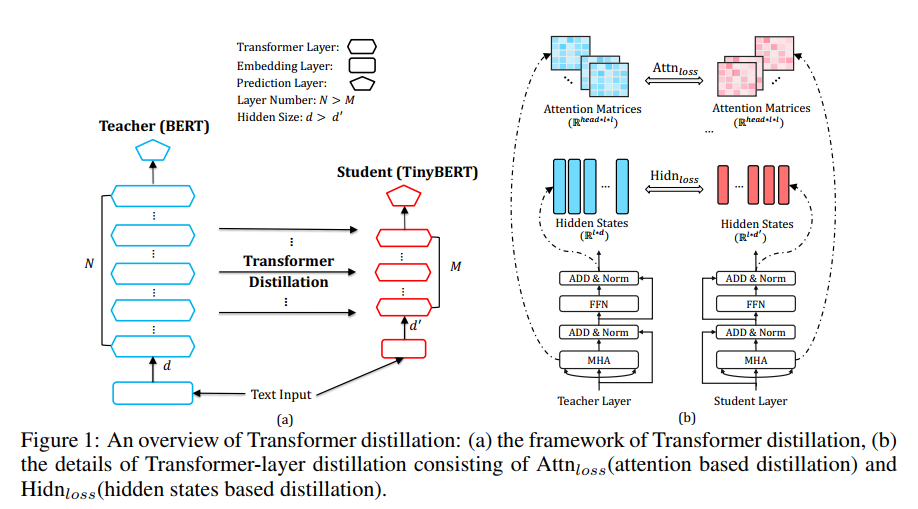
作者构造了四类损失,分别针对embedding layer,attention 权重矩阵,隐层输出,predict layer。可以将这个统一到一个损失函数中:
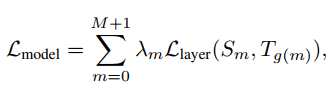
上面式子中$\lambda_m$表示每一层对应的系数,$S_m$表示studnet网络的第m层,$T_{g(m)}$表示teacher网络的第n层,其中$n = g(m)$。并且有$g(0) = 0$,$g(M+1) = N+1$,0表示embedding layer,M+1和N+1表示perdict layer。
针对上面四层具体的损失函数表达式如下:
attention 权重矩阵
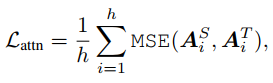
h为multi attention中头数
隐层输出
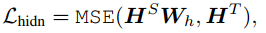
因为student网络的隐层大小通常会设置的比teacher的小,因此为了在计算时维度一致,这里用一个矩阵$W_h$将student的隐层向量线性映射到和teacher同样的空间下。
embedding layer

$W_s$同理上。
以上三种损失函数都采用了MSE,主要是为了将模型的各项参数对齐。
predict layer
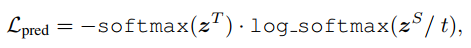
predict layer也就是softmax层,在这里的损失函数是交叉熵,t是温度参数,在这里设置为1。
以上四种损失函数是作者针对transformer提出的知识蒸馏方法。除此之外作者认为除了对pre-training蒸馏之外,在fine-tuning时也利用teacher的知识来训练模型可以取得在下游任务更好的效果。因此作者提出了两阶段知识蒸馏,如下图所示:
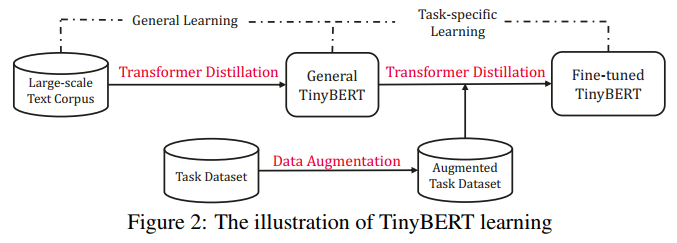
本质上就是在pre-training蒸馏一个general TinyBERT,然后再在general TinyBERT的基础上利用task-bert上再蒸馏出fine-tuned TinyBERT。
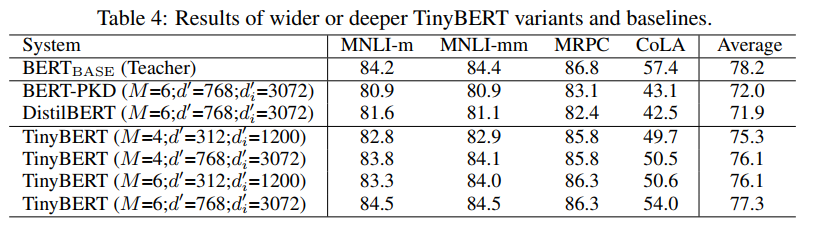
作者给出了TinyBERT的效果:
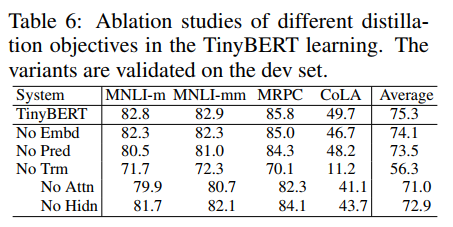
另外作者也给出了四种损失对最终结果的贡献:
还有就是关于$n = g(m)$这个式子中$g(m)$怎么选择,假设student的层数为4层,这里的$n = g(m) = 3m$,作者将这种称为Uniform-strategy。另外作者还和其他的$g(m)$做了对比:

Top-strategy指用teacher最后4层,Bottom-strategy指用前面4层,其实这里的映射函数,我感觉可能还有更优的方案,例如取平均,或者用attention来做,可能效果会更好。
NLP中的预训练语言模型(四)—— 小型化bert(DistillBert, ALBERT, TINYBERT)的更多相关文章
- NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好. 论文: ...
- NLP中的预训练语言模型(三)—— XL-Net和Transformer-XL
本篇带来XL-Net和它的基础结构Transformer-XL.在讲解XL-Net之前需要先了解Transformer-XL,Transformer-XL不属于预训练模型范畴,而是Transforme ...
- NLP中的预训练语言模型(一)—— ERNIE们和BERT-wwm
随着bert在NLP各种任务上取得骄人的战绩,预训练模型在这不到一年的时间内得到了很大的发展,本系列的文章主要是简单回顾下在bert之后有哪些比较有名的预训练模型,这一期先介绍几个国内开源的预训练模型 ...
- NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
本篇带来Facebook的提出的两个预训练模型——SpanBERT和RoBERTa. 一,SpanBERT 论文:SpanBERT: Improving Pre-training by Represe ...
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
随机推荐
- ASP.NET开发实战——(十三)ASP.NET MVC 与数据库之EF实体类与数据库结构
大家都知道在关系型数据库中每张表的每个字段都会有自己的属性,如:数据类型.长度.是否为空.主外键.索引以及表与表之间的关系.但对于C#编写的类来说,它的属性只有一个数据类型和类与类之间的关系,但是在M ...
- QBXT模拟赛1
总结 期望得分:\(100 + 80 + 10 = 190\) 实际得分:\(90 + 80 + 10 = 180\) 这是在清北的第一场考试,也是在清北考的最高的一次了吧..本来以为能拿\(190\ ...
- 日常笔记6C++标准模板库(STL)用法介绍实例
一.vector常见用法详解 vector翻译为向量,但是这里翻译成变长数组的叫法更好理解. 如果typename是一个STL容器,定义的时候要记得在>>符号之间加上空格,因为在C++11 ...
- Codeforces Round #596 (Div. 2, based on Technocup 2020 Elimination Round 2) D. Power Products 数学 暴力
D. Power Products You are given n positive integers a1,-,an, and an integer k≥2. Count the number of ...
- centos7彻底卸载mysql和通过yum安装mysql
彻底卸载mysql 查看是否有安装的mysql rpm -qa | grep -i mysql // 查看命令1 1 这里写图片描述 yum list install mysql* // 查看命令2 ...
- 利用 Javascript 让 DIV 自适应屏幕的分辨率,从而决定是否显示滚动条
直接贴代码了: <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> < ...
- JWT攻击手册
JSON Web Token(JWT)对于渗透测试人员而言可能是一种非常吸引人的攻击途径,因为它们不仅是让你获得无限访问权限的关键,而且还被视为隐藏了通往以下特权的途径:特权升级,信息泄露,SQLi, ...
- Prometheus监控学习笔记之Prometheus如何热加载更新配置
0x00 概述 当 Prometheus 有配置文件修改,我们可以采用 Prometheus 提供的热更新方法实现在不停服务的情况下实现配置文件的重新加载. 0x01 热更新 热更新加载方法有两种: ...
- 利用正则来查找字符串中第n个匹配字符索引
1.string.IndexOf()方法可以获得第一个匹配项的索引 2.要获取第n个匹配项的索引: 方法1:利用IndexOf方法循环获取. 方法2:用正则来查找. System.Text.Regu ...
- PIE属性表多字段的文本绘制
最近研究了PIE SDK文本元素的绘制相关内容,因为在我们的开发中,希望可以做到在打开一个Shp文件后,读取到属性表的所有字段,然后可以选择一些需要的字段,将这些字段的所有要素值的文本,绘制到shp图 ...