std::thread线程库详解(3)
目录
前言
前两篇的博文分别介绍了标准库里面的线程和锁,这一次的博文将会介绍锁的管理。
锁在多线程编程中非常常用,但是一旦使用不谨慎就会导致很多问题,最常见的就是死锁问题。
lock_guard
std::lock_guard是最常见的管理锁的类,它会在初始化的时候自动加锁,销毁的时候自动解锁,需要锁的对象满足BasicLockable,即存在lock和unlock方法。测试代码:
void thread_func(int thread_id) {
{
std::lock_guard<std::mutex> guard(global_mutex);
std::cout << "Test 1:" << thread_id << std::endl;
std::this_thread::sleep_for(1s);
std::cout << "Test 2:" << thread_id << std::endl;
}
std::this_thread::sleep_for(0.5s);
std::cout << "Test 3:" << thread_id << std::endl;
}
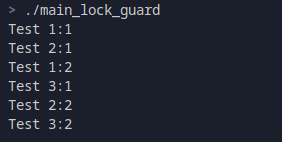
std::lock_guard在线程一开始的代码块就进行了初始化,global_mutex加锁,所以Test 1和Test 2会一起输出,而之后代码块结束,std::lock_guard作为区域变量,也在此时析构释放锁。其输出为
除此之外,std::lock_guard还允许输入第二个参数std::adopt_lock_t,这个参数表明该线程已经获取了该锁,所以在创建对象的时候不需要再获取锁。
std::lock_guard<std::mutex> lk(mutex1, std::adopt_lock);
scoped_lock (C++17)
这个类和std::lock_guard类似,不过其可以同时管理多把锁,可以同时给多把锁加锁。这个方法可以很好的解决哲学家就餐问题\(^1\)。
void thread_func(int thread_id, std::mutex &mutex1, std::mutex &mutex2) {
std::scoped_lock lock(mutex1, mutex2);
std::cout << "Thread " << thread_id << " is eating." << std::endl;
std::this_thread::sleep_for(1s);
std::cout << "Thread " << thread_id << " over." << std::endl;
}
std::vector<std::shared_ptr<std::thread>> philosopher;
std::vector<std::mutex> tableware_mutex(5);
for (int loop_i = 0; loop_i < 5; ++loop_i) {
philosopher.push_back(
std::make_shared<std::thread>(thread_func, loop_i, std::ref(tableware_mutex[loop_i]), std::ref(tableware_mutex[(loop_i + 1) % 5]))
);
}
for (int loop_i = 0; loop_i < 5; ++loop_i) {
philosopher.at(loop_i)->join();
}
这里我们初始化了五个哲学家(线程)和五个餐具(锁),每个哲学家需要两个相邻的餐具来进食。其结果很简单:
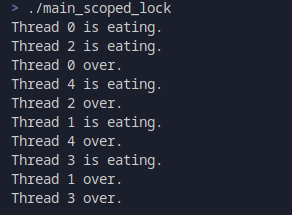
可以看到,这帮哲学家们很有序的进食,没有产生冲突。而如果我们把对应的std::scoped_lock lock(mutex1, mutex2);,改为两个std::lock_guard,肉眼可见的会出现恶心的死锁问题。
和std::lock_guard类似的,它也有一个参数std::adopt_lock_t,表明线程已经获取到锁,构造时不需要获取锁,不过这个参数位于第一个。
std::scoped_lock lk(std::adopt_lock, mutex1, mutex2);
unique_lock
std::unique_lock相比较与std::lock_guard更为自由,除了std::adopt_lock_t参数外,其还支持try_to_lock_t,defer_lock_t,其中try_to_lock_t为非阻塞型加锁,defer_lock_t不在初始化的时候加锁。
std::unique_lock<std::mutex> lk(mutex, std::adopt_lock);
std::unique_lock<std::mutex> lk(mutex, std::try_to_lock);
std::unique_lock<std::mutex> lk(mutex, std::defer_lock);
std::unique_lock支持超时加锁:
std::unique_lock<std::timed_mutex> lk(mutex, 1s);
std::unique_lock支持移动语义,所以可以作为返回值
std::unique_lock<std::mutex> get_lock() {
std::unique_lock<std::mutex> lk(mutex);
return lk;
}
void thread_func(int thread_id) {
std::unique_lock<std::mutex> lk = get_lock();
std::cout << "Test 1: " << thread_id << std::endl;
std::this_thread::sleep_for(1s);
std::cout << "Test 2: " << thread_id << std::endl;
}
由于其允许在未加锁构造,所以它也提供了相应的lock、try_lock、unlock等方法。
shared_lock
和std::unique_lock类似,不过这个是锁定读写锁的读部分。
总结
本文总结了标准库中所有的锁管理的类,合理使用可以使代码更优美。这是标准库线程第三篇博文了,第四篇将会介绍线程里面的条件变量。
ref
[1] https://zh.wikipedia.org/wiki/哲学家就餐问题
博客原文:https://www.cnblogs.com/ink19/p/std_thread-3.html
std::thread线程库详解(3)的更多相关文章
- std::thread线程库详解(2)
目录 目录 简介 最基本的锁 std::mutex 使用 方法和属性 递归锁 std::recursive_mutex 共享锁 std::shared_mutex (C++17) 带超时的锁 总结 简 ...
- std::thread线程库详解(5)
目录 目录 前言 信号量 counting_semaphore latch与barrier latch barrier 总结 前言 前面四部分内容已经把目前常用的C++标准库中线程库的一些同步库介绍完 ...
- std::thread线程库详解(4)
目录 目录 前言 条件变量 一些需要注意的地方 总结 前言 本文主要介绍了多线程中的条件变量,条件变量在多线程同步中用的也比较多.我第一次接触到条件变量的时候是在完成一个多线程队列的时候.条件变量用在 ...
- Java Thread(线程)案例详解sleep和wait的区别
上次对Java Thread有了总体的概述与总结,当然大多都是理论上的,这次我将详解Thread中两个常用且容易疑惑的方法.并通过实例代码进行解疑... F区别 sleep()方法 sleep()使当 ...
- Thread线程相关方法详解
1.sleep() 使当前线程(即调用该方法的线程)暂停执行一段时间,让其他线程有机会继续执行,但它并不释放对象锁.也就是说如果有synchronized同步快,其他线程仍然不能访问共享数据.注意该方 ...
- “全栈2019”Java多线程第十章:Thread.State线程状态详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- Lua的协程和协程库详解
我们首先介绍一下什么是协程.然后详细介绍一下coroutine库,然后介绍一下协程的简单用法,最后介绍一下协程的复杂用法. 一.协程是什么? (1)线程 首先复习一下多线程.我们都知道线程——Thre ...
- Python--urllib3库详解1
Python--urllib3库详解1 Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3.Urllib3提供了很多pyt ...
- MySQL5.6的4个自带库详解
MySQL5.6的4个自带库详解 1.information_schema详细介绍: information_schema数据库是MySQL自带的,它提供了访问数据库元数据的方式.什么是元数据呢?元数 ...
随机推荐
- Shell-匹配行及date日期转换
#将指定字符串转化为从1970年1月1日到现在的秒数. date -d '20170506' "+%s" #将1970年1月1日到现在累计的秒数转化为日期 date -d @149 ...
- 利用302绕过http协议限制
360某处ssrf漏洞可探测内网信息(附内网6379探测脚本) http://xss.one/bug_detail.php?wybug_id=wooyun-2016-0229611
- 单身狗福利!利用java实现每天给对象发情话,脱单指日可待!
引言 最近看到一篇用js代码实现表白的文章,深有感触. 然后发现自己也可以用java代码实现,然后就开始写代码了,发现还挺有意思的,话不多说开搞 实现思路: 使用HttpClient远程获取彩虹屁生成 ...
- 简丽Framework-开篇
简丽Framework-开篇 简丽Framework 是一个开源java Web开发框架. 开源的框架.库.组件等比比皆是,每个开源产品都有它的定位和价值. 简丽Framework的定位是 ...
- kvm环境部署及常用指令
Linux下通过kvm创建虚拟机,通过vnc连接,做好配置后,通过ssh登录,并开启iptables Kvm虚拟化搭建教程参考链接:https://jingyan.baidu.com/article/ ...
- mssql不存在便插入存在不执行操作
前言 参考:https://www.jb51.cc/mssql/76911.html 在mssql中,在记录不存在时插入记录,如果存在则不执行操作 数据库 相关语句 --创建表 CREATE TABL ...
- wpf窗体项目 生成dll类库文件
我想把一个wpf应用程序的输出类型由windows应用程序改为类库该怎么做,直接在项目属性里改的话报错为 库项目文件无法指定applicationdefinition属性 wpf窗体项目运行之后bin ...
- 如何做好Code Review
Code Review(代码审查)很多团队都会做,效果如何不好说.如果你能轻易地从一堆出自正经团队之手的代码里找出几个低级错误,往往意味着团队管理者长期忽视了Code Review的重要性. 根据经验 ...
- Java Int类型与字符,汉字之间的转换
/** * java 中的流主要是分为字节流和字符流 * 再一个角度分析的话可以分为输入流和输出流 * 输入和输出是一个相对的概念 相对的分别是jvm虚拟机的内存大小 * 从另一个角度讲Java或者用 ...
- 深度学习论文翻译解析(十六):Squeeze-and-Excitation Networks
论文标题:Squeeze-and-Excitation Networks 论文作者:Jie Hu Li Shen Gang Sun 论文地址:https://openaccess.thecvf.co ...