python爬虫——urllib使用代理
收到粉丝私信说urllib库的教程还没写,好吧,urllib是python自带的库,没requests用着方便。本来嘛,python之禅(import this自己看)就说过,精简,效率,方便也是大家的追求。不过大家有要求,那就写一篇关于urllib的基础教程。
本文中的知识点:
- get请求
- 使用代理
- post请求
安装
urllib是python自带的,不用安装,直接import进来即可
代码样例
注意这里需要先定义opener,在打开我们要发送的request请求。返回的字符串编码用utf-8处理
import urllib.request
from urllib.parse import urlencode
opener = urllib.request.build_opener()
# 发送request请求
req = urllib.request.Request('https://www.baidu.com/')
res = opener.open(req)
# 打印response code
print(res.status)
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))
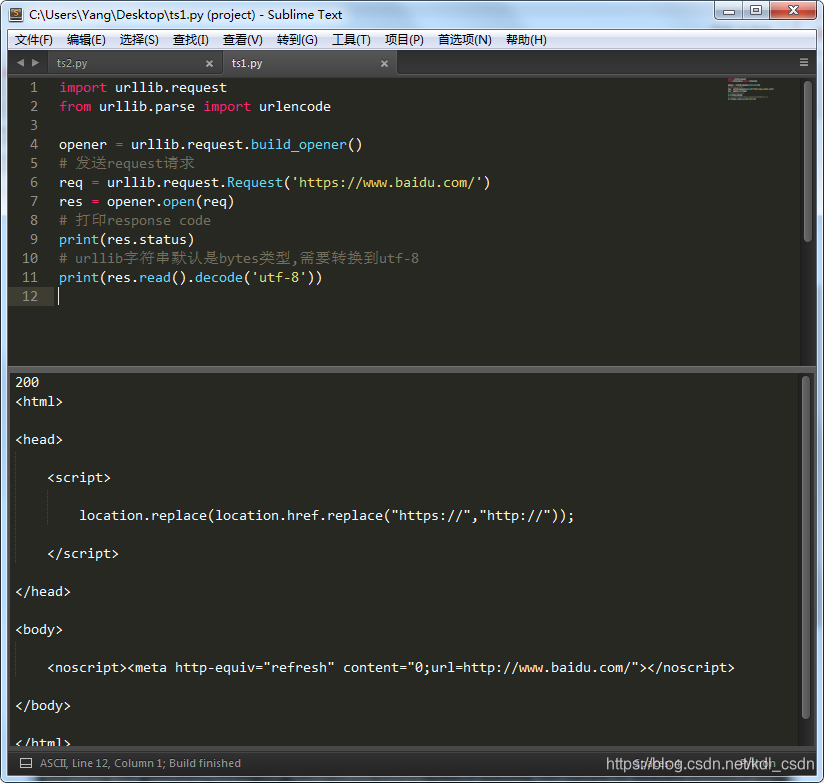
运行下,结果如下图
使用代理
注意还是要模拟用户请求,加上header参数
import urllib.request
from urllib.parse import urlencode
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# 代理IP,由快代理提供
proxy = '124.94.203.122:20993'
proxy_values = "%(ip)s" % {'ip': proxy}
proxies = {"http": proxy_values, "https": proxy_values}
# 设置代理
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
# 发送request请求
req = urllib.request.Request('https://www.baidu.com/s?ie=UTF-8&wd=ip', headers=headers)
res = opener.open(req)
# 打印response code
print(res.status)
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))
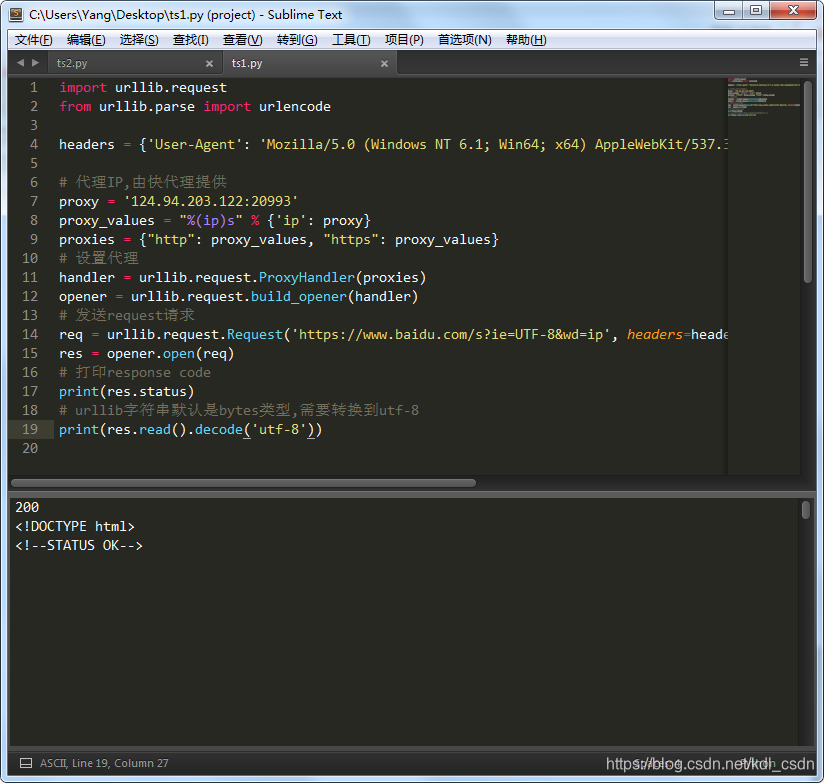
运行下,结果如下。正常打开了这个网页
 ***
***
POST请求
上述的默认使用的是get请求,那要使用post加一个method参数即可。
注意method参数POST是大写,因为我的urllib源码提示得大写。不过有的同学小写也可以,大家可以自己试下。
import urllib.request
from urllib.parse import urlencode
page_url = 'https://dev.kdlapi.com/testproxy/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# 代理IP,由快代理提供
proxy = '115.203.13.59:21216'
proxy_values = "%(ip)s" % {'ip': proxy}
proxies = {"http": proxy_values, "https": proxy_values}
# 设置代理
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
# 发送request post请求
data = bytes(urlencode({"info": "send post request"}), encoding="utf-8")
req = urllib.request.Request(url=page_url, headers=headers, data=data, method="POST")
res = opener.open(req)
# 打印response code
print(res.status)
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))
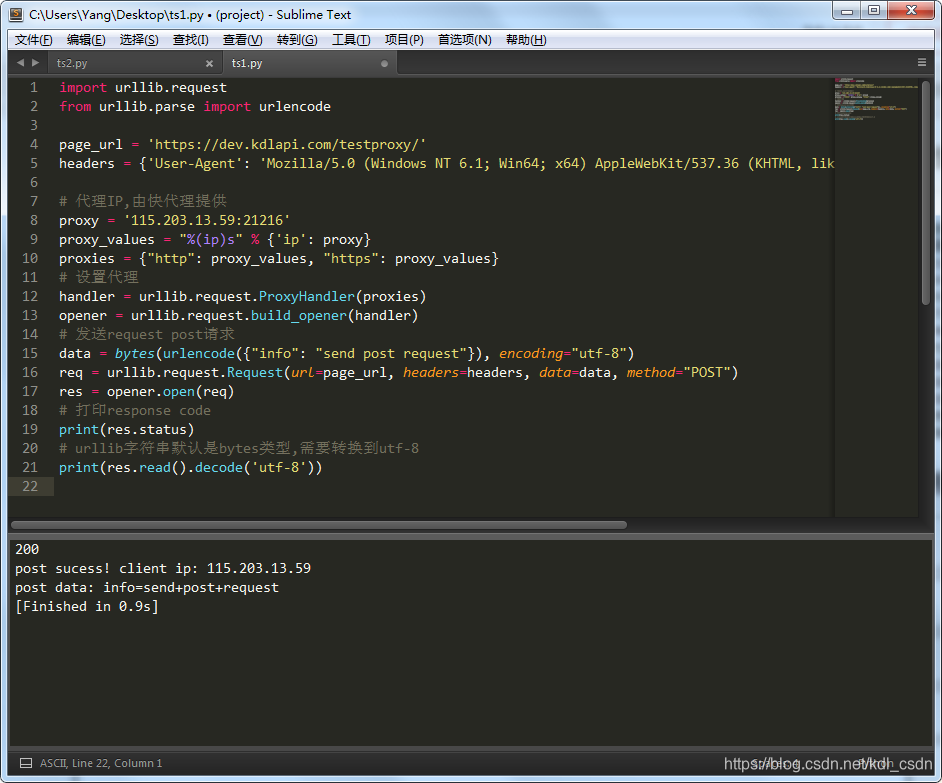
运行下试试,post成功,如图
进阶学习:
- urllib库,自己看下帮助文档或者源码吧。。。(滑稽)
- 代理IP的使用
python爬虫——urllib使用代理的更多相关文章
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
- python爬虫 urllib模块url编码处理
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) import urllib.request # 1.指定url url = 'https://www.sogou. ...
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- python爬虫 - Urllib库及cookie的使用
http://blog.csdn.net/pipisorry/article/details/47905781 lz提示一点,python3中urllib包括了py2中的urllib+urllib2. ...
- Python 爬虫 --- urllib
对于互联网数据,Python 有很多处理网络协议的工具,urllib 是很常用的一种. 一.urllib.request,request 可以很方便的抓取 URL 内容. urllib.request ...
- Python爬虫urllib模块
Python爬虫练习(urllib模块) 关注公众号"轻松学编程"了解更多. 1.获取百度首页数据 流程:a.设置请求地址 b.设置请求时间 c.获取响应(对响应进行解码) ''' ...
- python爬虫-urllib模块
urllib 模块是一个高级的 web 交流库,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如:HTTP.FTP.Gophe ...
随机推荐
- Codeforces Round #564 (Div. 2)
传送门 参考资料 [1]: the Chinese Editoria A. Nauuo and Votes •题意 x个人投赞同票,y人投反对票,z人不确定: 这 z 个人由你来决定是投赞同票还是反对 ...
- P1034 台阶问题一
题目描述 有 \(N\) 级的台阶,你一开始在底部,每次可以向上迈最多2级台阶(最少1级),问到达第 \(N\) 级台阶有多少种不同方式. 输入格式 一个正整数 \(N(\le 20)\) . 输出格 ...
- linux进程唤醒的细节
我们已展现的唤醒进程的样子比内核中真正发生的要简单. 当进程被唤醒时产生的真正动 作是被位于等待队列入口项的一个函数控制的. 缺省的唤醒函数[22]22设置进程为可运行的 状态, 并且可能地进行一个上 ...
- linux 安装一个中断处理
如果你想实际地"看到"产生的中断, 向硬件设备写不足够; 一个软件处理必须在系统中配 置. 如果 Linux 内核还没有被告知来期待你的中断, 它简单地确认并忽略它. 中断线是一个 ...
- 2018百度之星初赛B - A,D,F
总结:这一次的百度之星之行到这里也就结束了,充分的认识到了自己的不足啊...果然还是做的题太少,,见识的题型也还太少,对于STL的掌握还是不够到位啊!!(STL大法是真的好,建议大家认认真真的好好学学 ...
- 51nod 1287加农炮
1287 加农炮 题目来源: Codility 基准时间限制:1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题 一个长度为M的正整数数组A,表示从左向右的地形高度.测试一种加农炮 ...
- 009 Ceph RBD增量备份与恢复
一.RBD的导入导出介绍 Ceph存储可以利用快照做数据恢复,但是快照依赖于底层的存储系统没有被破坏 可以利用rbd的导入导出功能将快照导出备份 RBD导出功能可以基于快照实现增量导出 二.RBD导出 ...
- 曹工杂谈--使用mybatis的同学,进来看看怎么在日志打印完整sql吧,在数据库可执行那种
前言 今天新年第一天,给大家拜个年,祝大家新的一年里,技术突突突,头发长长长! 咱们搞技术的,比较直接,那就开始吧.我给大家看看我demo工程的效果(代码下边会给大家的): 技术栈是mybatis/m ...
- no supported authentication methods avaiable
在git(小乌龟)向github远程推送(push)文件是会报一个异常 no supported authentication methods avaiable 解决方法:因为git(小乌龟)和Git ...
- 斜率优化入门题题单$QwQ$
其实就是这一篇的那个例题帕的大部分题目的题解就写这儿辣,,, 因为都是些基础题不想专门给写题解,,,但是又掌握得差不得不写,,, 麻油办法就写一块儿好辣$QwQ$ 当然辣比较难的我就没放进来辣$QwQ ...