python学习之struct模块
class struct.Struct(format)
返回一个struct对象(结构体,参考C)。
该对象可以根据格式化字符串的格式来读写二进制数据。
第一个参数(格式化字符串)可以指定字节的顺序。
默认是根据系统来确定,也提供自定义的方式,只需要在前面加上特定字符即可:
struct.Struct('>I4sf')
特定字符对照表附件有。
常见方法和属性:
方法
pack(v1, v2, …)返回一个字节流对象。
按照fmt(格式化字符串)的格式来打包参数v1,v2,...。
通俗的说就是:
首先将不同类型的数据对象放在一个“组”中(比如元组(1,'good',1.22)),
然后打包(“组”转换为字节流对象),最后再解包(将字节流对象转换为“组”)。
pack_into(buffer, offset, v1, v2, …)
根据格式字符串fmt包装值v1,v2,...,并将打包的字节写入从位置偏移开始的可写缓冲buffer。 请注意,offset是必需的参数。
unpack_from(buffer, offset=)
根据格式字符串fmt,从位置偏移开始从缓冲区解包。 结果是一个元组,即使它只包含一个项目。 缓冲区的大小(以字节为单位,减去偏移量)必须至少为格式所需的大小,如calcsize()所反映的。
属性
format
格式化字符串。
size
结构体的大小。
实例:
1.通常的打包和解包
# -*- coding: utf-8 -*-
"""
打包和解包
"""
import struct
import binascii values = (1, b'good', 1.22) #查看格式化对照表可知,字符串必须为字节流类型。
s = struct.Struct('I4sf')
packed_data = s.pack(*values)
unpacked_data = s.unpack(packed_data) print('Original values:', values)
print('Format string :', s.format)
print('Uses :', s.size, 'bytes')
print('Packed Value :', binascii.hexlify(packed_data))
print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data)
结果:
Original values: (, b'good', 1.22)
Format string : b'I4sf'
Uses : bytes
Packed Value : b'01000000676f6f64f6289c3f'
Unpacked Type : <class 'tuple'> Value: (, b'good', 1.2200000286102295)
[Finished in .1s]
说明:
首先将数据对象放在了一个元组中,然后创建一个Struct对象,并使用pack()方法打包该元组;最后解包返回该元组。
这里使用到了binascii.hexlify(data)函数。
binascii.hexlify(data)
返回字节流的十六进制字节流。
>>> a = 'hello'
>>> b = a.encode()
>>> b
b'hello'
>>> c = binascii.hexlify(b)
>>> c
b'68656c6c6f'
2.使用buffer来进行打包和解包
使用通常的方式来打包和解包会造成内存的浪费,所以python提供了buffer的方式:
# -*- coding: utf-8 -*-
"""
通过buffer方式打包和解包
"""
import struct
import binascii
import ctypes values = (1, b'good', 1.22) #查看格式化字符串可知,字符串必须为字节流类型。
s = struct.Struct('I4sf')
buff = ctypes.create_string_buffer(s.size)
packed_data = s.pack_into(buff,0,*values)
unpacked_data = s.unpack_from(buff,0) print('Original values:', values)
print('Format string :', s.format)
print('buff :', buff)
print('Packed Value :', binascii.hexlify(buff))
print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data)
结果:
Original values1: (1, b'good', 1.22)
Original values2: (b'hello', True)
buff : <ctypes.c_char_Array_18 object at 0x000000D5A5617348>
Packed Value : b'01000000676f6f64f6289c3f68656c6c6f01'
Unpacked Type : <class 'tuple'> Value: (1, b'good', 1.2200000286102295)
Unpacked Type : <class 'tuple'> Value: (b'hello', True)
[Finished in 0.1s]
说明:
针对buff对象进行打包和解包,避免了内存的浪费。
这里使用到了函数
ctypes.create_string_buffer(init_or_size,size = None)
创建可变字符缓冲区。
返回的对象是c_char的ctypes数组。
init_or_size必须是一个整数,它指定数组的大小,或者用于初始化数组项的字节对象。
3.使用buffer方式来打包多个对象
# -*- coding: utf-8 -*-
"""
buffer方式打包和解包多个对象
"""
import struct
import binascii
import ctypes values1 = (1, b'good', 1.22) #查看格式化字符串可知,字符串必须为字节流类型。
values2 = (b'hello',True)
s1 = struct.Struct('I4sf')
s2 = struct.Struct('5s?')
buff = ctypes.create_string_buffer(s1.size+s2.size)
packed_data_s1 = s1.pack_into(buff,0,*values1)
packed_data_s2 = s2.pack_into(buff,s1.size,*values2)
unpacked_data_s1 = s1.unpack_from(buff,0)
unpacked_data_s2 = s2.unpack_from(buff,s1.size) print('Original values1:', values1)
print('Original values2:', values2)
print('buff :', buff)
print('Packed Value :', binascii.hexlify(buff))
print('Unpacked Type :', type(unpacked_data_s1), ' Value:', unpacked_data_s1)
print('Unpacked Type :', type(unpacked_data_s2), ' Value:', unpacked_data_s2)
结果:
Original values2: (b'hello', True)
buff : <ctypes.c_char_Array_18 object at 0x000000D5A5617348>
Packed Value : b'01000000676f6f64f6289c3f68656c6c6f01'
Unpacked Type : <class 'tuple'> Value: (, b'good', 1.2200000286102295)
Unpacked Type : <class 'tuple'> Value: (b'hello', True)
[Finished in .1s]
附:
1.格式化对照表
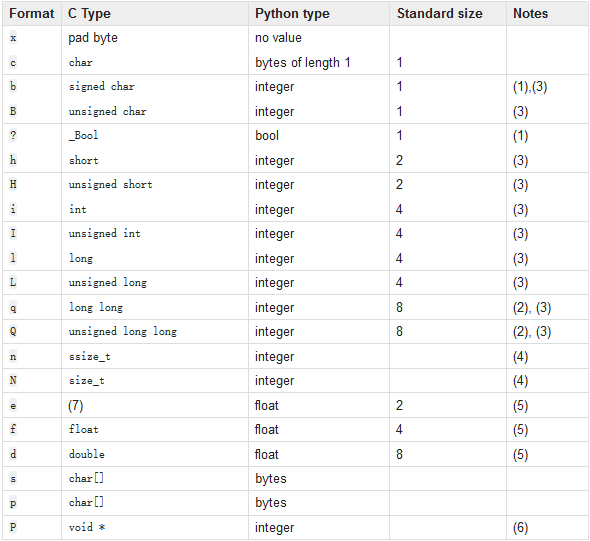
提示:
signed char(有符号位)取值范围是 -128 到 127(有符号位)
unsigned char (无符号位)取值范围是 0 到 255
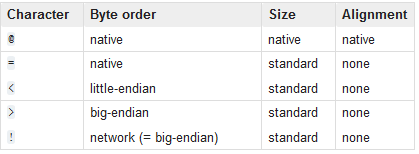
2.字节顺序,大小和校准
python学习之struct模块的更多相关文章
- 浅析Python中的struct模块
最近在学习python网络编程这一块,在写简单的socket通信代码时,遇到了struct这个模块的使用,当时不太清楚这到底有和作用,后来查阅了相关资料大概了解了,在这里做一下简单的总结. 了解c语言 ...
- 【转】浅析Python中的struct模块
[转]浅析Python中的struct模块 最近在学习python网络编程这一块,在写简单的socket通信代码时,遇到了struct这个模块的使用,当时不太清楚这到底有和作用,后来查阅了相关资料大概 ...
- Python学习 Part4:模块
Python学习 Part4:模块 1. 模块是将定义保存在一个文件中的方法,然后在脚本中或解释器的交互实例中使用.模块中的定义可以被导入到其他模块或者main模块. 模块就是一个包含Python定义 ...
- python学习之argparse模块
python学习之argparse模块 一.简介: argparse是python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块.argparse模块的作用是用于解析命令行 ...
- Python学习day19-常用模块之re模块
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- Python学习day18-常用模块之NumPy
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- python中的struct模块的学习
由于TCP协议中的黏包现象的发生,对于最low的办法,每次发送之前让他睡一秒,然后在发送,可是这样真的太low了,而且太占用资源了. 黏包现象只发生在tcp协议中: 1.从表面上看,黏包问题主要是因为 ...
- Python学习笔记-常用模块
1.python模块 如果你退出 Python 解释器并重新进入,你做的任何定义(变量和方法)都会丢失.因此,如果你想要编写一些更大的程序,为准备解释器输入使用一个文本编辑器会更好,并以那个文件替代作 ...
- python学习之random模块
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
随机推荐
- 001 LRU-缓存淘汰算法
1.介绍 LRU是LeastRecentlyUsed近期最少使用算法.内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,Oracle会根据哪些数据属于LRU而将其移出内存而 ...
- 052 自动将每日的日志增量导入到hive中
一:大纲介绍 1.导入方式 load data local inpath 'local_file_path' into table tbname partition (date='',hour='') ...
- 'utf-8' codec can't decode byte 0xc8 in position 0
今天学习python中使用jieba库,遇到了错误:“UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc8 in position 0: i ...
- Flutter常用组件(Widget)解析-Scaffold
实现一个应用基本的布局结构. 举个栗子: import 'package:flutter/material.dart'; void main() => runApp(MyApp()); clas ...
- golang实现分布式缓存笔记(一)基于http的缓存服务
目录 前言 cache 缓存服务接口 cache包实现 golang http包使用介绍 hello.go Redirect.go http-cache-server 实现 cacheHandler ...
- 前端解读面向切面编程(AOP)
前言 面向对象(OOP)作为经典的设计范式,对于我们来说可谓无人不知,还记得我们入行起始时那句经典的总结吗-万事万物皆对象. 是的,基于OOP思想封装.继承.多态的特点,我们会自然而然的遵循模块化.组 ...
- Java开发人员必须掌握的Linux命令(一)
子曰:"工欲善其事,必先利其器." 1.登录服务器SSH命令 简单说,SSH是一种网络协议,用于计算机之间的加密登录.如果一个用户从本地计算机,使用SSH协议登录另一台远程计算机, ...
- JDBC fetch size
make your java run faster A blog on java performance and optimization. On JDBC, Hibernate, caching, ...
- Windows 下安装 swoole 具体步骤(php)
Windows 下安装 swoole 具体步骤: Swoole,原本不支持在Windows下安装的,所以我们要安装Cygwin来使用.在安装Cygwin下遇到了很多坑,百度经验上的文档不是很全,所以我 ...
- loj#2012. 「SCOI2016」背单词
题目链接 loj#2012. 「SCOI2016」背单词 题解 题面描述有点不清楚. 考虑贪心 type1的花费一定不会是优的,不考虑, 所以先把后缀填进去,对于反串建trie树, 先填父亲再填儿子, ...