Redis5设计与源码分析读后感(四)压缩列表
一、引言
上一节我们总结了跳跃表的知识,我们知道了有序数组可以用跳跃表实现,也可以用压缩列表来实现,这一篇文章我们来总结一下压缩列表相关的知识。
二、压缩列表简介
定义:压缩列表 ziplist 本质上是一个字节数组,每个元素可以是一个字节数组或一个整数。
PS:Redis的有序集合、散列、列表都直接或间接用到了压缩列表。
三、压缩列表的存储结构
我们通过一张图来直观地分析压缩列表的结构:

- zlbytes :压缩列表的字节长度,占4个字节,因此压缩列表最多有232-1个字节 。
- zltail :压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节。
- zllen :压缩列表的元素个数,占2个字节。zllen无法储存元素个数超过65535(216-1)的压缩列表。
- entryX:压缩列表储存的元素,可以是字节数组或者整数,长度不限。
- zlend:压缩列表的结尾,占1个字节,恒为0xFF。
PS:1字节=8位,二进制里,每位对应2的n次方,1字节最大值为28-1个元素。
PS:必须遍历整个压缩列表才能获取到元素个数。
四、压缩列表的元素的结构
还是通过一张图来说明就比较直观一些:

- previous_entry_length :表示前一个元素的字节长度,占用1个字节或者5个字节,根据前一个元素的长度大小来定:
- 小于254字节 :用1个字节表示previous_entry_length
- 大于或等于254字节 :用5个字节表示previous_entry_length,此时previous_entry_length的第一个字节为固定的0xFE,后面4个字节才真正表示前一个元素的长度。
- encoding :表示当前元素的编码,即content字段储存的数据类型(整数或者字节数组)占用1、2或5个字节,根据content类型来定【详见压缩列表的元素编码表】
- content :储存数据内容,长度不限
PS:假设已知当前元素的首地址p,就可以根据 p-previous_entry_length 推算出前一个元素的首地址。
压缩列表的元素编码
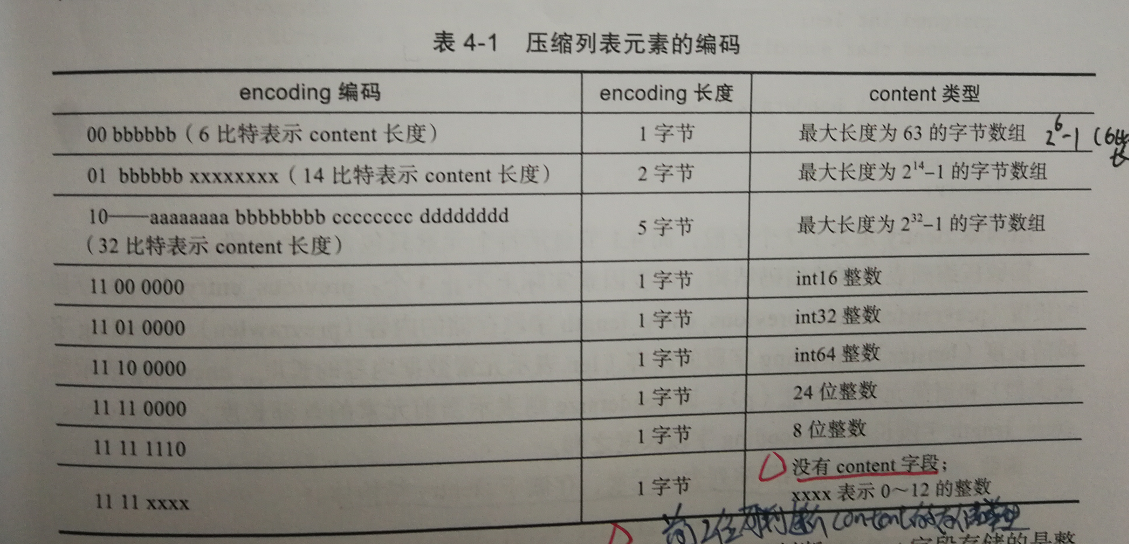
简单总结一下:
- 前两位 :判断类型(整数 OR 字节数组)PS:若为字节数组还可根据前两位判断最大长度
- 字节数组时 :后面的位数标识字节数组的实际长度(2n-1)
- 整数时 :3、4位判断类型,后4为用于表示整数值
五、结构体
意义:由于每次获取前一个元素的内容都需要经过复杂的解码运算,影响效率,所以定义结构体 zlentry 用于表示解码后的压缩列表元素。
PS:结构体实际上是对每个元素的首部【 previous_entry_length 和 encoding 】结构的细分描述。
结构体的字段
- prevrawlensize :previous_entry_length 字段的长度
- prevrawlen :previous_entry_length 字段的内容
- lensize :encoding 字段的长度
- encoding :表示数据类型
- len :数据内容的长度
- p :当前元素的首地址
- headersize :当前元素的首部长度【 previous_entry_length + encoding 】
解码步骤
解码主要用到的是 zipEntry 方法,解码出来的信息储存于 zlentry 结构体:
- 1、解码元素的 previous_entry_length 字段
- 2、解码元素的 encoding 字段
- 3、设置好结构体的相关字段
六、创建压缩列表
创建压缩列表主要用到的方法为:ziplistNew【返回参数为压缩列表的首地址】
创建一个空的压缩列表需要分配的初始空间为:11(4+4+2+1)个字节:
- 4 :zlbytes【压缩列表的字节长度:4字节】
- 4 :zltail【尾元素对起始地址的偏移量:4字节】
- 2 :zlbytes【压缩列表的元素个数:2字节】
- 1 :zlbytes【压缩列表的结尾,固定0xFF:1字节】
七、插入元素
插入元素主要用到的方法为:ziplistInsert【返回参数为压缩列表的首地址】
步骤:
- 将元素内容编码
- 重新分配空间
- 复制数据
将元素内容编码
含义:将元素内容编码就是计算 previous_entry_length 字段、 encoding 字段、 content 字段的内容。
计算前一个元素的长度又根据插入位置分为三种情况:

- P0【插入第一个元素】 :即不存在前一个元素,则 previous_entry_length 为0。
- P1【插入列表中间】 :则entryX+1储存的 previous_entry_length 就是entryX元素的长度,也就是我们需要的长度。
- P1【插入列表末尾】 :则需要进行解码操作,参考上面的解码步骤
重新分配空间
首先定义几个变量:
- curlen :插入元素前列表的长度
- reqlen :新插入元素的长度
- nextdiff :entryX+1元素长度的变化
- forcelarge :标识当nextdiff=4而reqlen<4的情况
PS:需要考虑连锁更新的情况~
详见书本解释~
数据复制
含义:插入元素以后,插入点之后的元素都要向后进行移动,此时底层实现为复制元素到新的内存地址上。
几个名词:
- 偏移量 :待插入元素entryNew的长度
- 移动的数据块长度 :插入位置P后所有元素长度之和 + nextdiff
PS:数据移动之后还需要更新entryX+1元素的 previous_entry_length 字段
八、删除元素
删除元素主要用到的方法为:ziplistDelete【返回参数为压缩列表的首地址】
步骤:
- 计算待删除元素的总长度
- 复制数据
- 重新分配空间
PS:新增元素是从新分配空间小于指针指向的空间时,可能会出现问题;而删除元素时,内存空间是肯定减小的,但是由于是先复制数据再发分配空间,则多余空间的数据已经复制好了,所以从新分配空间就不会产生这个问题。
九、遍历压缩列表
向前遍历:
- 通过 previous_entry_length 字段可以计算前一个元素的首地址,则相对容易遍历
向后遍历:
- 解码当前元素
- 计算当前元素长度
- 获取到最后一个元素的首地址
十、连锁更新
连锁更新其实很好理解,就是更新一个元素的同时引发其他元素的同时更新,这种现象就叫连锁更新:
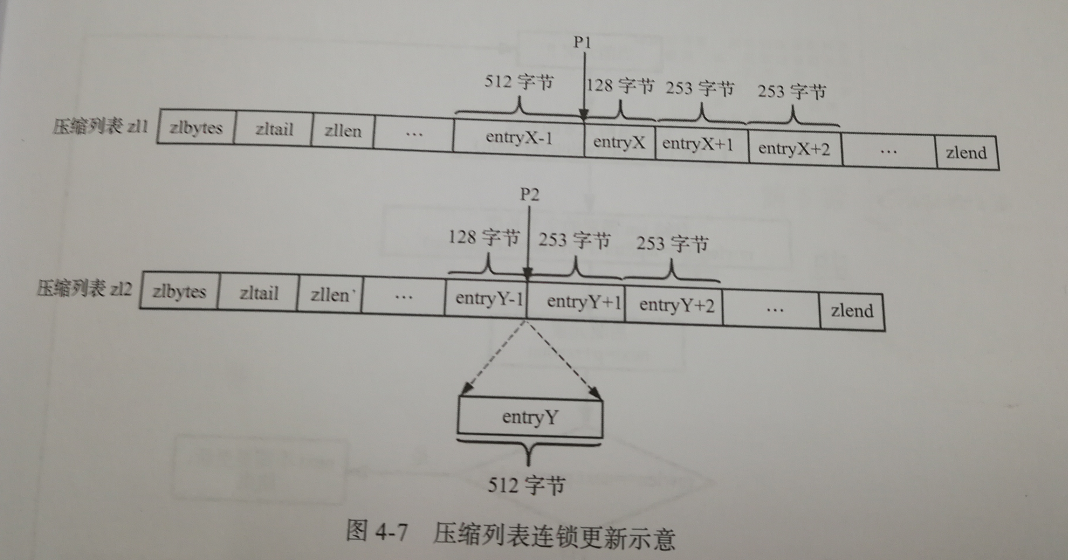
我们可以看到,当在以下两种情况:
- P1位置删除entryX元素
- P2位置插入entryY元素
都会导致连锁更新的发生,为什么呢?
P1位置删除entryX元素
① 删除前,entryX的长度是128字节,所以entryX+1的 previous_entry_length 字段只需要1个字节就可以储存。
② 但是当删除了entryX元素时,entryX+1的前一个元素变成了entryX-1,而entryX-1的长度为512字节,所以此时entryX+1的 previous_entry_length 字段需要用5个字节来储存
③ entryX+1的 previous_entry_length 字段从1个字节变成5个字节以后,entryX+1的长度变成257字节,同时引发entryX+2也需要去改变它的 previous_entry_length 字段长度,从而引发连锁更新...
P2位置插入entryY元素
与上面类似,就不再过多描述了。
Redis5设计与源码分析读后感(四)压缩列表的更多相关文章
- Redis5设计与源码分析读后感(一)认识Redis
一.初识redis 定义 Redis是一个开源的Key-Value数据库,通常被称为数据结构服务器,其值可以是多种常见的数据格式,且读写性能极高,且所有操作都是原子性的. 高性能的主要原因 1.基于内 ...
- Redis5设计与源码分析读后感(三)跳跃表
一.引言 有序集合在日常开发中相当常见,比如做排名等相关的功能,肯定要用到排序的功能,那么常见底层实现有很多种: 数组 :不便于元素的插入和删除 链表 :查询效率低,需要遍历所有元素 平衡树OR红黑树 ...
- Redis5设计与源码分析读后感(二)简单动态字符串SDS
一.引言 学习之前先了解几个概念: SDS定义:简单动态字符串,Redis的基本数据结构之一,用于储存字符串和整型数据. 二进制安全:C语言中用"\0"表示字符串结束,如果字符串本 ...
- ABP源码分析十四:Entity的设计
IEntity<TPrimaryKey>: 封装了PrimaryKey:Id,这是一个泛型类型 IEntity: 封装了PrimaryKey:Id,这是一个int类型 Entity< ...
- Docker源码分析(四):Docker Daemon之NewDaemon实现
1. 前言 Docker的生态系统日趋完善,开发者群体也在日趋庞大,这让业界对Docker持续抱有极其乐观的态度.如今,对于广大开发者而言,使用Docker这项技术已然不是门槛,享受Docker带来的 ...
- Heritrix源码分析(十四) 如何让Heritrix不间断的抓取(转)
欢迎加入Heritrix群(QQ):109148319,10447185 , Lucene/Solr群(QQ) : 118972724 本博客已迁移到本人独立博客: http://www.yun5u ...
- Heritrix源码分析(十四)
近段时间在搞定Lucene的一些问题,所以Heritrix源码分析暂时告一段落.今天下午在群里有同学提到了Heritrix异常终止的问题以及让Heritrix不停的抓取(就是抓完一遍后载入种子继续抓取 ...
- Java集合源码分析(四)HashMap
一.HashMap简介 1.1.HashMap概述 HashMap是基于哈希表的Map接口实现的,它存储的是内容是键值对<key,value>映射.此类不保证映射的顺序,假定哈希函数将元素 ...
- 插件开发之360 DroidPlugin源码分析(四)Activity预注册占坑
请尊重分享成果,转载请注明出处: http://blog.csdn.net/hejjunlin/article/details/52258434 在了解系统的activity,service,broa ...
随机推荐
- python 判断文件和文件夹是否存在、创建文件夹
原文链接:https://www.cnblogs.com/hushaojun/p/4533241.html >>> import os >>> os.path.ex ...
- Robot Framework(2)——简单运行案例
1.打开RIDE 之前介绍的3种方式都可以 2.创建工程和测试套件 1>点击File-New Project ①Name:工程命名 ②Parent Directory:上级目录,工程会创建在这个 ...
- Federated Learning with Matched Averaging
挖个坑吧,督促自己仔细看一遍论文(ICLR 2020),看看自己什么时候也能中上那么一篇(流口水)~ 郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract 联邦学习允许边缘设 ...
- 循序渐进VUE+Element 前端应用开发(19)--- 后端查询接口和Vue前端的整合
循序渐进VUE+Element 前端应用开发的系列文章中,前面介绍了系统各个功能的处理实现,本篇随笔从一个主线上介绍前后端开发的整合,让我们从ABP框架后端的查询接口的处理,前端API接口调用的封装, ...
- 第3关-input()函数
第3关-input()函数 一.input()函数 import time print('亲爱的同学:') time.sleep(1) print('我们愉快地通知您,您已获准在霍格沃茨魔法学校就读. ...
- Tensorflow2(二)tf.data输入模块
代码和其他资料在 github 一.tf.data模块 数据分割 import tensorflow as tf dataset = tf.data.Dataset.from_tensor_slice ...
- shell脚本同步私人git仓库
前言 分别在个人电脑.个人服务器.码云三个地方建立了数据仓库用于保存自己的各种数据,通过git+shell进行数据同步. 此举不仅可以避免因存储损坏.版本更迭.数据误操作等因素带来的各种麻烦,也能实现 ...
- drf中View和router的详解
Rest Framework 视图和路由 因为涉及到视图层面了,而且下面的例子会反复用到request.data,所以我决定带大家稍微看下源码,感兴趣的可以自己深入了解 无论是View还是APIVie ...
- linux网络配置及虚拟机连接不上网排错思路
第1章 操作系统与虚拟软件的使用 1.1 虚拟软件使用方法 Vmware 1.1.1 开启vmware 注: 同时只能开启一个VMware软件,如果开了两个VMware窗口 提示 ...
- 使用服务进程启动asp.net core程序
昨天在PuTTY中启动了测试网站,因为时间太晚,看到效果,立马关机睡觉,刚上床又想看看手机端访问效果,结果一打开,发现nginx找不到页面,意识到应该是退出PuTTY导致进程结束,于是今天赶紧查了解决 ...