基础数据类型汇总补充,python集合与深浅拷贝
一、基础数据类型汇总补充
1.查看str所有方法方式
2.列表:在循环中删除元素,易出错或报错(飘红)
lis = [11,22,33,44,55]
# for i in range(len(lis)):
# print(i) # i = 0 i = 1 i = 2
# del lis[i]
# print(lis) # [11,22,33,44,55] [22, 44, 55] [22, 44]
可变数据类型,删除中数据改变。 报错: list assignment index out of range
#第一种
# lis = lis[::2]
# print(lis) #第二种
# l1 = []
# for i in lis:
# if lis.index(i) % 2 == 0:
# l1.append(i)
# lis = l1
# print(lis) # lis = [11,22,33,44,55]
# # for i in range(len(lis)-1,-1,-1):
# # if i % 2 == 1:
# # print(i)
# # del lis[i]
# # print(lis)
# # print(lis) # dic = dict.fromkeys([1,2,3],'春哥')
# print(dic)
# dic = dict.fromkeys([1,2,3],[])
# print(dic) # {1: [], 2: [], 3: []}
# dic[1].append('袁姐')
# print(dic)
# dic[2].extend('二哥')
# print(dic) # l1 = []
# l2 = l1
# l3 = l1
# l3.append('a')
# print(l1,l2,l3) # dic = {'k1':'v1','k2':'v2','a3':'v3'}
# dic1 = {}
#
# for i in dic:
# if 'k' not in i:
# dic1.setdefault(i,dic[i]) 在循环一个字典中,不能删除字典中的键值对。
# dic = dic1
# print(dic)
# l = []
# for i in dic:
# if 'k' in i:
# l.append(i)
# for i in l:
# del dic[i]
# print(dic) # 转化成bool值
# 0 '' [] () {} set() #元祖 如果元祖里面只有一个元素且不加,那此元素是什么类型,就是什么类型。
# tu1 = (1)
# tu2 = (1,)
# print(tu1,type(tu1))
# print(tu2,type(tu2))
# tu1 = ([1])
# tu2 = ([1],)
# print(tu1,type(tu1))
# print(tu2,type(tu2))
# dic = dict.fromkeys([1,2,3,],3)
# dic[1] = 4
# print(dic)
循环字典列表时,不要删除里面的东西。
二、集合
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
1,集合的创建。
set1 = set({1,2,'barry'})
set2 = {1,2,'barry'}
print(set1,set2) # {1, 2, 'barry'} {1, 2, 'barry'}
2,集合的增。add update

set1 = {'alex','wusir','ritian','egon','barry'}
set1.add('景女神')
print(set1)
#update:迭代着增加 类似列表中的extend
set1.update('A')
print(set1)
set1.update('老师')
print(set1)
set1.update([1,2,3])
print(set1)
3,集合的删。
set1 = {'alex','wusir','ritian','egon','barry'}
set1.remove('alex') # 删除一个元素
print(set1)
set1.pop() # 随机删除一个元素
print(set1)
set1.clear() # 清空集合
print(set1)
del set1 # 删除集合
print(set1)
查询:循环查
4.集合的其他操作:
4.1 交集。(& 或者 intersection)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
4.2 并集。(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7,8}
print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7,8}
4.3 差集。(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2)) # {1, 2, 3}
4.4反交集。 (^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
4.5子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
5,frozenset不可变集合,让集合变成不可变类型。
s = frozenset('barry')
print(s,type(s)) # frozenset({'a', 'y', 'b', 'r'}) <class 'frozenset'>
深浅copy
先问问大家,什么是拷贝?拷贝是音译的词,其实他是从copy这个英文单词音译过来的,那什么是copy? copy其实就是复制一份,也就是所谓的抄一份。深浅copy其实就是完全复制一份,和部分复制一份的意思。
1,先看赋值运算。
l1 = [1,2,3,['barry','alex']]
l2 = l1 l1[0] = 111
print(l1) # [111, 2, 3, ['barry', 'alex']]
print(l2) # [111, 2, 3, ['barry', 'alex']] l1[3][0] = 'wusir'
print(l1) # [111, 2, 3, ['wusir', 'alex']]
print(l2) # [111, 2, 3, ['wusir', 'alex']]
对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的,在举个例子,比如张三李四合租在一起,那么对于客厅来说,他们是公用的,张三可以用,李四也可以用,但是突然有一天张三把客厅的的电视换成投影了,那么李四使用客厅时,想看电视没有了,而是投影了,对吧?l1,l2指向的是同一个列表,任何一个变量对列表进行改变,剩下那个变量在使用列表之后,这个列表就是发生改变之后的列表。
2,浅拷贝copy。
#同一代码块下:
l1 = [1, '太白', True, (1,2,3), [22, 33]]
l2 = l1.copy()
print(id(l1), id(l2)) # 2713214468360 2713214524680
print(id(l1[-2]), id(l2[-2])) # 2547618888008 2547618888008
print(id(l1[-1]),id(l2[-1])) # 2547620322952 2547620322952 # 不同代码块下:
>>> l1 = [1, '太白', True, (1, 2, 3), [22, 33]]
>>> l2 = l1.copy()
>>> print(id(l1), id(l2))
1477183162120 1477183162696
>>> print(id(l1[-2]), id(l2[-2]))
1477181814032 1477181814032
>>> print(id(l1[-1]), id(l2[-1]))
1477183162504 1477183162504
对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的。

3,深拷贝deepcopy。
# 同一代码块下
import copy
l1 = [1, 'alex', True, (1,2,3), [22, 33]]
l2 = copy.deepcopy(l1)
print(id(l1), id(l2)) # 2788324482440 2788324483016
print(id(l1[0]),id(l2[0])) # 1470562768 1470562768
print(id(l1[-1]),id(l2[-1])) # 2788324482632 2788324482696
print(id(l1[-2]),id(l2[-2])) # 2788323047752 2788323047752 # 不同代码块下
>>> import copy
>>> l1 = [1, '太白', True, (1, 2, 3), [22, 33]]
>>> l2 = copy.deepcopy(l1)
>>> print(id(l1), id(l2))
1477183162824 1477183162632
>>> print(id(0), id(0))
1470562736 1470562736
>>> print(id(-2), id(-2))
1470562672 1470562672
>>> print(id(l1[-1]), id(l2[-1]))
1477183162120 1477183162312
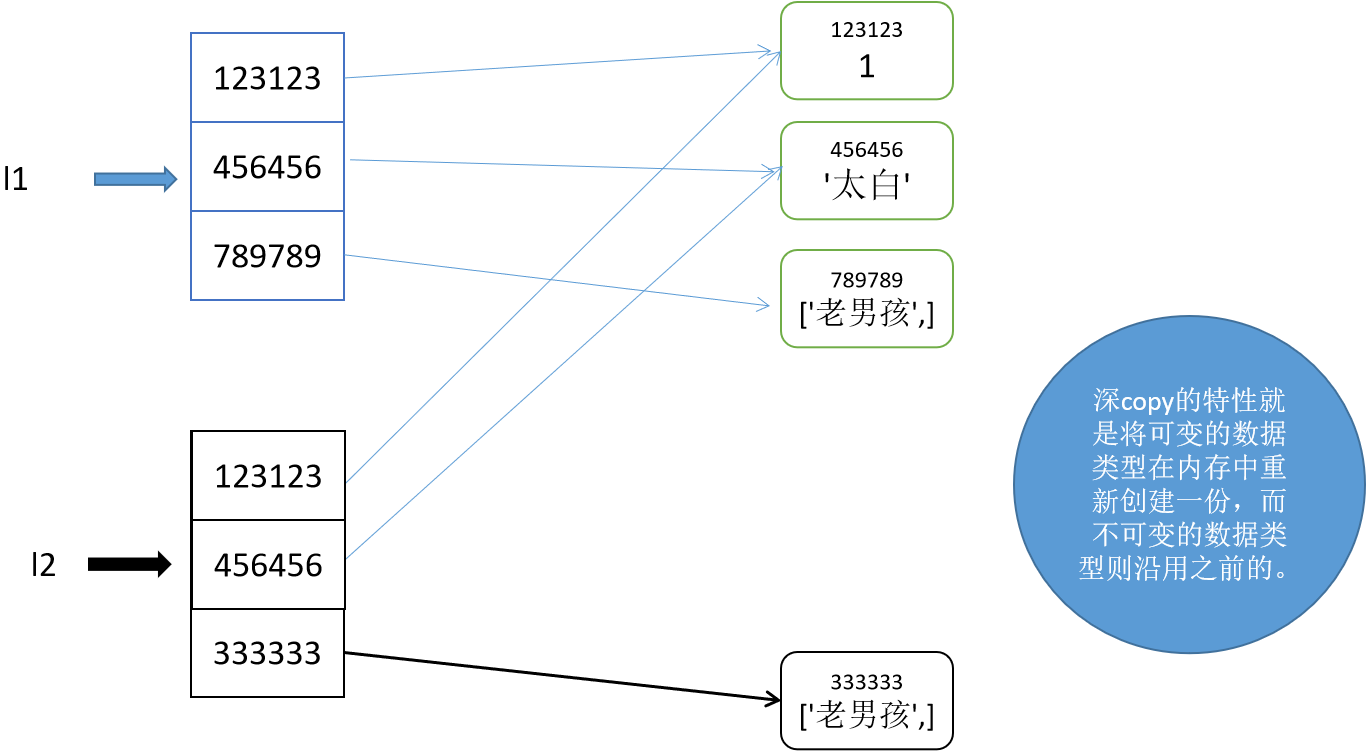
对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的。
l1 = [1, 2, 3, 4, ['alex']]
l2 = l1[::]
l1[-1].append(666)
print(l2) # [1, 2, 3, 4, ['alex', 666]]
基础数据类型汇总补充,python集合与深浅拷贝的更多相关文章
- 基础数据类型汇总补充;集合set ;深浅copy
首先回顾: 小数据池:int -5~256str 特殊字符,*数字20 ascii : 8位 1字节 表示1个字符unicode 32位 4个字节 表示一个字符utf- 8 1个英文 8位,1个字节 ...
- python 的基础 学习 第八天数据类型的补充 ,集合和深浅copy
1,数据类型的补充: 元组()tuple,如果只有元素,并且没有逗号,此元素是什么数据类型,该表达式就是什么数据类型. tu = ('rwr') print(tu,type(tu)) tu = ('r ...
- python day 07-数据类型补充,集合,深浅拷贝
一.基础数据类型补充 1.列表转字符串 a='A'.join(['c','c','s']) print(a) 2.循环删除列表中的每⼀一个元素 lst=['asdf','dftgst','zsdrfs ...
- day8数据类型补充,集合,深浅拷贝
思维导图: 集合的补充:下面的思维导图有一个点搞错了,在这里纠正一下,没有合集,是反交集,^这个是反差集的意思 . 交集&,反交集^,差集-,并集|,然后就是子集和超集 数据类型补充: ''' ...
- 基础数据类型的坑和集合及深浅copy
一.基础数据类型的坑: 元组: 如果一个元组中,只有一个元素,且没有逗号,则该"元组"与里面的数据的类型相同. # 只有一个数据,且没有逗号的情况: print(tu1,type( ...
- Python基础【3】:Python中的深浅拷贝解析
深浅拷贝 在研究Python的深浅拷贝区别前需要先弄清楚以下的一些基础概念: 变量--引用--对象(可变对象,不可变对象) 切片(序列化对象)--拷贝(深拷贝,浅拷贝) 我是铺垫~ 一.[变量--引用 ...
- 从入门到自闭之Python集合,深浅拷贝(大坑)
小数据池 int: -5~256 str: 字母,数字长度任意符合驻留机制 字符串进行乘法时总长度不能超过20 特殊符号进行乘法时只能乘以0 代码块: 一个py文件,一个函数,一个模块,终端中的每一行 ...
- 百万年薪python之路 -- 基础数据类型的补充
基础数据类型的补充 str: 首字母大写 name = 'alexdasx' new_name = name.capitalize() print(new_name) 通过元素查找下标 从左到右 只查 ...
- day 7 - 1 集合、copy及基础数据类型汇总
集合:{},可变的数据类型,他里面的元素必须是不可变的数据类型,无序,不重复.(不重要)集合的书写 set1 = set({1,2,3}) #set2 = {1,2,3,[2,3],{'name':' ...
随机推荐
- phpstrom 注释效果
/** * .,:,,, .::,,,::. * .::::,,;;, .,;;:,,....:i: * :i,.::::,;i:. ....,,:::::::::,.... .;i:,. ..... ...
- php注册 及审核练习
1.注册界面 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www. ...
- Java语法清单-快速回顾(开发)
Java CheatSheet 01.基础 hello,world! public static void main(String[] args) { System.out.println(" ...
- LeetCode 620. Not Boring Movies (有趣的电影)
题目标签: 题目给了我们一个 cinema 表格, 让我们找出 不无聊的电影,并且id 是奇数的,降序排列. 比较直接简单的,具体看code. Java Solution: Runtime: 149 ...
- jquery click事件失效
除了最基本的语法错误,还可能是因为,元素根本点击不到. z-index:99;
- day 88 DjangoRestFramework学习二之序列化组件、视图组件
DjangoRestFramework学习二之序列化组件.视图组件 本节目录 一 序列化组件 二 视图组件 三 xxx 四 xxx 五 xxx 六 xxx 七 xxx 八 xxx 一 序列化组件 ...
- NYOJ - 35 表达式求值 分类: NYOJ 2015-03-18 10:33 31人阅读 评论(0) 收藏
#include<iostream> #include<string> #include<stack> #include<cstdio> using n ...
- 创建第一个spirngmvc小项目
题外: 设置目录为源代码目录 1.进入:file->project structure->modules->soures 进入这个里面,选择相应的文件夹.例如src/java里的ja ...
- CSS3教程:Responsive框架常见的Media Queries片段
CSS3 Media Queries片段在这里主要分成三类:移动端.PC端以及一些常见的响应式框架的Media Queries片段.移动端Media Queries片段iPhone5@media sc ...
- 8分钟带你深入浅出搞懂Nginx
Nginx是一款轻量级的Web服务器.反向代理服务器,由于它的内存占用少,启动极快,高并发能力强,在互联网项目中广泛应用. 图基本上说明了当下流行的技术架构,其中Nginx有点入口网关的味道. 反向代 ...