Auto-scaling scikit-learn with Apache Spark
来源:https://databricks.com/blog/2016/02/08/auto-scaling-scikit-learn-with-apache-spark.html
Data scientists often spend hours or days tuning models to get the highest accuracy. This tuning typically involves running a large number of independent Machine Learning (ML) tasks coded in Python or R. Following some work presented at Spark Summit Europe 2015, we are excited to release scikit-learn integration package for Apache Spark that dramatically simplifies the life of data scientists using Python. This package automatically distributes the most repetitive tasks of model tuning on a Spark cluster, without impacting the workflow of data scientists:
- When used on a single machine, Spark can be used as a substitute to the default multithreading framework used by scikit-learn (Joblib).
- If a need comes to spread the work across multiple machines, no change is required in the code between the single-machine case and the cluster case.
Scale data science effortlessly
Python is one of the most popular programming languages for data exploration and data science, and this is in no small part due to high quality libraries such as Pandas for data exploration or scikit-learn for machine learning. Scikit-learn provides fast and robust implementations of standard ML algorithms such as clustering, classification, and regression.
Scikit-learn’s strength has typically been in the realm of computing on a single node, though. For some common scenarios, such as parameter tuning, a large number of small tasks can be run in parallel. These scenarios are perfect use cases for Spark.
We explored how to integrate Spark with scikit-learn, and the result is the Scikit-learn integration package for Spark. It combines the strengths of Spark and scikit-learn with no changes to users’ code. It re-implements some components of scikit-learn that benefit the most from distributed computing. Users will find a Spark-based cross-validator class that is fully compatible with scikit-learn’s cross-validation tools. By swapping out a single class import, users can distribute cross-validation for their existing scikit-learn workflows.
Distribute tuning of Random Forests
Consider a classical example of identifying digits in images. Here are a few examples of images taken from the popular digits dataset, with their labels:
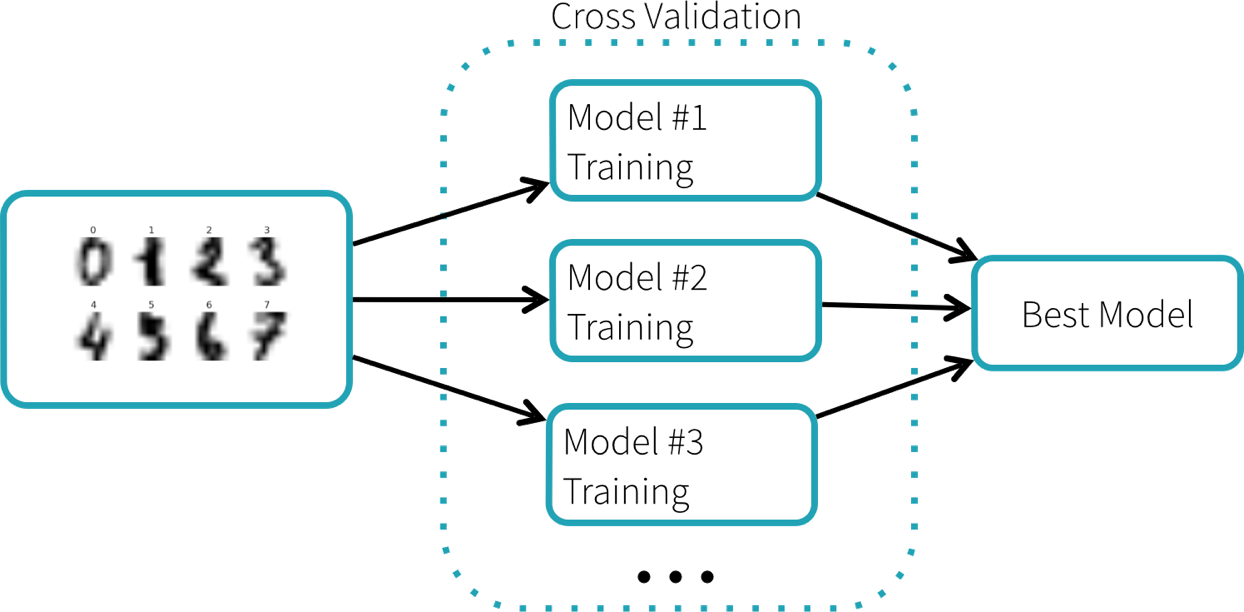
We are going to train a random forest classifier to recognize the digits. This classifier has a number of parameters to adjust, and there is no easy way to know which parameters work best, other than trying out many different combinations. Scikit-learn provides GridSearchCV, a search algorithm that explores many parameter settings automatically. GridSearchCV uses selection by cross-validation, illustrated below. Each parameter setting produces one model, and the best-performing model is selected.
The original code, using only scikit-learn, is as follows:
from sklearn import grid_search, datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
digits = datasets.load_digits()
X, y = digits.data, digits.target
param_grid = {"max_depth": [3, None],
"max_features": [1, 3, 10],
"min_samples_split": [1, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
"n_estimators": [10, 20, 40, 80]}
gs = grid_search.GridSearchCV(RandomForestClassifier(), param_grid=param_grid)
gs.fit(X, y)The dataset is small (in the hundreds of kilobytes), but exploring all the combinations takes about 5 minutes on a single core. The scikit-learn package for Spark provides an alternative implementation of the cross-validation algorithm that distributes the workload on a Spark cluster. Each node runs the training algorithm using a local copy of the scikit-learn library, and reports the best model back to the master:
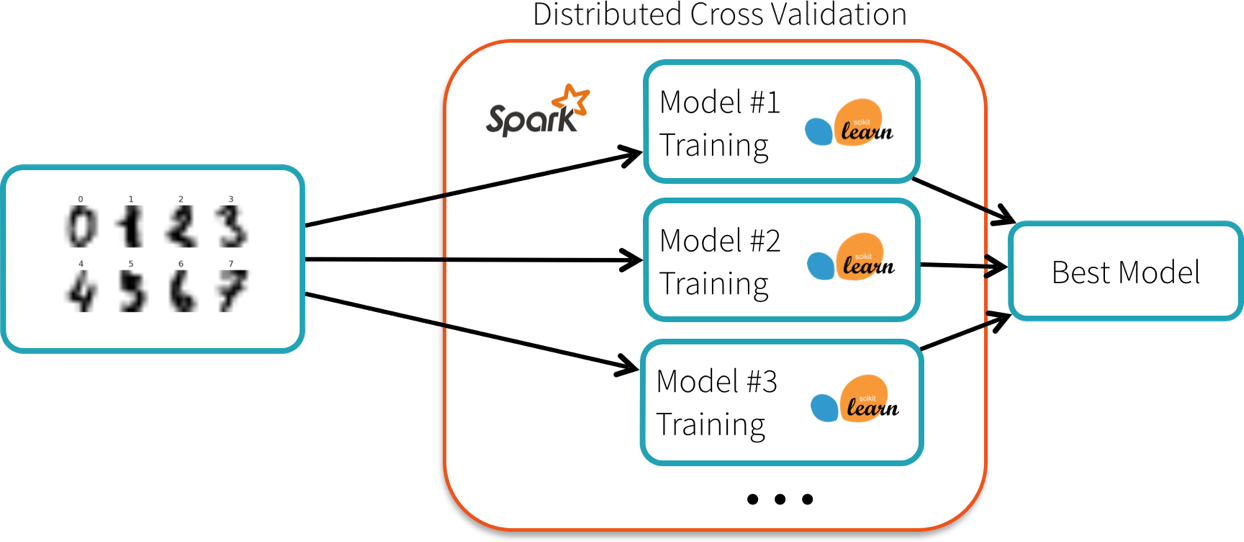
The code is the same as before, except for a one-line change:
from sklearn import grid_search, datasets
from sklearn.ensemble import RandomForestClassifier
# Use spark_sklearn’s grid search instead:
from spark_sklearn import GridSearchCV
digits = datasets.load_digits()
X, y = digits.data, digits.target
param_grid = {"max_depth": [3, None],
"max_features": [1, 3, 10],
"min_samples_split": [1, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
"n_estimators": [10, 20, 40, 80]}
gs = grid_search.GridSearchCV(RandomForestClassifier(), param_grid=param_grid)
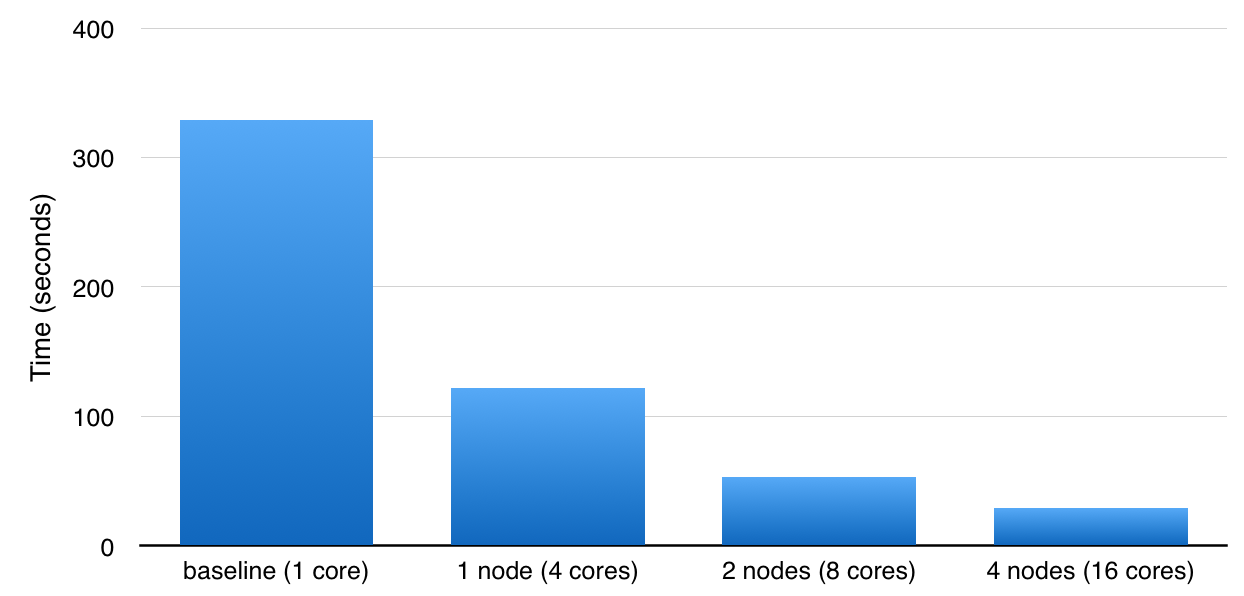
gs.fit(X, y)This example runs under 30 seconds on a 4-node cluster (which has 16 CPUs). For larger Datasets
" style="box-sizing: border-box; color: rgb(0, 0, 0) !important; text-decoration-line: none !important; border-bottom: 1px dotted rgb(0, 0, 0) !important;">datasets and more parameter settings, the difference is even more dramatic.
Get started
If you would like to try out this package yourself, it is available as a Spark package and as a PyPI library. To get started, check out this example notebook on Databricks.
In addition to distributing ML tasks in Python across a cluster, Scikit-learn integration package for Spark provides additional tools to export data from Spark to python and vice-versa. You can find methods to convert Spark DataFrames
" style="box-sizing: border-box; color: rgb(0, 0, 0) !important; text-decoration-line: none !important; border-bottom: 1px dotted rgb(0, 0, 0) !important;">DataFrames to Pandas dataframes and numpy arrays. More details can be found in this Spark Summit Europe presentation and in the API documentation.
Auto-scaling scikit-learn with Apache Spark的更多相关文章
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- Offset Management For Apache Kafka With Apache Spark Streaming
An ingest pattern that we commonly see being adopted at Cloudera customers is Apache Spark Streaming ...
- Why Apache Spark is a Crossover Hit for Data Scientists [FWD]
Spark is a compelling multi-purpose platform for use cases that span investigative, as well as opera ...
- Apache Spark 章节1
作者:jiangzz 电话:15652034180 微信:jiangzz_wx 微信公众账号:jiangzz_wy 背景介绍 Spark是一个快如闪电的统一分析引擎(计算框架)用于大规模数据集的处理. ...
- APACHE SPARK 2.0 API IMPROVEMENTS: RDD, DATAFRAME, DATASET AND SQL
What’s New, What’s Changed and How to get Started. Are you ready for Apache Spark 2.0? If you are ju ...
- What’s new for Spark SQL in Apache Spark 1.3(中英双语)
文章标题 What’s new for Spark SQL in Apache Spark 1.3 作者介绍 Michael Armbrust 文章正文 The Apache Spark 1.3 re ...
- A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets(中英双语)
文章标题 A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets 且谈Apache Spark的API三剑客:RDD.Dat ...
- Real Time Credit Card Fraud Detection with Apache Spark and Event Streaming
https://mapr.com/blog/real-time-credit-card-fraud-detection-apache-spark-and-event-streaming/ Editor ...
- How-to: Tune Your Apache Spark Jobs (Part 1)
Learn techniques for tuning your Apache Spark jobs for optimal efficiency. When you write Apache Spa ...
- Using Apache Spark and MySQL for Data Analysis
What is Spark Apache Spark is a cluster computing framework, similar to Apache Hadoop. Wikipedia has ...
随机推荐
- http请求中的 OPTIONS 多余请求消除,减少的案例
问题: 项目中遇到移动端发送同样的请求2次,仔细看了一下,有个是options报文. HTTP请求翻一倍,对服务器的性能有较大影响,造成nginx的无畏消耗,需要消除它. 解决思路: 1.上网查看了一 ...
- 关于java String类的getBytes(String charsetName)和String(byte[] bytes, String charsetName)
public byte[] getBytes(Charset charset) Encodes this String into a sequence of bytes using the given ...
- ORACLE隐式类型转换
隐式类型转换简介 通常ORACLE数据库存在显式类型转换(Explicit Datatype Conversion)和隐式类型转换(Implicit Datatype Conversion)两 ...
- 对权值线段树剪枝的误解--以HDU6703为例
引子 对hdu6703,首先将问题转化为"询问一个排列中大于等于k的值里,下标超过r的最小权值是多少" 我们采用官方题解中的做法:权值线段树+剪枝 对(a[i],i)建线段树,查询 ...
- C++解析Json,使用JsonCpp读写Json数据
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式.通常用于数据交换或存储. JsonCpp是一个基于C++语言的开源库,用于C++程序的J ...
- WampServer 更换 mysql
下载另外版本的mysql,复制到 wamp/bin,初始化号 修改wamp 的/wampmanager.conf 复制相关配置文件 [mysqloptions] mysqlPortUsed = &qu ...
- Rust入坑指南:步步为营
俗话说:"测试写得好,奖金少不了." 有经验的开发人员通常会通过单元测试来保证代码基本逻辑的正确性.如果你是一名新手开发者,并且还没体会到单元测试的好处,那么建议你先读一下我之前的 ...
- 基于MATLAB的单级倒立摆仿真
有关代码及word文档请关注公众号“浮光倾云”,后台回复A010.02即可获取 一.单级倒立摆概述 倒立摆是处于倒置不稳定状态,人为控制使其处于动态平衡的一种摆,是一类典型的快速.多变量.非线性.强耦 ...
- k8s系列---k8s认证及serviceaccount、RBAC
http://blog.itpub.net/28916011/viewspace-2215100/ 对作者文章有点改动 注意kubeadm创建的k8s集群里面的认证key是有有效期的,这是一个大坑!! ...
- golang-练习ATM --面向对象实现
package utils import ( "fmt" "strings" ) type StructAtm struct { action int loop ...