机器学习算法-PCA降维技术
机器学习算法-PCA降维
一、引言
在实际的数据分析问题中我们遇到的问题通常有较高维数的特征,在进行实际的数据分析的时候,我们并不会将所有的特征都用于算法的训练,而是挑选出我们认为可能对目标有影响的特征。比如在泰坦尼克号乘员生存预测的问题中我们会将姓名作为无用信息进行处理,这是我们可以从直观上比较好理解的。但是有些特征之间可能存在强相关关系,比如研究一个地区的发展状况,我们可能会选择该地区的GDP和人均消费水平这两个特征作为一个衡量指标。显然这两者之间是存在较强的相关关系,他们描述的都是该地区的经济状况,我们是否能够将他们转成一个特征呢?这样就能达到降低特征维度的特征,同时也能够避免因特征过多而产生的过拟合问题。
二、PCA降维技术
用于给数据降低维度的方法大致有三种,主成分分析法、因子分析法、独立成分分析法。由于主成分分析法在三者之中使用的比较多,这里我们只对主成分分析进行深入探讨。
2.1 PCA算法思想
在主成分分析中,通过坐标变化将原来的坐标系转化到新的坐标系。新坐标的坐标轴的选择是与原始数据有关的,第一个坐标轴选择的是原始数据中方差最大的方向,第二个坐标轴的选择和第一个坐标正交且具有最大方差,这样一直重复,直到坐标维数与数据的特征维数相同。可以发现,大部分的方差都包含在前面的几个新的坐标轴中。因此可以忽略余下的坐标轴,这样就对数据进行了一个降维。
2.2 PCA算法的计算方法
首先我们来介绍一些PCA的计算方法,在这之后我们将从数学上来对PCA算法进行分析。
PCA的计算过程如下:
Ste1:去除每维特征的均值,目的是将数据的中心移动到原点上。
Ste2:计算协方差矩阵。
Ste3:计算协方差矩阵的特征值和特征向量。
Ste4:将特征值从大到小序,找出其中最上面的N个特征向量。
Step5:将原始数据转换到上述N个特征向量构建的新的空间中去。
通过以上5个步骤,我们就能将原始数据降低到我们想要达到的维度。主成分分析的主要思想是基于方差最大、维度最小理论,因此我们可以通过计算累计贡献率来来确定N的值的大小。定义贡献率如下:
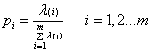
其中λ(i)表示的为第i个维度对应的特征值。我们可以设置适当的阈值,一般为0.8,如果前N个特征值的贡献率之和达到该阈值,我们就可以认为N维代表了原始数据的主要信息。
2.3 PCA技术的数学原理
在上一节中我们已经讨论了PCA的计算方法,下面我们将讨论为什么要这计算。在信号处理中认为信号具有较大的方差,而噪声具有较小的方差。信噪比表示的是信号方差与噪声方差之比。信噪比越高则表数据越好。通过坐标变换,我们可以计算在新坐标下每一个维度的方差,如果变换后某一个坐标轴上的方差很小我们就可以认为该维特征是噪声及干扰特征。因此坐标变换最好的方式就是
将变换之后N维特征的每一维方差都很大。
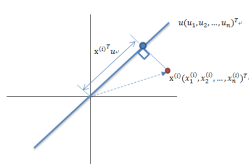
图1
如图1所示蓝色加粗线条表示坐标变化之后的某个维度,表示经过去除平均值之后的数据的第i个样本,u是该维度的方向向量,表示的是在该维度上到原点的距离。现在我们要做的就是找出u使得数据在该维度上投影的方差之和最大。由于经过去除平均值处理之后的平均值为0,容易证明它们在任何方向上的投影的平均值也为0.因此在u方向的方差之后为:
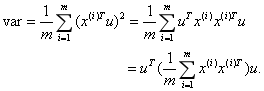
上式中的中间部分正好表示的就是样本特征的协方差矩阵如果用λ表示var,用 表示
表示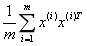 ,那么上式就能够表示成为
,那么上式就能够表示成为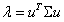 。根据特征值的的定义,λ就是
。根据特征值的的定义,λ就是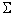 的一特征值,u就是特征向量。最佳的投影直线是特征值λ最大时对应的特征向量,依次类推。也就是说特征值的大小等价于归一化之后数据的的方差大小。因此我们只需要对协方差矩阵进行特征值分解,得到前N个特征值对应的特征向量,并且这N维新的特征是正交的。因此可以通过以下计算方式将n维原数据转化为新的N维数据:
的一特征值,u就是特征向量。最佳的投影直线是特征值λ最大时对应的特征向量,依次类推。也就是说特征值的大小等价于归一化之后数据的的方差大小。因此我们只需要对协方差矩阵进行特征值分解,得到前N个特征值对应的特征向量,并且这N维新的特征是正交的。因此可以通过以下计算方式将n维原数据转化为新的N维数据:
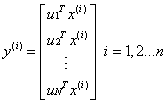
通过选取最大的前N维使得他们累计贡献率达到一定值,我们就能抛弃掉方差较小的特征,实现降维的目的。
2.4 PCA技术的python实现
定义函数PCA如下:
def pca(dataMat, minRation):
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #去除平均值
covMat = cov(meanRemoved,rowvar=0)#计算协方差矩阵
eigVals,eigVects = linalg.eig(mat(covMat))#计算特征值特征向量
eigValInd=argsort(-eigVals)#从小大到排序
ratio=0
topNfeat=1
for i in range(len(eigVals)):
index=eigValInd[i]
ratio=ratio+eigVals[index]#计算累计贡献率
topNfeat=i+1
if ratio>minRation:break
eigValInd=eigValInd[1:topNfeat+1]
redEigVects=eigVects[:,eigValInd]
lowDDataMat = meanRemoved * redEigVects#将数据转化到新的维度空间
return topNfeat lowDDataMat
该函数输入为一个原始矩阵,和累计贡献率的阈值。首先去除平均值,然后利用numy库提供的cov()函数计算去除平均值之后的数据的协方差矩阵。再通过linalg.eig()函数计算该协方差矩阵的特征值和特征向量。通过argsort函数对(-eigVals)进行排序,相当于对eigVals进行逆序排序,返回排序后的索引值。其中的循环是用来计算新空间下的维数,lowData是变换到新空间下的数据。最终该函数输出为变换后的数据,以及该空间的维数topNfeat。
三、PCA技术的应用
3.1 问题描述
延续之前的回声探测的问题,即从60个不同的方向对岩石进行测试,根据回声的结果来探测的物体是岩壁还是矿井。该数据集共有208个数据,每个数据的维度为60.
3.2 PCA降维处理
我们已经在adabost使用过这个例子,这次我们对进行PCA降维之后的数据再次用adabost算法,计算测试的准确率。测试的准确率及运行时间如下表。
|
累计贡献率阈值p |
处理后的维数N |
测试的平均准确率r |
程序平均时间t |
|
0.80 |
7 |
0.27 |
1.44 |
|
0.85 |
9 |
0.26 |
1.84 |
|
0.90 |
12 |
0.28 |
2.40 |
|
0.95 |
17 |
0.30 |
3.01 |
|
0.98 |
24 |
0.21 |
5.1 |
|
1.00 |
60 |
0.28 |
5.70 |
结果发现如果把累计贡献率设置为0.9则新的空间下的维度为19维,大大降低了数据的维度。而在相同的数据集上,降维之后算法的准确率几乎没有变化。这表明降维对于数据的处理是一种有效的手段。
四、总结
本文从方差理论的角度对CA降维技术的原理进行了分析,然后通过与之前Adaboost算法结合比较在降维前后算法准确率的变化。在本例中,数据集经降维处理之后在数据集上的准确率变化不大,但是时间却大大缩短了。当然,在其的数据上我也做过一些实验,发现有些数据算法效率能够显著提升,而有些则不能。因此降维技术并不是万能的,而是需要根据实际数据集进行分析是否适合使用。
机器学习算法-PCA降维技术的更多相关文章
- PCA降维技术
PCA降维技术 PCA 降维 Fly Time: 2017-2-28 主成分分析(PCA) PCA Algorithm 实例 主成分分析(PCA) 主成分分析(Principal Component ...
- [机器学习之13]降维技术——主成分分析PCA
始终贯彻数据分析的一个大问题就是对数据和结果的展示,我们都知道在低维度下数据处理比较方便,因而数据进行简化成为了一个重要的技术.对数据进行简化的原因: 1.使得数据集更易用使用.2.降低很多算法的计算 ...
- python机器学习使用PCA降维识别手写数字
PCA降维识别手写数字 关注公众号"轻松学编程"了解更多. PCA 用于数据降维,减少运算时间,避免过拟合. PCA(n_components=150,whiten=True) n ...
- 机器学习 - 算法 - PCA 主成分分析
PCA 主成分分析 原理概述 用途 - 降维中最常用的手段 目标 - 提取最有价值的信息( 基于方差 ) 问题 - 降维后的数据的意义 ? 所需数学基础概念 向量的表示 基变换 协方差矩阵 协方差 优 ...
- 数学之路(3)-机器学习(3)-机器学习算法-PCA
PCA 主成分分析(Principal components analysis,PCA),维基百科给出一个较容易理解的定义:“PCA是一个正交化线性变换,把数据变换到一个新的坐标系统中,使得这一数据的 ...
- 跟我学算法-PCA(降维)基本原理推导
Pca首先 1.对数据进行去均值 2.构造一个基本的协方差矩阵1/m(X)*X^T 3对协方差矩阵进行变化,得到对角化矩阵,即对角化上有数值,其他位置上的数为0(协方差为0),即求特征值和特征向量的过 ...
- 跟我学算法-pca(降维)
pca是一种黑箱子式的降维方式,通过映射,希望投影后的数据尽可能的分散, 因此要保证映射后的方差尽可能大,下一个映射的方向与当前映射方向正交 pca的步骤: 第一步: 首先要对当前数据(去均值)求协方 ...
- 机器学习算法总结(九)——降维(SVD, PCA)
降维是机器学习中很重要的一种思想.在机器学习中经常会碰到一些高维的数据集,而在高维数据情形下会出现数据样本稀疏,距离计算等困难,这类问题是所有机器学习方法共同面临的严重问题,称之为“ 维度灾难 ”.另 ...
- 机器学习实战基础(二十三):sklearn中的降维算法PCA和SVD(四) PCA与SVD 之 PCA中的SVD
PCA中的SVD 1 PCA中的SVD哪里来? 细心的小伙伴可能注意到了,svd_solver是奇异值分解器的意思,为什么PCA算法下面会有有关奇异值分解的参数?不是两种算法么?我们之前曾经提到过,P ...
随机推荐
- 测试window安装的客户端
1.win10 安装了客户端,测试一下,
- B树——插入和删除
B树--插入和删除 B树的插入 5阶B数--结点关键字个数向上取整m/2-1≤n≤m-1 即2≤n≤4 连续插入5个元素后,超出来了. 在插入key后,若导致原结点关键字数超过上限,则从中间位置(m/ ...
- Shiro实现Basic认证
前言 今天跟小伙伴们分享一个实战内容,使用Spring Boot+Shiro实现一个简单的Http认证. 场景是这样的,我们平时的工作中可能会对外提供一些接口,如果这些接口不做一些安全认证,什么人都可 ...
- mybatis默认返回类型
在mybatis中,无论你指定还是不指定返回类型,mybatis都会默认的先将查询回的值放入一个hashMap中(如果返回的值不止一条就是一个包含hashMap的list).这其中的区别在于,如果你指 ...
- WinForm引用ActiveX组件,对Com组件的学习
1.WinForm引用Adobe PDF Reader 工作中写WinForm程序经常会引用第三方的组件,包括引用Com组件,做了一个桌面程序需要展示PDF,看了些其它的开源组件对PDF的兼容性都不是 ...
- Core3.0发布到IIS的流程
前言 参考链接 https://www.cnblogs.com/wutongjun/p/11981798.html 在IIS上部署 .Net Core 3.0 项目的主要流程有: 安装并启用IIS 安 ...
- [leetcode]543. Diameter of Binary Tree二叉树的直径
题目中的直径定义为: 任意两个节点的最远距离 没想出来,看的答案 思路是:diameter = max(左子树diameter,右子树diameter,(左子树深度+右子树深度+1)) 遍历并更新结果 ...
- JDBC数据连接之增删改查MVC
每天叫醒自己的不是闹钟,而是梦想 conn层 package conn; import java.sql.Connection; import java.sql.DriverManager; impo ...
- 虚拟机安装Ubuntu 16.04系统实操教程 详尽步骤 vmware ESXi亲测通过
1 Ubuntu 16.04系统安装要求 Ubuntu 16.04 LTS下载最新版本的Ubuntu,适用于台式机和笔记本电脑. LTS代表长期支持,这意味着有五年免费安全和维护更新的保证. Ubun ...
- Thread.join详解
/** * 如果某个线程在另一个线程t上调用t.join:那么此线程将被挂起,直到目标t线程的结束才恢复即t.isAlive返回为假 * * @date:2018年6月27日 * @author:zh ...