假期学习【三】HDFS操作及spark的安装/使用
1.安装 Hadoop 和 Spark
进入 Linux 系统,参照本教程官网“实验指南”栏目的“Hadoop 的安装和使用”,完
成 Hadoop 伪分布式模式的安装。完成 Hadoop 的安装以后,再安装 Spark(Local 模式)。
2.HDFS 常用操作
使用 hadoop 用户名登录进入 Linux 系统,启动 Hadoop,参照相关 Hadoop 书籍或网络
资料,或者也可以参考本教程官网的“实验指南”栏目的“HDFS 操作常用 Shell 命令”,
使用 Hadoop 提供的 Shell 命令完成如下操作:
(1) 启动 Hadoop,在 HDFS 中创建用户目录“/user/hadoop”;
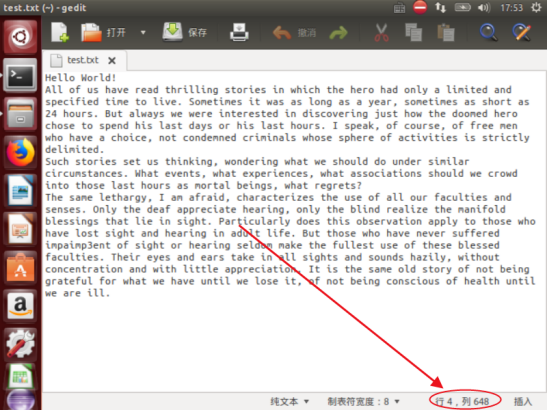
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件
test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop”
目录下;
进入/home/hadoop目录,并创建test.txt文件

输入内容
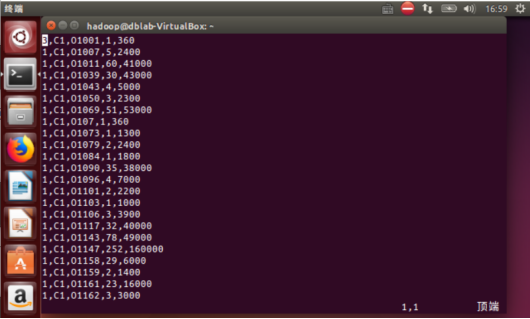
将文件上传到HDFS的/user/hadoop目录下,并查看。

可以发现已经上传成功
(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文
件系统中的“/home/hadoop/下载”目录下;
执行如下命令。

可以查看到已经下载到本地。
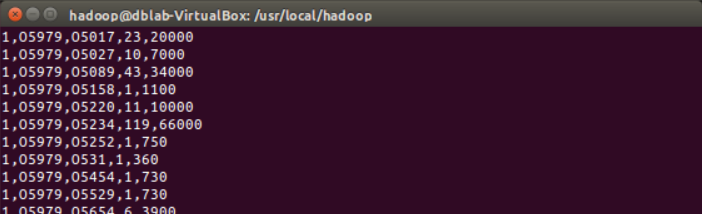
(4) 将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
执行如下命令

可以显示
(5) 在 HDFS 中的“/user/hadoop”目录下,创建子目录 input,把 HDFS 中
“/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;

(6) 删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”
目录下的 input 子目录及其子目录下的所有内容。

3. Spark 读取文件系统的数据
Spark安装
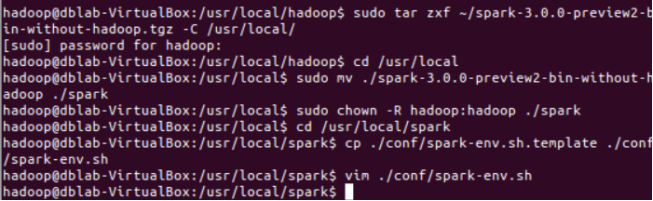
在Spark官网:http://spark.apache.org/downloads.html 下载Spark
并在修改Spark的配置文件spark-env.sh添加输入下列命令:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
如图:

测试输入图中命令将输出大量信息

将得到一个π的近似数,说明安装成功
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
启动spark-shell
(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;
统计结果

未理解的问题:
显示4行正确,但不理解为什么界面行数大于统计的行数。
(3)编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,
并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
1.安装sbt

假期学习【三】HDFS操作及spark的安装/使用的更多相关文章
- git学习——<三>git操作
一.创建仓库 创建一个目录 mkdir repository cd到该目录下,初始化该版本库 git init 至此,版本库创建成功,可以在该文件夹下看到.git文件夹,ls -ah可以看到该文件夹. ...
- Redis基础学习(三)—Key操作
一.key的相关操作 1.删除 del key1 key2 ... Keyn 作用: 删除1个或多个键. 返回值: 不存在的key忽略掉,返回真正删除的key的数量. 2.重命名 rename k ...
- jquery 学习(三) - 遍历操作
HTML代码 <p>1111</p> <p>1111</p> <p>1111</p> <p>1111</p&g ...
- Python基础学习三 文件操作(一)
文件读写 r,只读模式(默认). w,只写模式.[不可读:不存在则创建:存在则删除内容:] a,追加模式.[不可读: 不存在则创建:存在则只追加内容:] r+,[可读.可写:可追加,如果打开的文件不存 ...
- deno学习三 官方提供的方便deno 安装方式
早起deno 使用了golang 开发,同时需要protobuf 进行数据的序列化以及反序列化处理 当前的deno 已经使用rust 进行了开发,同时官方提供的安装方式也很方便了,不需要 那么复杂的编 ...
- hadoop学习(五)----HDFS的java操作
前面我们基本学习了HDFS的原理,hadoop环境的搭建,下面开始正式的实践,语言以java为主.这一节来看一下HDFS的java操作. 1 环境准备 上一篇说了windows下搭建hadoop环境, ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作
Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作 1.sparkstreaming实时写入Hbase(saveAsNewAPIHadoopDataset方法 ...
随机推荐
- MacBook通过SSH远程访问Parallel中的Ubuntu简明教程
作为一个前端,后端也需要了解,最终选择PHP入手学习,本来想选择Python,思前想后还是PHP作为Web开发比较合适,环境最终选择Ubuntu开发,由于是第一次,遇到不少坑,经过不懈的努力不断Goo ...
- Linux系统WEB服务之Nginx基础入门
一.Nginxi简介 Nginx是什么?它是一个开源.高性能的WEB服务器软件和代理服务器软件,由俄罗斯人Igor Sysoev 开发实现.它的功能主要分三类,第一是它作为一个WEB服务软件使用:第二 ...
- Python json 序列号字典 文本的存储和读取
rootDir='./resources/v1/'# 根目录 # 按钮测试图片 btnTestPicUrl = { 'armyAttack' : rootDir+'testPic/gj2.jpg', ...
- C# 利用委托事件进行窗体间的传值(新手必看)
引言: 窗体间传值是每个学习WinForm新手的常见问题,最初级的方法就是 在窗体中先获取到要接受值窗体.然后通过.得到某个空间或者属性,直接赋值,这个需要接收放的窗体属性或者空间必须是public ...
- python命令行运行django项目, can't open file 'manage.py' 问题解决
找到manage.py的绝对路径即可运行
- Nginx架构分析(20200202)
Nginx模块化 Nginx基于模块化设计,每个模块是一个功能实现,分布式开发,团队协作 核心模块.标准HTTP模块.可选HTTP模块.邮件模块.第三方模块 编译后的源码目录objs/ngx_modu ...
- 基于SSM开发大学食堂采购管理系统源码
开发环境: Windows操作系统开发工具: Eclipse+Jdk+Tomcat+MySQL数据库 次项目分为管理员和普通用户两种角色 运行效果图
- Windows通过DOS命令行设置IP地址
@rem 设置固定IP地址netsh interface ip set address "本地连接" static 192.168.1.200 255.255.255.0 192. ...
- MySQL基础入门使用和命令的使用
数据库了解 概念 数据库就是一种特殊的文件,其中存储着需要的数据 一个数据库可以有多张表 MySQL是一种关系型数据库 具有关联性数据的就是关系型数据库 MySQL是一种软件可以用来创建mysql数据 ...
- 视频会议系统MCU服务器视频传输处理模式
视频会议系统MCU服务器视频传输处理模式 视频会议系统的组成主要包括终端.MCU服务器.网守等,其中的MCU服务器是整个系统的核心,视频会议系统的性能很大程度取决于MCU服务器的性能,因此MCU服务器 ...