Python实现DBSCAN聚类算法(简单样例测试)
发现高密度的核心样品并从中膨胀团簇。
Python代码如下:
# -*- coding: utf-8 -*-
"""
Demo of DBSCAN clustering algorithm
Finds core samples of high density and expands clusters from them.
"""
print(__doc__)
# 引入相关包
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 初始化样本数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# 计算DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# 聚类的结果
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels,
average_method='arithmetic'))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# 绘出结果
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
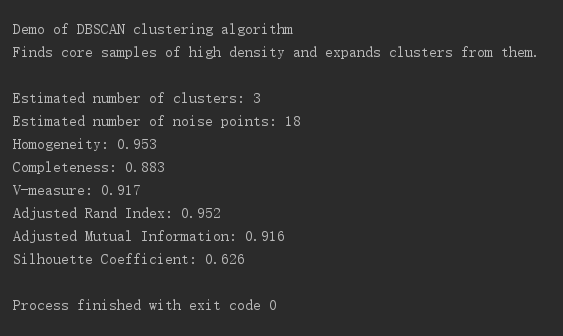
测试结果如下:
最终结果绘图:
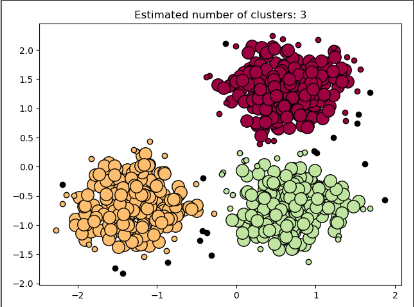
具体数据:
Python实现DBSCAN聚类算法(简单样例测试)的更多相关文章
- extern外部方法使用C#简单样例
外部方法使用C#简单样例 1.添加引用using System.Runtime.InteropServices; 2.声明和实现的连接[DllImport("kernel32", ...
- spring事务详解(二)简单样例
系列目录 spring事务详解(一)初探事务 spring事务详解(二)简单样例 spring事务详解(三)源码详解 spring事务详解(四)测试验证 spring事务详解(五)总结提高 一.引子 ...
- 机器学习入门-DBSCAN聚类算法
DBSCAN 聚类算法又称为密度聚类,是一种不断发张下线而不断扩张的算法,主要的参数是半径r和k值 DBSCAN的几个概念: 核心对象:某个点的密度达到算法设定的阈值则其为核心点,核心点的意思就是一个 ...
- Python实现 K_Means聚类算法
使用 Python实现 K_Means聚类算法: 问题定义 聚类问题是数据挖掘的基本问题,它的本质是将n个数据对象划分为 k个聚类,以便使得所获得的聚类满足以下条件: 同一聚类中的数据对象相似度较高 ...
- velocity简单样例
velocity简单样例整体实现须要三个步骤,详细例如以下: 1.创建一个Javaproject 2.导入须要的jar包 3.创建须要的文件 ============================= ...
- 自己定义隐式转换和显式转换c#简单样例
自己定义隐式转换和显式转换c#简单样例 (出自朱朱家园http://blog.csdn.net/zhgl7688) 样例:对用户user中,usernamefirst name和last name进行 ...
- Kafka在Linux上安装部署及样例测试
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了 ...
- gtk+3.0的环境配置及基于gtk+3.0的python简单样例
/********************************************************************* * Author : Samson * Date ...
- 5.无监督学习-DBSCAN聚类算法及应用
DBSCAN方法及应用 1.DBSCAN密度聚类简介 DBSCAN 算法是一种基于密度的聚类算法: 1.聚类的时候不需要预先指定簇的个数 2.最终的簇的个数不确定DBSCAN算法将数据点分为三类: 1 ...
随机推荐
- Failed to get convolution algorithm解决
蒸腾了两天,终于搞定了 是cudnn版本的问题 更新cudnn的时候,首先要删除/usr/local/cuda-10.0/targets/x86_64-linux/lib路径下所有之前cudnn版本的 ...
- Shiro知识初探(更新中)
Shiro 是当下常见的安全框架,主要用于用户验证和授权操作. RBAC 是当下权限系统的设计基础,同时有两种解释:一: Role-Based Access Control,基于角色的访问控制即,你要 ...
- 百度大脑发布“AI开发者‘战疫’守护计划”,AI支援抗疫再升级
面对新冠肺炎疫情,AI开发者们正在积极运用算法.算力.软件等“武器”助力抗疫.针对开发者们在疫情防控期间的开发与学习需求,2月6日,百度大脑推出“AI开发者‘战疫’守护计划”, 正在进行疫情防控相关应 ...
- ArcGIS Runtime SDK for Android 加载shp数据,中文乱码问题
针对ArcGIS10.2版本的解决办法(默认中文编码为OEM): 现有一个图层名称为“图层.shp”,以此为例: 1.拷贝一个cpg文件,修改名称为“图层.cpg”,并用文本打开cpg文件修改编码为“ ...
- export default和export的使用方法
Node中 向外暴露成员,使用module.exports和exports module.exports = {} Node中导入模块 var 名称 = require('模块标识符') 在ES6中 ...
- ubuntu--- tracker/libdeepsort.so 找不到cv报错
一.刚开始解决尝试:因为“删掉lib下的libdeepsort.so报错”,原先以为是 libdeepsort.so 需要拷贝到 /lib路径下的问题,可是因为后来的工程有的好使,又的不好使了.''' ...
- PhpCms V9调用指定栏目子栏目文章的方法
PhpCms V9调用指定栏目子栏目文章的方法 第一种,直接写父类id {pc:content action="lists" catid="父类id" num= ...
- Python_3
""" Function_1: 寻找水仙花数. 水仙花数也被称为超完全数字不变数.自恋数.自幂数.阿姆斯特朗数, 它是一个3位数,该数字每个位上数字的立方之和正好等于它本 ...
- 在VS的依赖项中引用项目
操作步骤:鼠标右击项目(注意是项目)->添加->引用->项目(在项目列表中选择需要引用的项目)->确定
- 【Pyecharts可视化分享】杭州步行热门路线等~
前言 本文包括内容如下: 杭州步行热门路线 渐变效果散点图 均是Echarts官方提供等示例,本文将会通过Pyecharts来进行实现. 杭州步行热门路线 因为代码中需要调用百度地图,所以开始之前你需 ...