大数据(5)---分布式任务资源调度Yarn
前面也说到过的Yarn是hadoop体系中的资源调度平台。所以在整个hadoop的包里面自然也是有它的。这里我们就简单介绍下,并配置搭建yarn集群。
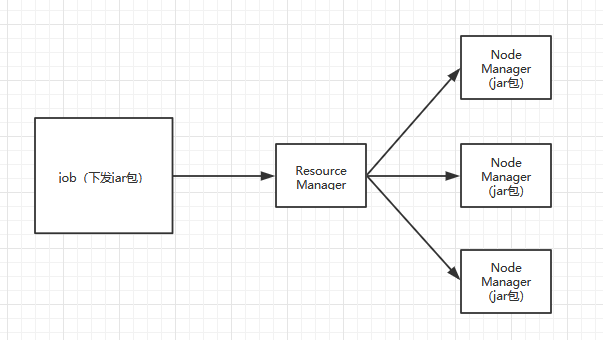
首先来说Yarn中有两大核心角色Resource Manager和Node Manager。
Resource Manager负责接收用户提交的分布式计算程序/任务,并为其划分资源,管理监控各个Node Manager。
Node Manager 接收resoResource Manager分配过来的任务,并计算。
通俗一点说就是计算程序会被打成一个jar包,然后分配到每个node manager上面去,这样每个node manager 执行的代码都是一样,只是可能数据源不一样。
集群配置:
node manager在物理上应该跟data node部署在一起,方便数据的读取
Yarn的软件在hadoop里面的都是有的,就和hdfs一样,我们只需要去配置一下,然后启动就可以了
每台机器都对etc/hadoop/yarn-site.xml进行配置
<property><!--配置redource manager-->
<name>yarn.resourcemanager.hostname</name>
<value>nijunyang68</value>
</property>
因为之前配置hdfs集群的时候已经在slaves中将集群IP的都配置进去了,所以现在只需要一键执行脚本就可以了:start-yarn.sh
注意在哪台机器启动redource manager就在那儿执行这个脚本,上面的配置只是告诉集群的中机器谁是redource manager,所以执行这个脚本需要在配置中的那个机器上面去执行。从日志中也可以看见,resource manager是在本机启动的,node manager是在其他机器上面启动的。

默认8088端口可以在web页面查看yarn集群信息
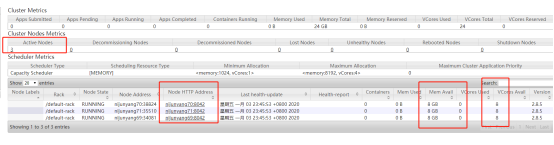
说一点,上面显示内存大小是不对的,因为我们没有配置,都是使用的默认,并不是我机器的实际值,实际上我的虚拟机总共才1G的内存

配置详情:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
内存有个最小分配限制1024,否则集群是无法启动的。
核数也并不是实际CPU的核数,我的虚拟机也才1核,这儿的意思是假如我内存200m,现在有一个任务需要100m内存,那么我这个机器就可以起两个任务,所以可以把核数配置成2,如果配置成那么久只能起一个任务。意思就是我CPU虽然是一核,但是我一个人100M,我200内存可以起两个任务,那么我CPU的运算能力就平均分给这两个任务。
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>

至此yarn集群就搭建完毕,后续就等着mapreduce任务丢上去运行了。
大数据(5)---分布式任务资源调度Yarn的更多相关文章
- 大数据hbase分布式安装及其部署。
大数据hbase分布式安装及其部署. 首先要启动Hadoop以及zookeeper,可以参考前面发布的文章. 将hbase的包上传至master节点 这里我使用的是1.3.6的版本,具体的根据自己的版 ...
- 基于Ubuntu16搭建Hadoop大数据完全分布式环境
[目的]:学习大数据 在此记录搭建大数据的过程. [系统环境] 宿主机操作系统:Win7 64位 虚拟机软件:Vmware workstation 12 虚拟机:Ubuntu 16 64位桌面版 [步 ...
- 大数据技术 - 分布式文件系统 HDFS 的设计
本章内容介绍下 Hadoop 自带的分布式文件系统,HDFS 即 Hadoop Distributed Filesystem.HDFS 能够存储超大文件,可以部署在廉价的服务器上,适合一次写入多次读取 ...
- 大数据基础总结---MapReduce和YARN技术原理
Map Reduce和YARN技术原理 学习目标 熟悉MapReduce和YARN是什么 掌握MapReduce使用的场景及其原理 掌握MapReduce和YARN功能与架构 熟悉YARN的新特性 M ...
- 大数据: 完全分布式Hadoop集群-HBase安装
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. 本文基 ...
- 【大数据】分布式并行计算MapReduce
作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1. 用自己的话阐明Hadoop平台上HDFS和MapReduc ...
- 【大数据】分布式文件系统HDFS 练习
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3292 利用Shell命令与HDFS进行交互 以”./bin/dfs d ...
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
随机推荐
- D - Denouncing Mafia DFS
这道题其实很简单,求k个到根的链,使得链上的节点的个数尽可能多,如果节点被计算过了,就不能再被计算了,其实我们发现,只要k>=叶子节点,那么肯定是全部,所以我们考虑所有的叶子节点,DFS到根节点 ...
- PHP怎么调用其他类的方法
2个PHP,这个PHP中的类调用另一个PHP中的类,如何调用.Java中是import ,php中是什么?还是用其他什么方法? 1.引用类:比如类名为product,则:include('...路径/ ...
- Java排序算法总结
1.冒泡排序 冒泡排序是排序算法中最基本的一种排序方法,该方法逐次比较两个相邻数据的大小并交换位置来完成对数据排序,每次比较的结果都找出了这次比较中数据的最大项,因为是逐次比较,所以效率是O(N^2) ...
- H3C用Telnet登录
- @noi.ac - 493@ trade
目录 @description@ @solution@ @part - 1@ @part - 2@ @part - 3@ @part - 4@ @accepted code@ @details@ @d ...
- Python--day72--Django内置的serializers序列化介绍
序列化 Django内置的serializers def books_json(request): book_list = models.Book.objects.all()[0:10] from d ...
- java表达式和三目运算符
是由数字.运算符.数字分组符号(括号)等以能求得数值的有意义排列的序列; a + b 3.14 + a (x + y) * z + 100 boolean b= i < 10 && ...
- [转]解决pip安装太慢的问题
阅读目录 临时使用: 经常在使用Python的时候需要安装各种模块,而pip是很强大的模块安装工具,但是由于国外官方pypi经常被墙,导致不可用,所以我们最好是将自己使用的pip源更换一下,这样就能解 ...
- jekyll 添加 Valine 评论
本文告诉大家如何在自己搭建的静态博客添加 Valine 评论.在这前,我基本都是使用 多说,但是多说gg啦,所以就在找一个可以替换的评论 本来 Disqus是很好的,但是在国内很难打开,所以我就需要一 ...
- C# GUID ToString
最近在看到小伙伴直接使用 Guid.ToString ,我告诉他需要使用 Guid.ToString("N") ,为什么需要使用 N ,因为默认的是 D 会出现连字符. Guid ...