小白学 Python 爬虫(30):代理基础

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
小白学 Python 爬虫(26):为啥买不起上海二手房你都买不起
小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
引言
我们在使用爬虫的时候,经常遇到一种情况,刚开始的运行的时候,都如丝般顺滑,可能一杯茶的功夫,就完犊子了,可能会出现各种各样的限制,比如 403 Forbidden 、 429 Too Many Request 等等。
这时候,很有可能就是我们的 IP 被限制了。
出现以上问题一般是因为网站的安全限制或者是机房的安全限制,有时候实在服务器上做检测,有时候是在网关处做检测,一旦发现某个 IP 在单位时间内的访问次数超过了当前限定的某个阀值,就会直接拒绝服务,这种情况我们统称为:封 IP 。
对于上面这种情况难道我们就这么认了么,当然不!
代理就是为了解决这个问题的。
代理解决上面这个问题的方式就是请求中间增加的代理服务器做转发,本来请求是由 A 直接访问到服务器 C 的,如: A -> C ,加了代理 B 之后就变成了这个样子: A -> B -> C 。
代理的获取
在做实战之前,我们先了解下如何获取代理。
首先在百度上输入 “代理” 两个字进行查询,可以看到有很多提供代理服务的网站,当然哈,大多数都是收费的。但是其中不乏会有一部分免费的代理。
当然免费的代理会有各种各样的坑,比如经常性连不通,比如网络延迟非常高等等等等。
但是,人家免费啊,还要啥自行车。
当然如果想要获得稳定的、网络延时低的代理服务,建议付费使用,毕竟用的少也花不了多少钞票。
代理的站点小编就不列举了,是在太多,我们随便打开一个免费代理的网站:
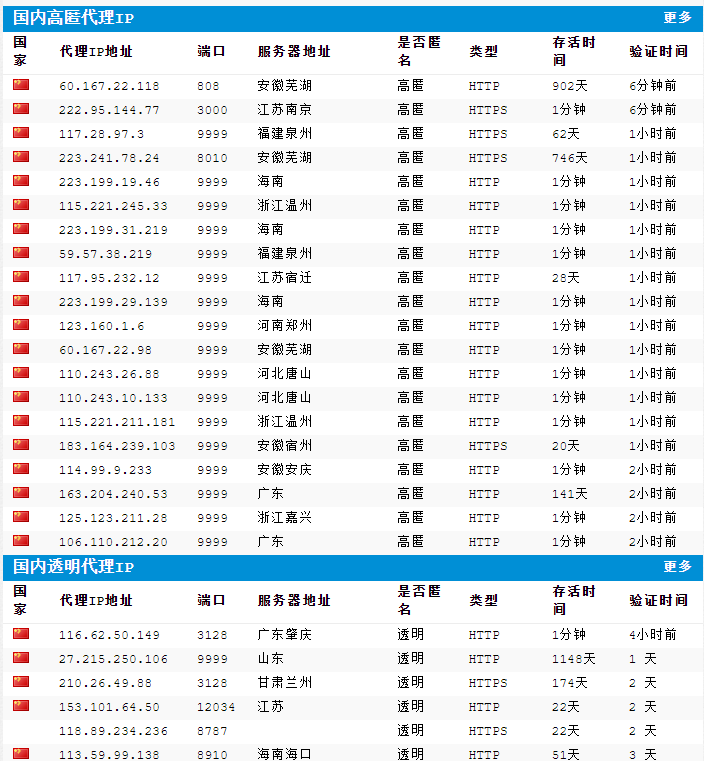
可以发现,代理好像分两种,一种是高匿代理,还有一种是透明代理,这两个有什么区别呢?
其实,除了高匿代理和透明代理以外,还有一种中间形态叫做匿名代理。
这几种代理之间的区别在于转发请求的头部参数不同。
透明代理
目标服务器可以知道我们使用了代理,并且也知道我们的真实 IP 。 透明代理访问目标服务器所带的 HTTP 头信息如下:
- REMOTE_ADDR = 代理服务器IP
- HTTP_VIA = 代理服务器IP
- HTTP_X_FORWARDED_FOR = 我们的真实IP
透明代理还是将我们的真实IP发送给了对方服务器,因此无法达到隐藏身份的目的。
匿名代理
目标服务器可以知道我们使用了代理,但不知道我们的真实 IP 。匿名代理访问目标服务器所带的 HTTP 头信息如下:
- REMOTE_ADDR = 代理服务器IP
- HTTP_VIA = 代理服务器IP
- HTTP_X_FORWARDED_FOR = 代理服务器IP
匿名代理隐藏了我们的真实IP,但是向目标服务器透露了我们是使用代理服务器访问他们的。
高匿代理
目标服务器不知道我们使用了代理,更不知道我们的真实 IP 。高匿代理访问目标服务器所带的 HTTP 头信息如下:
- REMOTE_ADDR = 代理服务器IP
- HTTP_VIA 不显示
- HTTP_X_FORWARDED_FOR 不显示
高匿代理隐藏了我们的真实 IP ,同时目标服务器也不知道我们使用了代理,因此隐蔽度最高。
可以看到,处于中间态的匿名代理,事情做了一半没做完,反而是没什么用武之地的。
代理设置
上面我们看到了一些代理服务,接下来我们看一下各种 HTTP 请求库设置代理的方式:
urllib
我们先使用 urllib 来做测试,测试的链接就选择:https://httpbin.org/get 这个我们之前用过的测试链接,访问该站点可以得到请求的一些相关信息,其中 origin 字段就是请求来源的 IP,我们可以根据它来判断代理是否设置成功,也就是是否成功伪装了 IP ,代理嘛小编就在网上随便找了个免费的高匿代理,示例如下:
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
proxy_handler = ProxyHandler({
'http': 'http://182.34.37.0:9999',
'https': 'https://117.69.150.84:9999'
})
opener = build_opener(proxy_handler)
try:
response = opener.open('https://httpbin.org/get')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)
代码很简单,我们看下执行结果:
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.7"
},
"origin": "117.69.150.84, 117.69.150.84",
"url": "https://httpbin.org/get"
}
可以看到,目标服务器已经认为我们是由代理访问的了, origin 参数显示的是我们的代理服务器的 IP 。
注意: 这里我们使用了 ProxyHandler 来进行代理设置,ProxyHandler 的参数类型是字典类型, key 是我们使用的协议,而值是我们具体所使用的代理,小编这里设置了两个代理,一个是 http 的还有一个是 https 的,当我们请求的链接是 http 的会自动的选择我们的 http 的代理,当我们的请求的链接是 https 的时候则会自动的选择我们设置的 https 的代理。
Requests
对于 Requests 来讲,代理的设置更加的简单加直白。示例代码如下:
import requests
proxies = {
'http': 'http://59.52.186.117:9999',
'https': 'https://222.95.241.6:3000',
}
try:
response = requests.get('https://httpbin.org/get', proxies = proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)
结果如下:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0"
},
"origin": "222.95.241.6, 222.95.241.6",
"url": "https://httpbin.org/get"
}
小编这里选择的还是高匿代理,所以这里显示出来的 IP 还是我们代理的 IP 。
Selenium
Selenium 同样可以设置代理,同时也非常简单,示例如下:
from selenium import webdriver
proxy = '222.95.241.6:3000'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=https://' + proxy)
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get('https://httpbin.org/get')
结果如下:
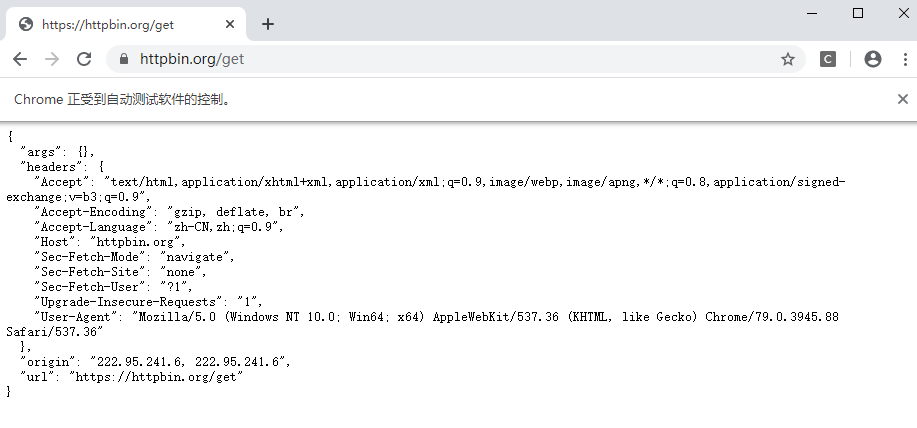
设置 FireFox 浏览器和设置 Chrome 浏览器近乎一样,唯一的区别就是在初始化的时候初始化一个 FireFox ,并且在这是启动参数的是时候使用 FirefoxOptions() 方法,其他的无任何区别,同学们可以自己尝试下。
免费代理
因为免费代理的连通率和稳定性确实不高,小编这里找了几个免费代理的网站,仅供大家参考使用:
https://www.kuaidaili.com/free/
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
参考
https://www.jianshu.com/p/bb00a288ee5f
小白学 Python 爬虫(30):代理基础的更多相关文章
- 小白学 Python 爬虫(31):自己构建一个简单的代理池
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- HZOJ 连连看
考场几乎想到了正解,然而我也不知道当时在想啥,在没有证伪的情况下只是觉得无法实现就否了…… 最后打的好象是达哥说的O(4*15*n*m),复杂度不是很会证反正T成了暴力…… 题解: 对于测试点8,9, ...
- qt 自定义窗口显示鼠标划过的轨迹
鼠标事件分为四种: 1.按下 2.抬起 3.移动 4.双击 鼠标事件继承与QWidget void mouseDoubleClickEvent(QMouseEvent *event) void mou ...
- 阿里云POLARDB如何助力轻松筹打造5亿用户信赖的大病筹款平台?
轻松筹首创了“大病救助”模式,帮助了众多病患在第一时间解決了医疗资金等问题,为了从源头解决了医疗资金问题.而在轻松筹这样全球5.5亿用户信赖的大病筹款平台的背后,是日益增长的各种数据.面对这样数据量所 ...
- 解决大数据难题 阿里云MaxCompute获科技大奖
摘要: 据介绍,MaxCompute(大规模分布式的数据计算平台)是国内最早自研的大数据计算平台之一,主要应用于大规模数据处理场景.目前,这项源自浙江.解决世界级难题的成果已拥有EB(百京)级别的数据 ...
- laravel多表登录出现路由调用错误
public function auth() { // Authentication Routes... $this->get('login', 'Auth\LoginController@sh ...
- Python os.getcwd() 方法
Python os.getcwd() 方法 Python OS 文件/目录方法 概述 os.getcwd() 方法用于返回当前工作目录. 语法 getcwd()方法语法格式如下: os.getcwd ...
- TP5 在模板读出Session值
模板取值: <p class="info">后台登录中心{$Request.session.username}</p> 也可以 {$Think.sessio ...
- [转]Jquery属性选择器(同时匹配多个条件,与或非)(附样例)
1. 前言 为了处理除了两项不符合条件外的选择,需要用到jquery选择器的多个条件匹配来处理,然后整理了一下相关的与或非的条件及其组合. 作为笔记记录. 2. 代码 1 2 3 4 5 6 7 8 ...
- PHP IF判断 简写
第一种:IF 条件语句 第二种:三元运算 第三种:&& .|| 组成的条件语句 第一种: IF 基础,相信绝大多数人都会: 第二种: c=a>b ? true:false / ...
- SpringSide 3 中的安全框架
在SpringSide 3的官方文档中,说安全框架使用的是Spring Security 2.0.乍一看,吓了我一跳,以为Acegi这么快就被淘汰了呢.上搜索引擎一搜,发现原来Spring Secur ...