Iris Classification on Tensorflow
Iris Classification on Tensorflow
Neural Network
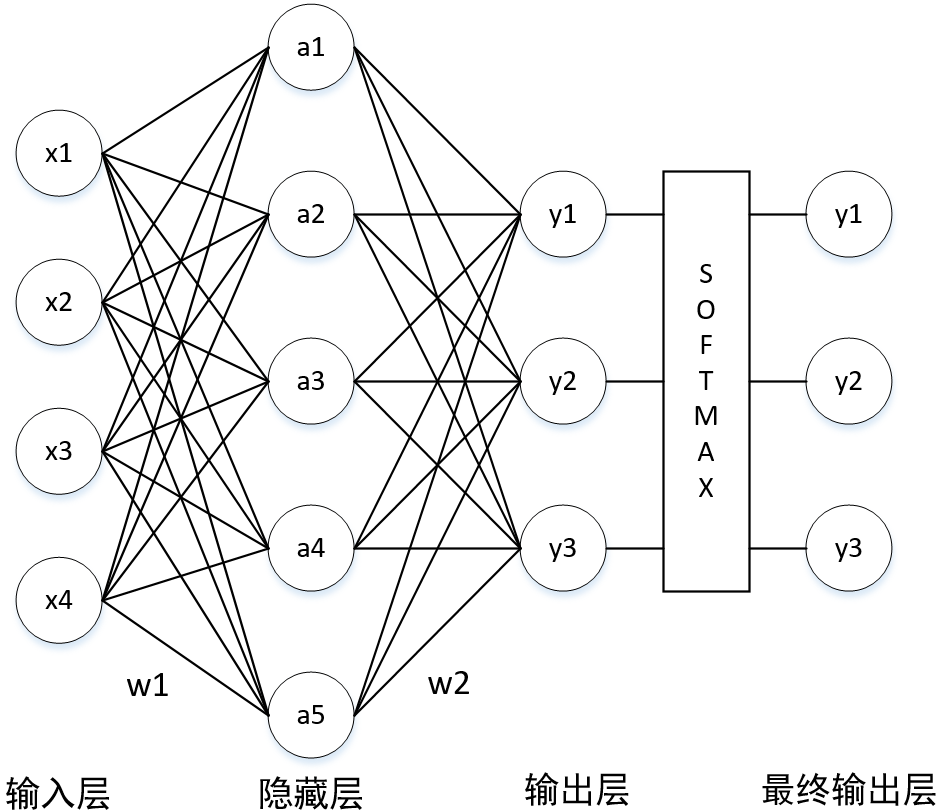
formula derivation
a & = x \cdot w_1 \\
y & = a \cdot w_2 \\
& = x \cdot w_1 \cdot w_2 \\
y & = softmax(y)
\end{align}
\]
code (training only)
y = a \cdot w_2
\]
w1 = tf.Variable(tf.random_normal([4,5], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([5,3], stddev=1, seed=1))
x = tf.placeholder(tf.float32, shape=(None, 4), name='x-input')
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
既然是有监督学习,那就在训练阶段必须要给出 label,以此来计算交叉熵
# 用来存储数据的标签
y_ = tf.placeholder(tf.float32, shape=(None, 3), name='y-input')
隐藏层的激活函数是 sigmoid
y = tf.sigmoid(y)
softmax 与 交叉熵(corss entropy) 的组合函数,损失函数是交叉熵的均值
# softmax & corss_entropy
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=y_, logits=y)
# mean
cross_entropy_mean = tf.reduce_mean(cross_entropy)
为了防止神经网络过拟合,需加入正则化项,一般选取 “L2 正则化”
loss = cross_entropy_mean + \
tf.contrib.layers.l2_regularizer(regulation_lamda)(w1) + \
tf.contrib.layers.l2_regularizer(regulation_lamda)(w2)
为了加速神经网络的训练过程,需加入“指数衰减”技术
表示训练过程的计算图,优化方法选择了 Adam 算法,本质是反向传播算法。还可以选择“梯度下降法”(GradientDescentOptimizer)
train_step = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
训练阶段
with tf.Session() as sess: # Session 最好在“上下文机制”中开启,以防资源泄露
init_op = tf.global_variables_initializer() # 初始化网络中节点的参数,主要是 w1,w2
sess.run(init_op)
steps = 10000
for i in range(steps):
beg = (i * batch_size) % dataset_size # 计算 batch
end = min(beg+batch_size, dataset_size) # 计算 batch
sess.run(train_step, feed_dict={x:X[beg:end], y_:Y[beg:end]}) # 反向传播,训练网络
if i % 1000 == 0:
total_corss_entropy = sess.run( # 计算交叉熵
cross_entropy_mean, # 计算交叉熵
feed_dict={x:X, y_:Y} # 计算交叉熵
)
print("After %d training steps, cross entropy on all data is %g" % (i, total_corss_entropy))
在训练阶段中,需要引入“滑动平均模型”来提高模型在测试数据上的健壮性(这是书上的说法,而我认为是泛化能力)
全部代码
# -*- encoding=utf8 -*-
from sklearn.datasets import load_iris
import tensorflow as tf
def label_convert(Y):
l = list()
for y in Y:
if y == 0:
l.append([1,0,0])
elif y == 1:
l.append([0, 1, 0])
elif y == 2:
l.append([0, 0, 1])
return l
def load_data():
iris = load_iris()
X = iris.data
Y = label_convert(iris.target)
return (X,Y)
if __name__ == '__main__':
X,Y = load_data()
learning_rate = 0.001
batch_size = 10
dataset_size = 150
regulation_lamda = 0.001
w1 = tf.Variable(tf.random_normal([4,5], stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal([5,3], stddev=1, seed=1))
x = tf.placeholder(tf.float32, shape=(None, 4), name='x-input')
y_ = tf.placeholder(tf.float32, shape=(None, 3), name='y-input')
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
y = tf.sigmoid(y)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=y_, logits=y)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + \
tf.contrib.layers.l2_regularizer(regulation_lamda)(w1) + \
tf.contrib.layers.l2_regularizer(regulation_lamda)(w2)
train_step = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
steps = 10000
for i in range(steps):
beg = (i * batch_size) % dataset_size
end = min(beg+batch_size, dataset_size)
sess.run(train_step, feed_dict={x:X[beg:end], y_:Y[beg:end]})
if i % 1000 == 0:
total_corss_entropy = sess.run(
cross_entropy_mean,
feed_dict={x:X, y_:Y}
)
print("After %d training steps, cross entropy on all data is %g" % (i, total_corss_entropy))
print(sess.run(w1))
print(sess.run(w2))
Experiment Result
random split cross validation
Iris Classification on Tensorflow的更多相关文章
- Iris Classification on Keras
Iris Classification on Keras Installation Python3 版本为 3.6.4 : : Anaconda conda install tensorflow==1 ...
- Implementing a CNN for Text Classification in TensorFlow
参考: 1.Understanding Convolutional Neural Networks for NLP 2.Implementing a CNN for Text Classificati ...
- [转] Implementing a CNN for Text Classification in TensorFlow
Github上的一个开源项目,文档讲得极清晰 Github - https://github.com/dennybritz/cnn-text-classification-tf 原文- http:// ...
- Iris Classification on PyTorch
Iris Classification on PyTorch code # -*- coding:utf8 -*- from sklearn.datasets import load_iris fro ...
- CNN tensorflow text classification CNN文本分类的例子
from:http://deeplearning.lipingyang.org/tensorflow-examples-text/ TensorFlow examples (text-based) T ...
- python tensorflow model
step01_formula # -*- coding: utf-8 -*- """ 단순 선형회귀방정식 : x(1) -> y - y = a*X + b (a ...
- Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
用卷积神经网络基于 Tensorflow 实现的中文文本分类 项目地址: https://github.com/fendouai/Chinese-Text-Classification 欢迎提问:ht ...
- TensorFlow 中文资源全集,官方网站,安装教程,入门教程,实战项目,学习路径。
Awesome-TensorFlow-Chinese TensorFlow 中文资源全集,学习路径推荐: 官方网站,初步了解. 安装教程,安装之后跑起来. 入门教程,简单的模型学习和运行. 实战项目, ...
- 在 TensorFlow 中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
随机推荐
- NodeJs--HTTP源码分析
在github上按下按键t,就可以呼出仓库搜索的面板(在大型项目中方便检索文件),检索出http.js文件检索出来,通过ctrl+F来搜索某个方法. _http_outgoing 带下划线的是私有模块 ...
- selenium元素单击不稳定解决方法
selenium自动化测试过程中,经常会发现某一元素单击,很不稳定,有时候执行了点击没有反映. 以下总结两种解决方法:都是通过js注入的方式去点击. 1.F12查一看,要点击的按钮,或连接,有没有on ...
- 笔记 : 将本地项目上传到GitHub
一.准备工作 1. 注册github账号https://github.com, 安装git工具 https://git-for-windows.github.io/ 2. 创建SSH KEY(由于本地 ...
- 第四章 CSS3概述
1.CSS3新增常用选择器(1)结构性伪类选择器:root 文档根元素 :nth-child(n) 第N个子元素"first-child 第一个元素 :kast-child 最后一个子元素 ...
- python拼接变量、字符串的3种方法
第一种,加号(“+”): print 'py'+'thon' # output python str = 'py' print str+'thon' # output python 第二种 ,空格: ...
- c#Stream学习笔记
C# 温故而知新:Stream篇(—) http://www.cnblogs.com/JimmyZheng/archive/2012/03/17/2402814.html 基本概念重点看这一篇. 什么 ...
- dp入门 石子相邻合并 详细带图讲解
题目: 有N堆石子,现要将石子有序的合并成一堆,规定如下: 1.每次只能移动相邻的2堆石子合并 2.合并花费为新合成的一堆石子的数量. 求将这N堆石子合并成一堆的总花费最小(或最大). 样例: 输入 ...
- 大数据处理框架之Strom:容错机制
1.集群节点宕机Nimbus服务器 单点故障,大部分时间是闲置的,在supervisor挂掉时会影响,所以宕机影响不大,重启即可非Nimbus服务器 故障时,该节点上所有Task任务都会超时,Nimb ...
- OS Tools-GO富集分析工具的使用与解读详细教程
我们的云平台上的GO富集分析工具,需要输入的文件表格和参数很简单,但很多同学都不明白其中的原理与结果解读,这个帖子就跟大家详细解释~ 一.GO富集介绍: Gene Ontology(简称G ...
- 常用bash,autoUserAdd.sh
#!/bin/bash # auth: xiluhua # date: -- read -p "please input a username:" username [ -z $u ...