Flink-v1.12官方网站翻译-P007-Data Pipelines & ETL
数据管道和ETL

对于Apache Flink来说,一个非常常见的用例是实现ETL(提取、转换、加载)管道,从一个或多个源中获取数据,进行一些转换和/或丰富,然后将结果存储在某个地方。在这一节中,我们将看看如何使用Flink的DataStream API来实现这种应用。
请注意,Flink的Table和SQL API很适合许多ETL用例。但无论你最终是否直接使用DataStream API,对这里介绍的基础知识有一个扎实的理解都会证明是有价值的。
无状态转换
本节介绍了map()和flatmap(),它们是用来实现无状态转换的基本操作。本节中的例子假设你熟悉flink-training repo中的实战练习中使用的出租车乘车数据。
map()
在第一个练习中,你过滤了一个打车事件流。在同一个代码库中,有一个GeoUtils类,它提供了一个静态方法GeoUtils.mapToGridCell(float lon, float lat),该方法将一个位置(经度、纬度)映射到一个网格单元,该单元指的是一个大约100x100米大小的区域。
现在让我们通过为每个事件添加startCell和endCell字段来丰富我们的打车对象流。你可以创建一个EnrichedRide对象,扩展TaxiRide,添加这些字段。
public static class EnrichedRide extends TaxiRide {
public int startCell;
public int endCell;
public EnrichedRide() {}
public EnrichedRide(TaxiRide ride) {
this.rideId = ride.rideId;
this.isStart = ride.isStart;
...
this.startCell = GeoUtils.mapToGridCell(ride.startLon, ride.startLat);
this.endCell = GeoUtils.mapToGridCell(ride.endLon, ride.endLat);
}
public String toString() {
return super.toString() + "," +
Integer.toString(this.startCell) + "," +
Integer.toString(this.endCell);
}
}
然后,您可以创建一个应用程序,将流转化为
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...)); DataStream<EnrichedRide> enrichedNYCRides = rides
.filter(new RideCleansingSolution.NYCFilter())
.map(new Enrichment()); enrichedNYCRides.print();
用这个MapFunction
public static class Enrichment implements MapFunction<TaxiRide, EnrichedRide> {
@Override
public EnrichedRide map(TaxiRide taxiRide) throws Exception {
return new EnrichedRide(taxiRide);
}
}
flatmap()
MapFunction 只适用于执行一对一的转换:对于每一个进入的流元素,map()将发出一个转换后的元素。否则,你将需要使用flatmap()
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...)); DataStream<EnrichedRide> enrichedNYCRides = rides
.flatMap(new NYCEnrichment()); enrichedNYCRides.print();
加上FlatMapFunction:
public static class NYCEnrichment implements FlatMapFunction<TaxiRide, EnrichedRide> {
@Override
public void flatMap(TaxiRide taxiRide, Collector<EnrichedRide> out) throws Exception {
FilterFunction<TaxiRide> valid = new RideCleansing.NYCFilter();
if (valid.filter(taxiRide)) {
out.collect(new EnrichedRide(taxiRide));
}
}
}
通过这个接口提供的Collector,flatmap()方法可以随心所欲地发射许多流元素,包括完全不发射。
key系列流处理函数
keyBy()
通常,能够围绕一个属性对一个流进行分区是非常有用的,这样所有具有相同属性值的事件就会被归为一组。例如,假设你想找到从每个网格单元开始的最长的出租车乘车时间。从SQL查询的角度考虑,这意味着要对startCell进行某种GROUP BY,而在Flink中,这是用keyBy(KeySelector)来完成的。
rides
.flatMap(new NYCEnrichment())
.keyBy(enrichedRide -> enrichedRide.startCell)
每一个keyBy都会引起一次网络洗牌,对流进行重新分区。一般来说,这是很昂贵的,因为它涉及到网络通信以及序列化和反序列化。
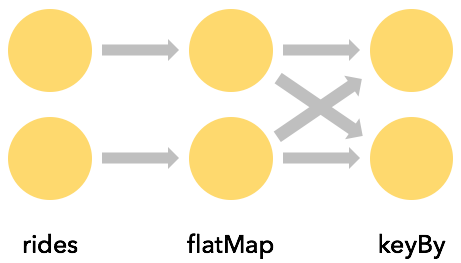
键的计算
KeySelectors并不局限于从你的事件中提取一个键。相反,它们可以用任何你想要的方式来计算键,只要产生的键是确定性的,并且有有效的hashCode()和equals()的实现。这个限制排除了生成随机数,或者返回数组或枚举的KeySelectors,但是你可以使用Tuples或POJOs来生成复合键,例如,只要它们的元素遵循这些相同的规则。
键必须以确定性的方式产生,因为每当需要它们时,它们就会被重新计算,而不是附加到流记录上。
例如,我们不是创建一个新的EnrichedRide类,该类有一个startCell字段,然后我们将其作为键通过
keyBy(enrichedRide -> enrichedRide.startCell)我们可以这样做
keyBy(ride -> GeoUtils.mapToGridCell(ride.startLon, ride.startLat))键函数处理后的流上的聚合
这段代码为每个骑行结束事件创建一个新的元组流,其中包含startCell和持续时间(分钟)。
import org.joda.time.Interval; DataStream<Tuple2<Integer, Minutes>> minutesByStartCell = enrichedNYCRides
.flatMap(new FlatMapFunction<EnrichedRide, Tuple2<Integer, Minutes>>() { @Override
public void flatMap(EnrichedRide ride,
Collector<Tuple2<Integer, Minutes>> out) throws Exception {
if (!ride.isStart) {
Interval rideInterval = new Interval(ride.startTime, ride.endTime);
Minutes duration = rideInterval.toDuration().toStandardMinutes();
out.collect(new Tuple2<>(ride.startCell, duration));
}
}
});
现在可以产生一个流,其中只包含那些对每个startCell来说是有史以来(至此)最长的乘车记录。
有多种方式可以表达作为键的字段。之前你看到了一个EnrichedRide POJO的例子,在这个例子中,要用作键的字段是用它的名字指定的。这个例子涉及到Tuple2对象,元组中的索引(从0开始)被用来指定键。
minutesByStartCell
.keyBy(value -> value.f0) // .keyBy(value -> value.startCell)
.maxBy(1) // duration
.print();
现在,每当持续时间达到一个新的最大值时,输出流就会包含一个针对每个键的记录--如这里的50797单元格所示。
...
4> (64549,5M)
4> (46298,18M)
1> (51549,14M)
1> (53043,13M)
1> (56031,22M)
1> (50797,6M)
...
1> (50797,8M)
...
1> (50797,11M)
...
1> (50797,12M)(隐含)状态
这是本次训练中第一个涉及有状态流的例子。虽然状态被透明地处理,但Flink必须跟踪每个不同键的最大持续时间。
每当状态涉及到你的应用时,你应该考虑状态可能会变得多大。每当键空间是无限制的,那么Flink需要的状态量也是无限制的。
当处理流时,一般来说,在有限的窗口上考虑聚合比在整个流上考虑更有意义。
reduce()和其他聚合函数
上文中使用的maxBy()只是Flink的KeyedStreams上众多聚合函数中的一个例子。还有一个更通用的reduce()函数,你可以用它来实现自己的自定义聚合。
有状态转换
为什么Flink参与管理状态?
你的应用程序当然能够使用状态,而不需要让Flink参与管理它--但Flink为它管理的状态提供了一些引人注目的功能。
- 本地化。Flink状态被保存在处理它的机器的本地,并且可以以内存速度进行访问。
- 耐用。Flink状态是容错的,即每隔一段时间就会自动检查一次,一旦失败就会恢复。
- 纵向可扩展。Flink状态可以保存在嵌入式RocksDB实例中,通过增加更多的本地磁盘来扩展。
- 横向可扩展。随着集群的增长和收缩,Flink状态会被重新分配。
- 可查询。Flink状态可以通过可查询状态API进行外部查询。
在本节中,您将学习如何使用Flink的API来管理键控状态。
丰富的其他函数
此时你已经看到了Flink的几个函数接口,包括FilterFunction、MapFunction和FlatMapFunction。这些都是单一抽象方法模式的例子。
对于每一个接口,Flink还提供了一个所谓的 "富 "变体,例如,RichFlatMapFunction,它有一些额外的方法,包括。
- open(Configuration c)
- close()
- getRuntimeContext()
open()在操作者初始化期间被调用一次。这是一个加载一些静态数据的机会,或者打开一个外部服务的连接,例如。
getRuntimeContext()提供了对一整套潜在有趣的东西的访问,但最值得注意的是它是如何创建和访问由Flink管理的状态。
一个带有键控状态的例子
在这个例子中,想象一下,你有一个事件流,你想去掉重复,所以你只保留每个键的第一个事件。这里有一个应用程序可以做到这一点,使用一个名为Deduplicator的RichFlatMapFunction。
private static class Event {
public final String key;
public final long timestamp;
...
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new EventSource())
.keyBy(e -> e.key)
.flatMap(new Deduplicator())
.print();
env.execute();
}
为了达到这个目的,Deduplicator将需要以某种方式记住,对于每个键来说,是否已经有了该键的事件。它将使用Flink的键控状态接口来做到这一点。
当你在使用像这样的键控流时,Flink将为每个被管理的状态项目维护一个键/值存储。
Flink支持几种不同类型的键控状态,本例使用的是最简单的一种,即ValueState。这意味着对于每个键,Flink将存储一个单一的对象--在本例中,一个类型为Boolean的对象。
我们的Deduplicator类有两个方法:open()和flatMap()。open方法通过定义一个ValueStateDescriptor<Boolean>来建立对托管状态的使用。构造函数的参数为这个键控状态项指定了一个名称("keyHasBeenSeen"),并提供了可用于序列化这些对象的信息(在本例中,Types.BOOLEAN)。
public static class Deduplicator extends RichFlatMapFunction<Event, Event> {
ValueState<Boolean> keyHasBeenSeen;
@Override
public void open(Configuration conf) {
ValueStateDescriptor<Boolean> desc = new ValueStateDescriptor<>("keyHasBeenSeen", Types.BOOLEAN);
keyHasBeenSeen = getRuntimeContext().getState(desc);
}
@Override
public void flatMap(Event event, Collector<Event> out) throws Exception {
if (keyHasBeenSeen.value() == null) {
out.collect(event);
keyHasBeenSeen.update(true);
}
}
}
当flatMap方法调用keyHasBeenSeen.value()时,Flink的运行时会在上下文中查找key的这块状态值,只有当它为null时,它才会去收集事件到输出。在这种情况下,它还会将keyHasBeenSeen更新为true。
这种访问和更新key-partitioned状态的机制可能看起来相当神奇,因为在我们的Deduplicator的实现中,key并不是显式可见的。当Flink的运行时调用我们的RichFlatMapFunction的open方法时,没有任何事件,因此那一刻上下文中没有key。但是当它调用flatMap方法时,被处理的事件的key对运行时来说是可用的,并在幕后用于确定Flink的状态后端中的哪个条目被操作。
当部署到分布式集群时,会有很多这个Deduplicator的实例,每个实例将负责整个键空间的一个不相干子集。因此,当你看到一个ValueState的单项,如
ValueState<Boolean> keyHasBeenSeen;
了解,这代表的不仅仅是一个布尔值,而是一个分布式的、碎片化的、键/值存储。
清理状态
上面的例子有一个潜在的问题。如果键的空间是无限制的,会发生什么?Flink是在某个地方为每一个被使用的不同键存储一个布尔的实例。如果有一个有界的键集,那么这将是很好的,但是在键集以无界的方式增长的应用中,有必要为不再需要的键清除状态。这是通过调用状态对象上的clear()来实现的,如
keyHasBeenSeen.clear()
例如,你可能想在给定键的一段时间不活动后这样做。当你在事件驱动的应用程序一节中学习ProcessFunctions时,你将看到如何使用Timer来实现这一点。
此外,还有一个状态活用时间(TTL)选项,你可以用状态描述符来配置,指定什么时候自动清除陈旧钥匙的状态。
没有键的状态
也可以在非键的上下文中使用托管状态。这有时被称为操作者状态。所涉及的接口有些不同,由于用户定义的函数需要非键控状态是不常见的,所以这里不做介绍。这个功能最常用于源和汇的实现。
连接流
有时不是应用这样的预定义变换。

你希望能够动态地改变变换的某些方面--通过流的阈值,或规则,或其他参数。Flink中支持这种模式的是一种叫做连接流的东西,其中一个操作者有两个输入流,就像这样。
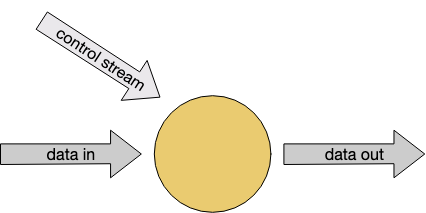
连接的流也可以用来实现流式连接。
例子
在这个例子中,控制流被用来指定必须从streamOfWords中过滤掉的单词。一个名为ControlFunction的RichCoFlatMapFunction被应用到连接的流中来完成这个任务。
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> control = env.fromElements("DROP", "IGNORE").keyBy(x -> x);
DataStream<String> streamOfWords = env.fromElements("Apache", "DROP", "Flink", "IGNORE").keyBy(x -> x);
control
.connect(datastreamOfWords)
.flatMap(new ControlFunction())
.print();
env.execute();
}
注意,被连接的两个流必须以兼容的方式进行键控。keyBy的作用是对流的数据进行分区,当键控流连接时,必须以同样的方式进行分区。这样就可以保证两个流中具有相同key的事件都会被发送到同一个实例中。那么,这就使得将该键上的两个流连接起来成为可能,例如。
在这种情况下,两个流的类型都是DataStream<String>,并且两个流都以字符串为键。如下图所示,这个RichCoFlatMapFunction在键值状态下存储了一个布尔值,而这个布尔值是由两个流共享的。
public static class ControlFunction extends RichCoFlatMapFunction<String, String, String> {
private ValueState<Boolean> blocked;
@Override
public void open(Configuration config) {
blocked = getRuntimeContext().getState(new ValueStateDescriptor<>("blocked", Boolean.class));
}
@Override
public void flatMap1(String control_value, Collector<String> out) throws Exception {
blocked.update(Boolean.TRUE);
}
@Override
public void flatMap2(String data_value, Collector<String> out) throws Exception {
if (blocked.value() == null) {
out.collect(data_value);
}
}
}
RichCoFlatMapFunction是FlatMapFunction的一种,它可以应用于一对连接的流,并且它可以访问富函数接口。这意味着它可以被做成有状态的。
屏蔽的布尔正在被用来记住控制流上提到的键(词,在这里),这些词被过滤出streamOfWords流。这就是键状态,它在两个流之间是共享的,这就是为什么两个流要共享同一个键空间。
flatMap1和flatMap2被Flink运行时调用,分别来自两个连接流的元素--在我们的例子中,来自控制流的元素被传入flatMap1,来自streamOfWords的元素被传入flatMap2。这是由使用 control.connect(datastreamOfWords) 连接两个流的顺序决定的。
重要的是要认识到,你无法控制调用flatMap1和flatMap2回调的顺序。这两个输入流在相互竞争,Flink运行时将对来自一个流或另一个流的事件的消耗做它想做的事。在时间和/或顺序很重要的情况下,你可能会发现有必要在托管的Flink状态下缓冲事件,直到你的应用程序准备好处理它们。(注意:如果你真的很绝望,可以通过使用实现InputSelectable接口的自定义操作员来对双输入操作符消耗输入的顺序进行一些有限的控制。)
实践
与本节配套的实践练习是《乘车与票价》练习。
下一步阅读什么?
Flink-v1.12官方网站翻译-P007-Data Pipelines & ETL的更多相关文章
- Flink-v1.12官方网站翻译-P005-Learn Flink: Hands-on Training
学习Flink:实践培训 本次培训的目标和范围 本培训介绍了Apache Flink,包括足够的内容让你开始编写可扩展的流式ETL,分析和事件驱动的应用程序,同时省略了很多(最终重要的)细节.本书的重 ...
- Flink-v1.12官方网站翻译-P025-Queryable State Beta
可查询的状态 注意:可查询状态的客户端API目前处于不断发展的状态,对所提供接口的稳定性不做保证.在即将到来的Flink版本中,客户端的API很可能会有突破性的变化. 简而言之,该功能将Flink的托 ...
- Flink-v1.12官方网站翻译-P002-Fraud Detection with the DataStream API
使用DataStream API进行欺诈检测 Apache Flink提供了一个DataStream API,用于构建强大的.有状态的流式应用.它提供了对状态和时间的精细控制,这使得高级事件驱动系统的 ...
- Flink-v1.12官方网站翻译-P029-User-Defined Functions
用户自定义函数 大多数操作都需要用户定义的函数.本节列出了如何指定这些函数的不同方法.我们还涵盖了累加器,它可以用来深入了解您的Flink应用. Lambda函数 在前面的例子中已经看到,所有的操作都 ...
- Flink-v1.12官方网站翻译-P016-Flink DataStream API Programming Guide
Flink DataStream API编程指南 Flink中的DataStream程序是对数据流实现转换的常规程序(如过滤.更新状态.定义窗口.聚合).数据流最初是由各种来源(如消息队列.套接字流. ...
- Flink-v1.12官方网站翻译-P015-Glossary
术语表 Flink Application Cluster Flink应用集群是一个专用的Flink集群,它只执行一个Flink应用的Flink作业.Flink集群的寿命与Flink应用的寿命绑定. ...
- Flink-v1.12官方网站翻译-P010-Fault Tolerance via State Snapshots
通过状态快照进行容错 状态后台 Flink管理的键控状态是一种碎片化的.键/值存储,每项键控状态的工作副本都被保存在负责该键的任务管理员的本地某处.操作员的状态也被保存在需要它的机器的本地.Flink ...
- Flink-v1.12官方网站翻译-P008-Streaming Analytics
流式分析 事件时间和水印 介绍 Flink明确支持三种不同的时间概念. 事件时间:事件发生的时间,由产生(或存储)该事件的设备记录的时间 摄取时间:Flink在摄取事件时记录的时间戳. 处理时间:您的 ...
- Flink-v1.12官方网站翻译-P006-Intro to the DataStream API
DataStream API介绍 本次培训的重点是广泛地介绍DataStream API,使你能够开始编写流媒体应用程序. 哪些数据可以流化? Flink的DataStream APIs for Ja ...
随机推荐
- 一文教你轻松搞定ANR异常捕获与分析方法
1. ANR 产生原理 关于 ANR 的触发原因,Android 官方开发者文档中 "What Triggers ANR?" 有介绍,如下: Generally, the syst ...
- PO,BO,VO,DTO,POJO,DAO,DO是什么?
PO (Persistent Object) 持久化对象,表示实体数据.BO (Business Object) 业务对象,主要是把逻辑业务封装为一个对象 .VO (Value/Vi ...
- 【函数分享】每日PHP函数分享(2021-1-7)
ltrim() 删除字符串开头的空白字符(或其他字符). string ltrim ( string $str[, string $character_mask]) 参数描述str 输入的字符串. c ...
- tf.argmax(vector,axis)函数的使用
1.返回值 vector为向量,返回行或列的最大值的索引号: vector为矩阵,返回值是向量,返回每行或每列的最大值的索引号. 2.参数 vector为向量或者矩阵 axis = 0 或1 0:返回 ...
- TCP/IP五层模型-应用层-DNS协议
1.定义:域名解析协议,把域名解析成对应的IP地址. 2.分类:①迭代解析:DNS所在服务器若没有可以响应的结果,会向客户机提供其他能够解析查询请求的DNS服务器地址,当客户机发送查询请求时,DNS ...
- 【ORA】ORA-01756: quoted string not properly terminated
出现ORA-01756: quoted string not properly terminated 后,查看SQL是否有中文符号 修改为英文的符号,运行正常
- 目录遍历 - Pikachu
概述: 在web功能设计中,很多时候我们会要将需要访问的文件定义成变量,从而让前端的功能便的更加灵活. 当用户发起一个前端的请求时,便会将请求的这个文件的值(比如文件名称)传递到后台,后台再执行其对应 ...
- mysql—group_concat函数
MySQL中的group_concat函数的使用方法,比如select group_concat(name) . 完整的语法如下: group_concat([DISTINCT] 要连接的字段 [Or ...
- Effective Java, 3e阅读笔记一
引言 本书的目标是帮助读者更加有效地使用Java编程语言及其基本类库,适用于任何具有实际Java工作经验的程序员. 本书一共90个条目,12章,每个条目讨论一条规则,这些规则反映了最有经验的优秀程序员 ...
- css-前端实现左中右三栏布局的常用方法:绝对定位,圣杯,双飞翼,flex,table-cell,网格布局等
1.前言 作为一个前端开发人员,工作学习中经常会遇到快速构建网页布局的情况,这篇我整理了一下我知道的一些方法.我也是第一次总结,包括圣杯布局,双飞翼布局,table-cell布局都是第一次听说,可能会 ...