LRN(local response normalization--局部响应标准化)
LRN全称为Local Response Normalization,即局部响应归一化层,LRN函数类似DROPOUT和数据增强作为relu激励之后防止数据过拟合而提出的一种处理方法。这个函数很少使用,基本上被类似DROPOUT这样的方法取代,见最早的出处AlexNet论文对它的定义, 《ImageNet Classification with Deep ConvolutionalNeural Networks》
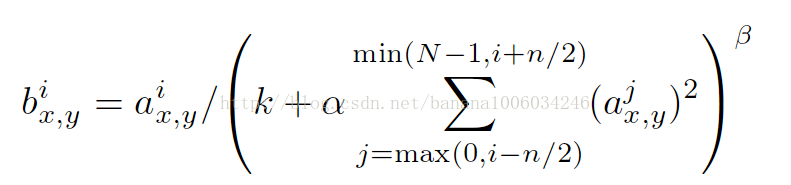
i:代表下标,你要计算像素值的下标,从0计算起
j:平方累加索引,代表从j~i的像素值平方求和
x,y:像素的位置,公式中用不到
a:代表feature map里面的 i 对应像素的具体值
N:每个feature map里面最内层向量的列数
k:超参数,由原型中的blas指定
α:超参数,由原型中的alpha指定
n/2:超参数,由原型中的deepth_radius指定
β:超参数,由原型中的belta指定
背景知识:
tensorflow官方文档中的tf.nn.lrn函数给出了局部响应归一化的论文出处 ,详见http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
为什么要有局部响应归一化(Local Response Normalization)?详见http://blog.csdn.net/hduxiejun/article/details/70570086
tensorflow中调用:
看一个栗子,理解上诉的参数,进而理解rln函数
import tensorflow as tf a = tf.constant([
[[1.0, 2.0, 3.0, 4.0],
[5.0, 6.0, 7.0, 8.0],
[8.0, 7.0, 6.0, 5.0],
[4.0, 3.0, 2.0, 1.0]],
[[4.0, 3.0, 2.0, 1.0],
[8.0, 7.0, 6.0, 5.0],
[1.0, 2.0, 3.0, 4.0],
[5.0, 6.0, 7.0, 8.0]]
])
#reshape 1批次 2x2x8的feature map
a = tf.reshape(a, [1, 2, 2, 8]) normal_a=tf.nn.lrn(a,2,0,1,1)
with tf.Session() as sess:
print("feature map:")
image = sess.run(a)
print (image)
print("normalized feature map:")
normal = sess.run(normal_a)
print (normal)
你将得到输出:
feature map:
[[[[ 1. 2. 3. 4. 5. 6. 7. 8.]
[ 8. 7. 6. 5. 4. 3. 2. 1.]] [[ 4. 3. 2. 1. 8. 7. 6. 5.]
[ 1. 2. 3. 4. 5. 6. 7. 8.]]]]
normalized feature map:
[[[[ 0.07142857 0.06666667 0.05454545 0.04444445 0.03703704 0.03157895
0.04022989 0.05369128]
[ 0.05369128 0.04022989 0.03157895 0.03703704 0.04444445 0.05454545
0.06666667 0.07142857]] [[ 0.13793103 0.10000001 0.0212766 0.00787402 0.05194805 0.04
0.03448276 0.04545454]
[ 0.07142857 0.06666667 0.05454545 0.04444445 0.03703704 0.03157895
0.04022989 0.05369128]]]]
分析如下:
由调用关系得出 n/2=2,k=0,α=1,β=1,N=8
第一行第一个数来说:i = 0
a = 1,min(N-1, i+n/2) = min(7, 2)=2,j = max(0, i - k)=max(0, 0)=0,下标从0~2个数平方求和, b=1/(1^2 + 2^2 + 3^2)=1/14 = 0.071428571
同理,第一行第四个数来说:i = 3
a = 4,min(N-1, i+n/2) = min(7, 5 )=5, j = max(0,1) = 1,下标从1~5进行平方求和,b = 4/(2^2 + 3^2 + 4^2 + 5^2 + 6^2) = 4/90=0.044444444
再来一个,第二行第一个数来说: i = 0
a = 8, min(N-1, i+n/2) = min(7, 2) = 2, j=max(0,0)=0, 下标从0~2的3个数平方求和,b = 8/(8^2 + 7^2 + 6^2)=8/149=0.053691275
其他的也是类似操作
ps:
1、AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
2、为什么输入数据需要归一化(Normalized Data)?
归一化后有什么好处呢?原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
对于深度网络的训练是一个复杂的过程,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。一旦网络某一层的输入数据的分布发生改变,那么这一层网络就需要去适应学习这个新的数据分布,所以如果训练过程中,训练数据的分布一直在发生变化,那么将会影响网络的训练速度。
参考文献:
https://blog.csdn.net/banana1006034246/article/details/75204013
https://blog.csdn.net/u011204487/article/details/76026537
https://blog.csdn.net/yangdashi888/article/details/77918311
LRN(local response normalization--局部响应标准化)的更多相关文章
- 局部响应归一化(Local Response Normalization,LRN)
版权声明:本文为博主原创文章,欢迎转载,注明地址. https://blog.csdn.net/program_developer/article/details/79430119 一.LRN技术介 ...
- Local Response Normalization作用——对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中.AlexNet主要使用到的新技术点如下. (1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过 ...
- caffe中的Local Response Normalization (LRN)有什么用,和激活函数区别
http://stats.stackexchange.com/questions/145768/importance-of-local-response-normalization-in-cnn ca ...
- Local Response Normalization 60 million parameters and 500,000 neurons
CNN是工具,在图像识别中是发现图像中待识别对象的特征的工具,是剔除对识别结果无用信息的工具. ImageNet Classification with Deep Convolutional Neur ...
- 在AlexNet中LRN 局部响应归一化的理
在AlexNet中LRN 局部响应归一化的理 一.LRN技术介绍: Local Response Normalization(LRN)技术主要是深度学习训练时的一种提高准确度的技术方法.其中caffe ...
- 深度学习原理与框架-Tensorflow卷积神经网络-cifar10图片分类(代码) 1.tf.nn.lrn(局部响应归一化操作) 2.random.sample(在列表中随机选值) 3.tf.one_hot(对标签进行one_hot编码)
1.tf.nn.lrn(pool_h1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75) # 局部响应归一化,使用相同位置的前后的filter进行响应归一化操作 参数 ...
- Response.Write()方法响应导致页面字体变大的解决办法
关于ASP.NET中用Response.Write()方法响应导致页面字体变大的解决办法 最近研究了ASP.NET,发现一个问题,比方说在页面里面有个Button,要点击以后要打开新窗口,而且 ...
- Response Assertion(响应断言)
Response Assertion(响应断言) 响应断言是对服务器的响应数据进行规则匹配. Name(名称):可以随意设置,最好有业务意义. Comments(注释):可以随意设置,可以为空. Ap ...
- NIO开发Http服务器(4):Response封装和响应
最近学习了Java NIO技术,觉得不能再去写一些Hello World的学习demo了,而且也不想再像学习IO时那样编写一个控制台(或者带界面)聊天室.我们是做WEB开发的,整天围着tomcat.n ...
随机推荐
- Eloquent JavaScript #13# HTTP and Forms
索引 Notes fetch form focus Disabled fields form’s elements property 阻止提交 快速插入单词 实时统计字数 监听checkbox和rad ...
- org.I0Itec.zkclient.exception.ZkTimeoutException: Unable to connect to zookeeper server within
org.I0Itec.zkclient.exception.ZkTimeoutException: Unable to connect to zookeeper server within timeo ...
- Python For Android (P4a):添加权限(Permissions)
from flutter study: <uses-permission android:name="android.permission.INTERNET"/>< ...
- nginx 启动 + uwsgi + django
https://www.cnblogs.com/chenice/p/6921727.html https://blog.csdn.net/Aaroun/article/details/78218131
- hihocoder [Offer收割]编程练习赛8
第一次做这种比赛,被自己坑的好惨... A.这道题的关键其实是如果有k和n满足kD+F>nL>kD则不能走无限远,分支看似难整理,其实比较简单,F>L根本就不用算了,明摆着就是Bsi ...
- NATS—发布/订阅机制
概念 发布/订阅(Publish/subscribe 或pub/sub)是一种消息范式,消息的发送者(发布者)不是计划发送其消息给特定的接收者(订阅者).而是发布的消息分为不同的类别,而不需要知道什么 ...
- mysql优化之使用iotop+pt-ioprofile定位具体top io文件
今天,将一个环境切换成行情优化后的版本后,发现io等待还是挺高,这还是第一次出现的.其他很多套环境都没有这个问题了,故iotop看了下,基本可以确定为是mysql进程的问题,如下: 但是iotop只能 ...
- k8s build new API
apiserver-builder git hub api conventions storage api arch step by step, we can follow it. api con ...
- linux --- 4. 虚拟环境
一.虚拟环境的两种安装方式 1. virtualenv 虚拟环境 ①下载 virtualenv pip3 install -i https://pypi.tuna.tsinghua.edu.cn/s ...
- Shell 基础知识和总结
调试脚本 检查脚本语法错误 bash -n /path/to/some_script 调试执行 bash -x /path/to/some_script shell里的变量 本地变量:只对当前shel ...