Spark On Yarn搭建及各运行模式说明
之前记录Yarn:Hadoop2.0之YARN组件,这次使用Docker搭建Spark On Yarn
一、各运行模式
1、单机模式
该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上没有问题。其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程拥有1个core)
指令实例:
1)spark-shell --master local
2)spark-shell --master local[4]代表会有4个线程(每个线程一个core)来并发执行应用程序
运行该模式非常简单,只需要把Spark的安装包解压之后,改一些常用的配置即可使用,而不用启动Spark的Master 、Worker守护进程(只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非必须用到hdfs)这是和其他模式的区别。
2、伪集群模式
该模式和local[N]很像,不同的是。它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多线程只能在一个进程下共享资源。通常也是用来验证开发出来的应用程序在逻辑上有没有问题,或想使用Spark的计算框架而没有太多资源。
指令实例:
spark-shell --master local-cluster[2,3,1024]
用法:提交应用程序时使用local-cluster[x,y,z],参数:x代表要生成executor数,y和z分别代表每个executor所拥有的core和memory数,上面这条命令表示:会使用2个executor进程,每个进程分配3个core和1G内存来运行应用程序
该模式非常简单,只需要把spark的安装包解压后,改一些常用的配置即可使用。而不用启动Spark的Master、Worker守护进程(只有集群的standalone方式时,也不用启动hadoop的各服务)。
3、集群模式1---spark自带的Cluster Manager的Standalone client模式
和单机运行模式不同,这里必须在执行应用程序前,先启动Spark的Master和Worker守护进程。不用启动Hadoop服务,除非必须用到。然后在想要作为Master的节点上用start-all.sh来启动即可。这样运行模式,可以使用spark的8080 web ui来观察资源和应用程序的执行情况
指令实例:
1)spark-shell --master spark://spark01:7077
2)spark-shell --master spark://spark01:7077 --deploy-mode client
产生的进程
①Master进程作为clust manager,用来对应用程序申请的资源进行管理。
②SparkSubmit作为client端和运行Driver程序
③CoarseGrainedExecutorBackend用来并发执行程序
4、集群模式2---spark自带的Cluster Manager的standalone cluster模式
指令实例:
spark-submit --master spark://spark01:6066 --deploy-mode cluster
与第三种模式的区别:
①客户端的SparkSubmit进程会在应用程序提交给集群后退出
②Master会在集群中选择一个Worker进程生成一个子进程DriverWrapper来启动Driver来启动程序
③该DriverWrapper进程会占用Worker进程的一个core,所以同样的资源配置下,会比第三种运行模式,少一个core来参与运算
④应用程序的结果,会在执行Driver程序的节点的sdtout中输出,而不是打印在屏幕上。
5、集群模式3---基于Yarn的ResourceManager的Client模式
现在越来越多的场景,都是Spark跑在Hadoop集群中,所以为了做到资源能够均衡调度,会使用Yarn来作为Spark的Cluster的Manager,来为Spark的应用程序分配资源。在执行Spark应用程序之前,要启动Hadoop的各个服务。由于已经有了资源管理器,所以不需要启动Spark的Master、Work守护进程。
指令实例:
①spark-shell --master yarn
②spark-shell --master yarn --deploy-mode client
提交应用程序后,各节点会启动相关JVM进程,如下:
①在ResourceManager节点上提交应用程序,会生成SparkSubmit进程,该进程会执行Driver程序。
②RM会在集群中的某个NodeManager上启动一个ExecutorLauncher进程来作为ApplicationMaster
③RM也会在多个NodeManager上生成一个CoarseGrainedExecutorBackend进程来并发执行应用程序。
6、集群模式4----基于Yarn的ResourceManager的Cluster模式
指令实例:
①spark-shell --master yarn --deploy-mode client
和第5种的区别如下:
①在ResourceManager端提交应用程序,会生成SparkSubmit进程,该进程只用来做Client端,应用程序提交给集群后,就会删除该进程
②ResourceManager在集群中的某个NodeManager中运行ApplicationMaster,该AM同时会执行Driver程序,紧接着,各NodeManager上运行CoarseGrainedExecutorBackend来并发执行应用程序
③应用程序的结果,会在执行Driver应用程序的节点的sdtout输出,而不是打印在屏幕上。
7、Spark On Mesos模式
http://ifeve.com/spark-mesos-spark/
二、Spark On Yarn
官方说明:http://spark.apache.org/docs/latest/running-on-yarn.html、http://spark.apache.org/docs/latest/submitting-applications.html
1、图解说明
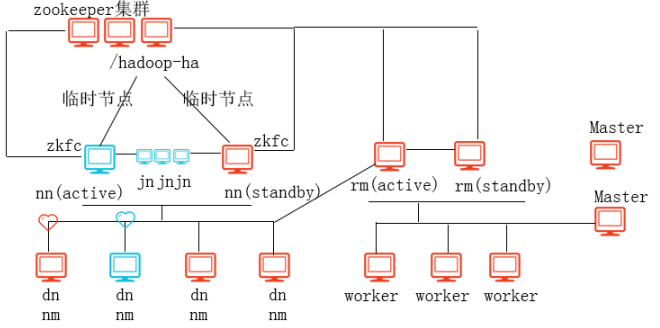
Spark On Yarn模式:Spark集群的资源管理器不是由Master(Cluster Manager)来管理,而是由Yarn的ResourceManager来管理,而Spark的任务调度依然是由SparkContext来调度。
2、环境搭建
本地搭建还是基于之前的环境:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),基于以上6个容器的Zookeeper集群、hadoop集群等环境来搭建。
Spark on YARN运行模式,只需要在Hadoop分布式集群中任选一个节点安装配置Spark即可,不要集群安装。因为Spark应用程序提交到YARN后,YARN会负责集群资源的调度,任选一个hadoop容器来安装spark即可。
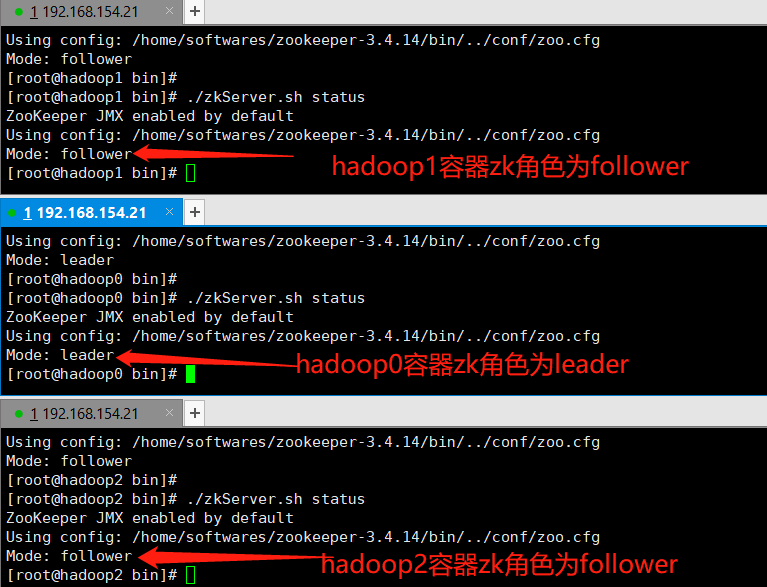
1、启动Zookeeper集群
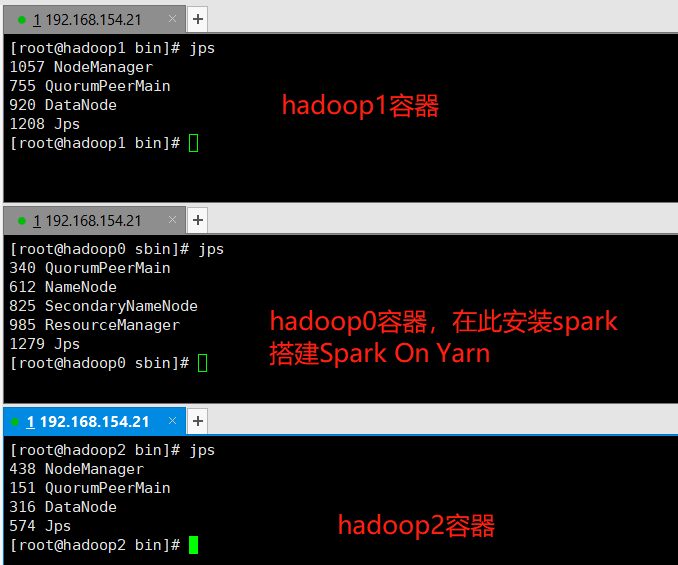
2、启动hadoop集群
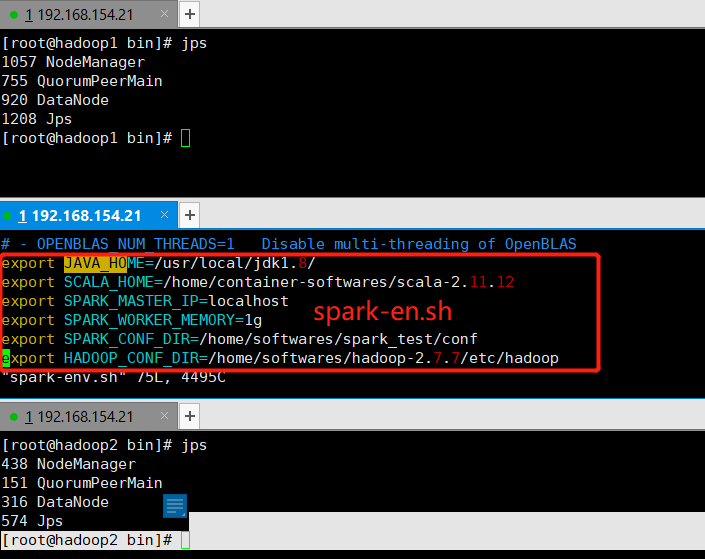
3、hadoop0容器安装配置spark,拷贝编辑spark-env.sh
4、启动测试
spark的bin目录执行命令:./spark-shell --master yarn --deploy-mode client
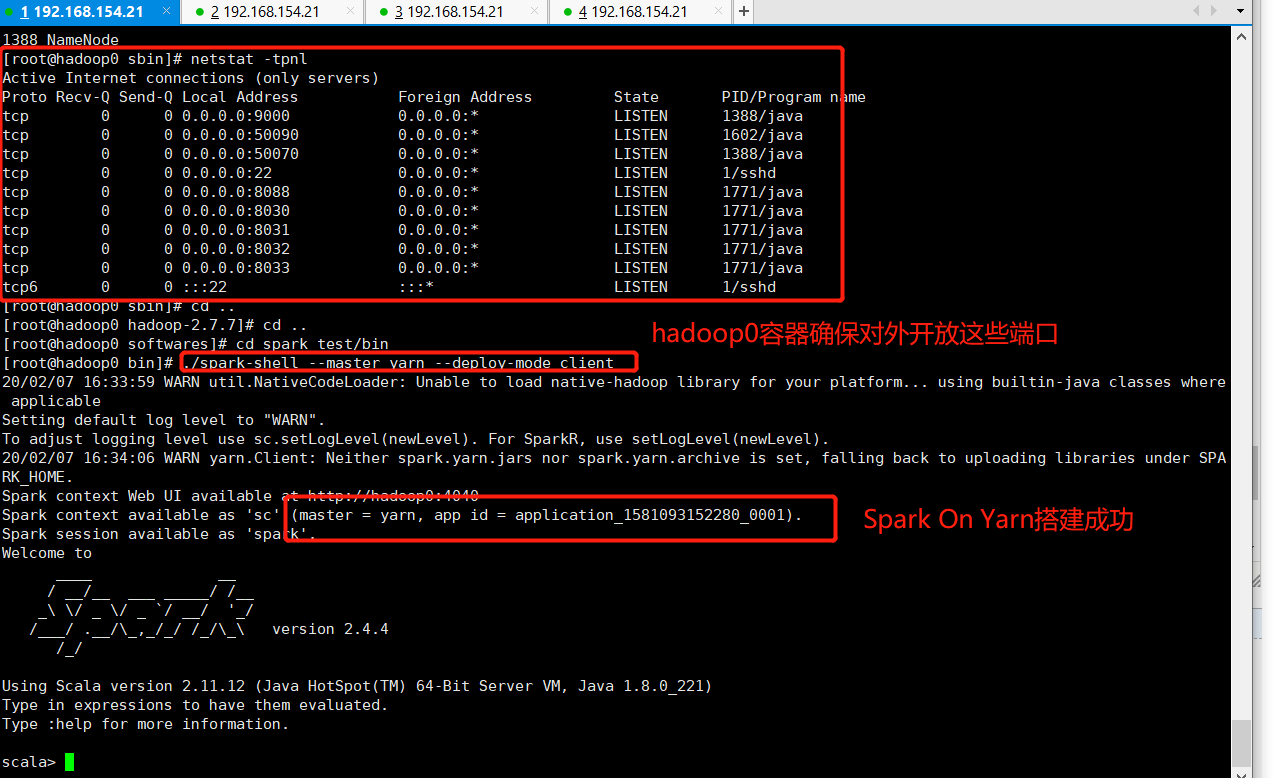
5、Yarn Web界面
可以看到Spark shell应用程序正在运行,单击ID号链接,可以看到该应用程序的详细信息。
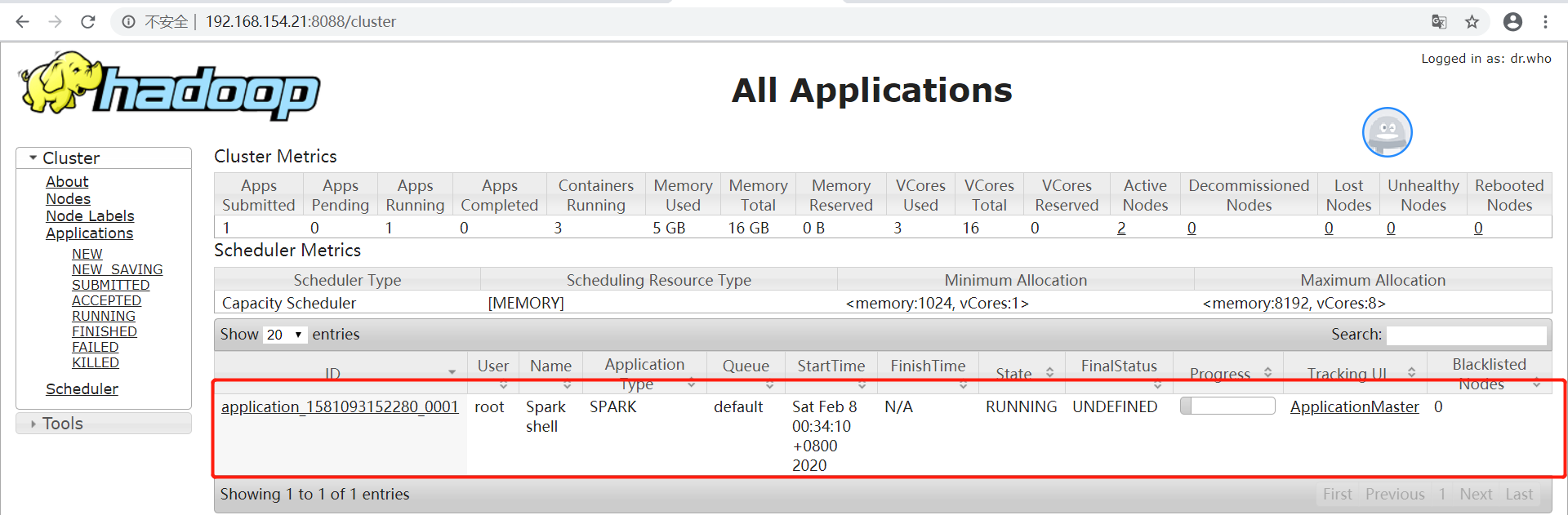
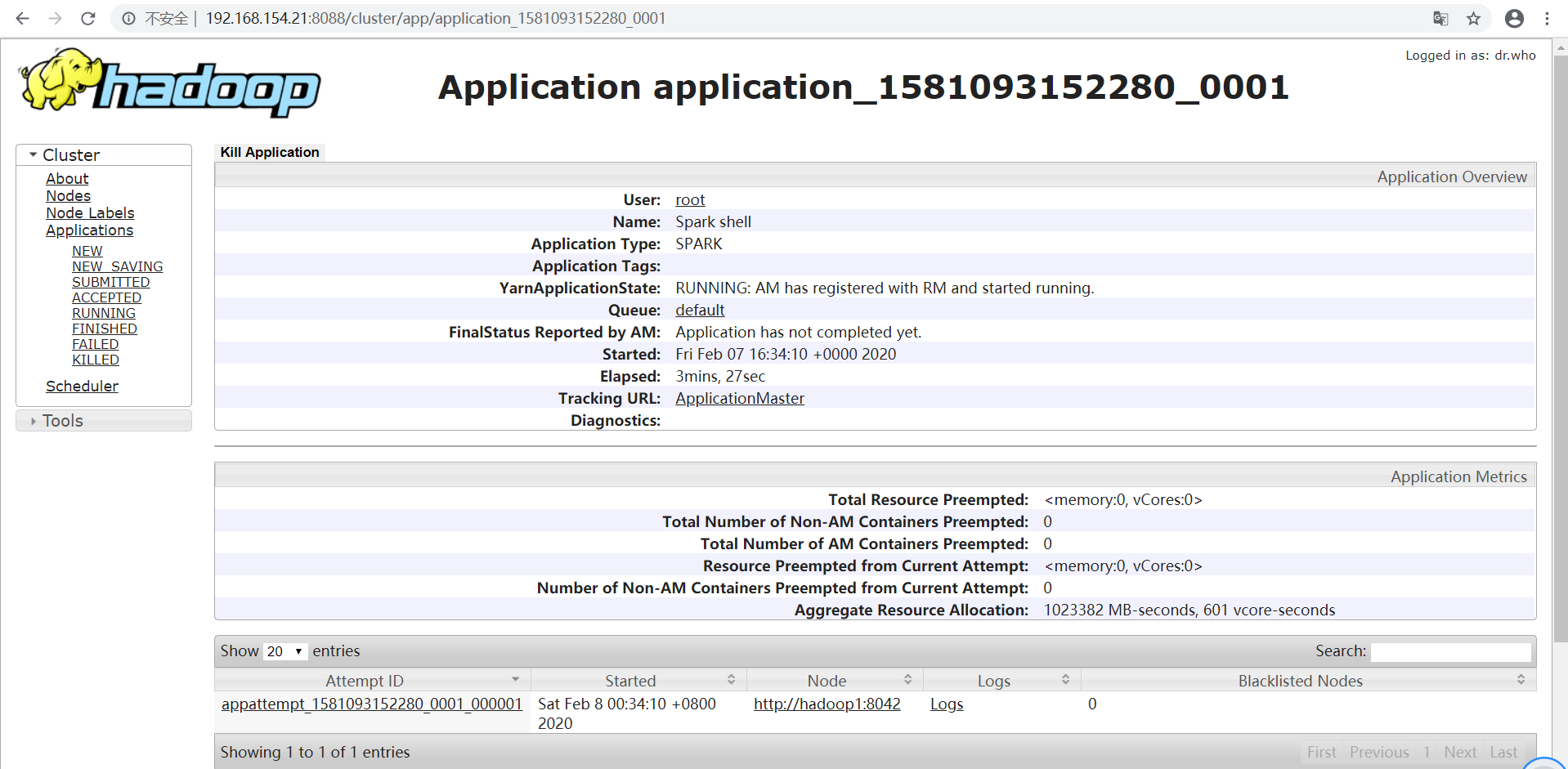
3、问题解决
如果是用虚拟机搭建,可能会由于虚拟机内存过小而导致启动失败,比如内存资源过小,yarn会直接kill掉进程导致rpc连接失败。所以,我们还需要配置Hadoop的yarn-site.xml文件,加入如下两项配置:
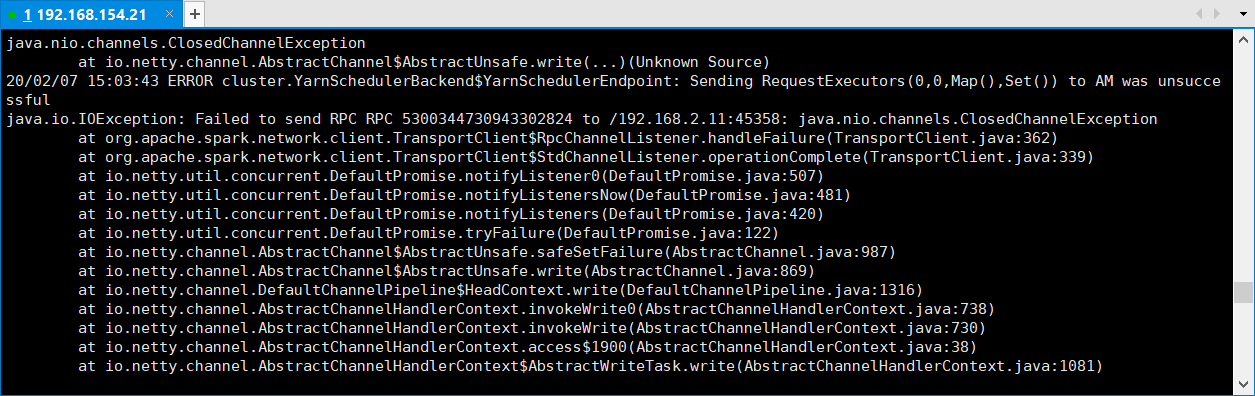
编辑yarn-site.xml添加如下内容即可
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property> <property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
如有问题,欢迎指正交流~~~~
Spark On Yarn搭建及各运行模式说明的更多相关文章
- Spark on YARN的两种运行模式
Spark on YARN有两种运行模式,如下 1.yarn-cluster:适合于生产环境. Spark的Driver运行在ApplicationMaster中,它负责向YARN Re ...
- spark基于yarn的两种提交模式
一.spark的三种提交模式 1.第一种,Spark内核架构,即standalone模式,基于Spark自己的Master-Worker集群. 2.第二种,基于YARN的yarn-cluster模式. ...
- 019 spark on yarn(Job的运行流程,可以对比mapreduce的yarn运行)
1.大纲 spark应用构成:Driver(资源申请.job调度) + Executors(Task具体执行) Yarn上应用运行构成:ApplicationMaster(资源申请.job调度) + ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- Spark Client和Cluster两种运行模式的工作流程
1.client mode: In client mode, the driver is launched in the same process as the client that submits ...
- Hadoop之搭建完全分布式运行模式
一.过程分析 1.准备3台客户机(关闭防火墙.修改静态ip.主机名称) 2.安装JDK 3.配置环境变量 4.安装Hadoop 5.配置集群 6.单点启动 7.配置ssh免密登录 8.群起并测试集群 ...
- 大话Spark(2)-Spark on Yarn运行模式
Spark On Yarn 有两种运行模式: Yarn - Cluster Yarn - Client 他们的主要区别是: Cluster: Spark的Driver在App Master主进程内运行 ...
- Spark on Yarn 集群运行要点
实验版本:spark-1.6.0-bin-hadoop2.6 本次实验主要是想在已有的Hadoop集群上使用Spark,无需过多配置 1.下载&解压到一台使用spark的机器上即可 2.修改配 ...
- Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
前期博客 Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz +hadoop-2.6.0.tar.gz)(master.slave1和slave2)(博主 ...
随机推荐
- 获取URL地址参数方法
//获取url参数 getQueryVariable(variable){ var query =decodeURIComponent(window.location.search.substring ...
- 微信小程序报错TypeError: this.setData is not a function
今天在练习小程序的时候,遇到小程序报错 对于处于小白阶段的我,遇到这种报错,真还不知道是错从何来,只有一脸蒙逼,后来通过查询,终于知道了问题所在,下面对这一问题做一记录 小程序默认中是这么写的 onL ...
- unity踩坑2020-01-21
这几天一直在测试一个类似于传奇的2d界面游戏,目前做的测试为: 人物动作响应,主要是8方向的判断和资源文件精灵的刷新. 学到的知识点: 1,Enum.GetHashCode() 可以得到这个枚举的索引 ...
- SMTP模块发送邮件
import os import smtplib # 处理多种形态的邮件主体我们需要 MIMEMultipart 类 from email.mime.multipart import MIMEMult ...
- 第四十九篇 入门机器学习——数据归一化(Feature Scaling)
No.1. 数据归一化的目的 数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用. No.2. 数据归一化的方法 数据归一化的方法主要 ...
- Quick Sort(快速排序)
Quick Sort Let's arrange a deck of cards. Your task is to sort totally n cards. A card consists of a ...
- Pytest学习10-pytest与unittest的区别
一.用例编写规则 1.unittest提供了test cases.test suites.test fixtures.test runner相关的类,让测试更加明确.方便.可控.使用unittest编 ...
- keepalived高可用工具
1.准备俩台虚拟机,一台主机,一台备机 我这里模拟的是 主机ip: 192.168.42.66 masternginx 备机ip: 192.168.42.77 slavenginx 虚拟ip: 192 ...
- jsp报错java.io.IOException: Stream closed
在使用jsp的时候莫名其妙的抛出了这个异常,经过反复检查 去掉了网友们说的jsp使用流未关闭,以及tomcat版本冲突等原因,最后发现是书写格式的原因. 当时使用的代码如下 <jsp:inclu ...
- Redis Desktop Manager 连接不上redis的问题
1.需要启动redis,进入后测试,ping,回应pong,说明redis可用 启动redis的代码: redis-server /myredis/redis.conf redis-cli 如果还是连 ...