scrapy爬取微信小程序社区教程(crawlspider)
爬取的目标网站是:
http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1
目的是爬取每一个教程的标题,作者,时间和详细内容
通过下面的命令可以快速创建 CrawlSpider模板 的代码:
scrapy genspider wsapp wxapp-union.com
CrawlSpider是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
在之前爬取免费代理的爬虫里面,我们没有使用crawlspider,当我们想要爬取下一页的时候,采用的是xpath解析response,找到下一页的链接,然后再次请求

但是这样的弊端在于难以灵活爬取网站,因此这里我们使用crawlspider来让爬取任务更简单。
CrawlSpider继承自Spider, 爬取网站常用的爬虫,其定义了一些规则(rule)方便追踪或者是过滤link。 也许该spider并不完全适合您的特定网站或项目,但其对很多情况都是适用的。 因此您可以以此为基础,修改其中的方法,当然您也可以实现自己的spider。
除了从Spider继承过来的(您必须提供的)属性外,其提供了一个新的属性:
- rules
一个包含一个(或多个) Rule 对象的集合(list)。 每个 Rule 对爬取网站的动作定义了特定表现。 Rule对象在下边会介绍。 如果多个rule匹配了相同的链接,则根据他们在本属性中被定义的顺序,第一个会被使用。
该spider也提供了一个可复写(overrideable)的方法:
- parse_start_url(response)
当start_url的请求返回时,该方法被调用。 该方法分析最初的返回值并必须返回一个 Item 对象或者 一个 Request 对象或者 一个可迭代的包含二者对象。
这里我们使用rules设置规则爬取我们需要的链接。
因为我们需要爬取教程,点击下一页之后发现网页链接的变化是page,即第一页到第二页的变化是page=1变成了page=2
/portal.php?mod=list&catid=2&page=1
如果有爬虫经验的话这里应该很容易理解
可以知道页数链接是在类似于list&catid=2&page=x这种格式的链接里面
接着我们查看每一页里面的每一篇文章的链接,比如:
http://www.wxapp-union.com/article-5798-1.html
可知教程的详情是在类似于article-xxx.html这种格式的链接里面
所以我们可以在rules里面编写这两条规则
rules = (
Rule(LinkExtractor(allow=r'.+list&catid=2&page=\d+'), follow=True),
Rule(LinkExtractor(allow=r'.+article-.+\.html'), callback='parse_detail', follow=False),
)
我们需要使用LinkExtractor和Rule这两个东西来决定爬虫的具体走向
需要注意的是:
1,allow设置规则的方法:要能够限制在我们想要的url上面,不是和其他url产生相同的正则表达式即可
在我们这里设置的rules里面,使用 .+来匹配任意字符,\d+来匹配page后面的数字
2,什么情况下使用follow:如果在爬取页面的时候,需要将满足当前条件的url在进行跟进,那么就设置为Ture,否则设置为False
在我们的这个例子里面,对于这个界面,我们选择了跟进:
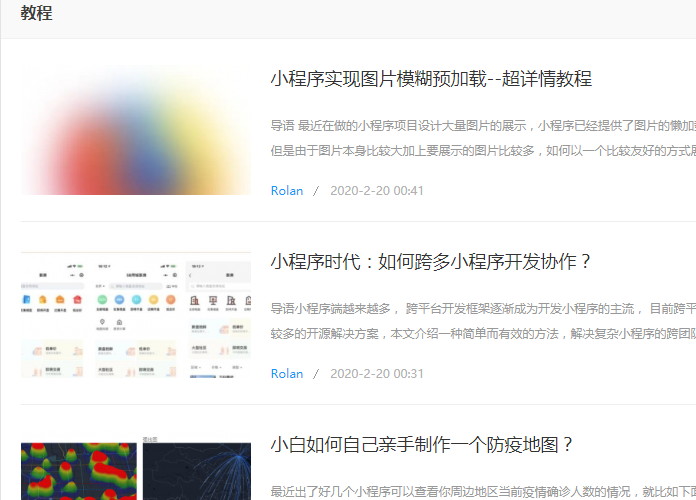
因为我们在这个页面里再爬取教程的详情页面,所以需要跟进
而在这个页面我们没有跟进:
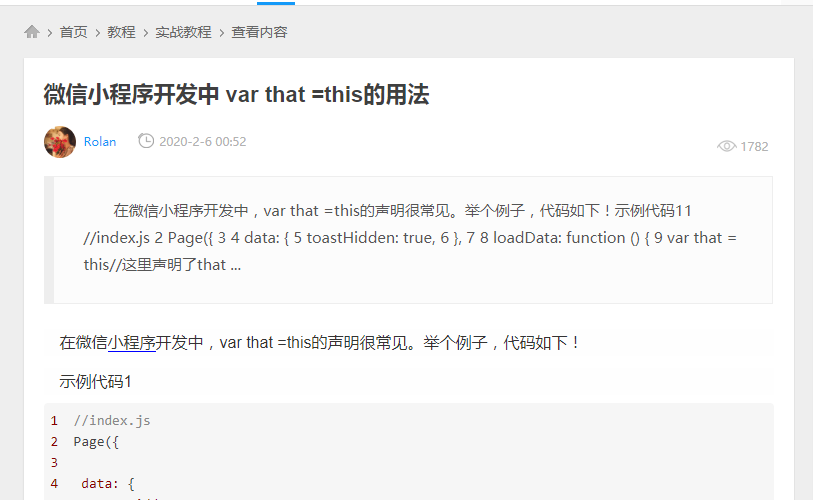
因为我们到了这个页面并且获取了教程详细信息之后,这个页面对于我们来说就已经无用了,虽然在这个页面的旁边可能还有其他的教程详情链接等待我们去点击,但是这些详情链接我们会在其他的地方爬取到的,虽然scrapy里面自动会去重,但我们为了省事,得到我们需要的东西之后就终止爬虫对于这个页面的探索,这样爬虫脉络更清晰一点
3,什么情况下该指定callback:如果这个url对应的页面,只是为了获取更多的url,并不需要里面的数据,那么可以不指定callback,如果想要获取url对应页面中的数据,那么就需要指定一个callback
callback里面的函数是我们对于页面进行详细解析的回调函数。我们需要对详细教程页的教程内容进行分析,所以需要callback,而在portal.php?mod=list&catid=2&page=1这一类页面里,我们仅仅是想要获取更多的详细教程的链接,也不需要更多的处理,所以不使用callback
除了这些之外,其他的地方跟原来的spider大致相同,爬取到的详细内容保存在了json文件里面

代码放在了github上面,欢迎Star
https://github.com/Cl0udG0d/scrapy_demo
参考链接:
https://geek-docs.com/scrapy/scrapy-tutorials/scrapy-crawlspider.html
https://www.kancloud.cn/ju7ran/scrapy/1364596
https://www.cnblogs.com/derek1184405959/p/8451798.html
https://www.bilibili.com/video/av57909837?p=8
scrapy爬取微信小程序社区教程(crawlspider)的更多相关文章
- python爬取微信小程序(实战篇)
python爬取微信小程序(实战篇) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90452656 展开 一.背景介绍 近期有需求需要抓 ...
- Python爬取微信小程序(Charles)
Python爬取微信小程序(Charles) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90045204 一.前言 最近需要获取微信小 ...
- 爬虫_微信小程序社区教程(crawlspider)
照着敲了一遍,,, 需要使用"LinkExtrator"和"Rule",这两个东西决定爬虫的走向. 1.allow设置规则的方法:要能够限制在我们想要的url上 ...
- scarpy crawl 爬取微信小程序文章(将数据通过异步的方式保存的数据库中)
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider ...
- scarpy crawl 爬取微信小程序文章
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider ...
- 微信小程序实例教程(一)
序言 开始开发应用号之前,先看看官方公布的「小程序」教程吧!(以下内容来自微信官方公布的「小程序」开发指南) 本文档将带你一步步创建完成一个微信小程序,并可以在手机上体验该小程序的实际效果.这个小程序 ...
- 微信小程序实例教程(四)
第八章:微信小程序分组开发与左滑功能实现 先来看看今天的整体思路: 进入分组管理页面 --> 点击新建分组新建 进入到未分组页面基本操作 进入到已建分组里面底部菜单栏操作 --> 从名 ...
- 微信小程序实例教程(三)
第七章:微信小程序编辑名片页面开发 编辑名片有两条路径,分为新增名片流程与修改名片流程. 用户手填新增名片流程: 首先跳转到我们的新增名片页面 1 需要传递用户的当前 userId,wx.na ...
- 微信小程序实例教程(二)
第五章:微信小程序名片夹详情页开发 今天加了新干货!除了开发日志本身,还回答了一些朋友的问题. 闲话不多说,先看下「名片盒」详情页的效果图: 备注下大致需求:顶部背后是轮播图,二维码按钮弹出模态框信息 ...
随机推荐
- 跟我一起学Redis之Redis事务简单了解一下
前言 关系数据库中的事务,小伙伴们应该是不陌生了,不管是在开发还是在面试过程中,总有两个问题逃不掉: 说说事务的特性: 事务隔离级别是怎么一回事? 事务处理不好,数据就可能不准确,最终就会导致业务出问 ...
- 使用Graph API 操作OneDrive 文件 权限 共享
(Get)列出默认驱动器下(获取items id) /me/drive/root/children 如果想找其他驱动器使用/Drives 列出后可以查看到驱动器下的文件,其中items id就是文件的 ...
- 基于gin的golang web开发:mysql增删改查
Go语言访问mysql数据库需要用到标准库database/sql和mysql的驱动.标准库的Api使用比较繁琐这里再引入另一个库github.com/jmoiron/sqlx. go get git ...
- dp:322. Coin Change 自下而上的dp
You are given coins of different denominations and a total amount of money amount. Write a function ...
- 利用matlibplot绘制雷达图
之前在一些数据分析案例中看到用 Go 语言绘制的雷达图,非常的漂亮,就想着用matlibplot.pyplot也照着画一个,遗憾的是matlibplot.pyplot模块中没有直接绘制雷达图的函数,不 ...
- SQL Server 数据库开启日志CDC记录,导致SQL Server 数据库日志异常增大
这几天单位的SQL Server业务数据生产库出现数据库日志增长迅速,导致最终数据无法写入数据库,业务系统提示"数据库事务日志已满",经过多方咨询和请教,终于将日志异常的数据库处理 ...
- centos6 安装和配置PHP 7.0
2015年12月初PHP7正式版发布,迎来自2004年以来最大的版本更新.PHP7最显著的变化就是性能的极大提升,已接近Facebook开发的PHP执行引擎HHVM.在WordPress基准性能测试中 ...
- webug第十关:文件下载
第十关:文件下载 点击下载 将fname改为download.php....不过好像它的配置有点问题
- Mac小白用户都能体验Windows应用的轻量级软件
近期,苹果在WWDC大会上表示Mac电脑将转向ARM架构,这意味着为iPhone手机.iPad平板和Mac电脑应用APP提供了统一的可能性.也就是说,iPhone手机.iPad平板电脑的应用可能在Ma ...
- word查找与替换
------------恢复内容开始------------ 如何快速删除大量空格键:查找和替换-更多-特殊格式-查找内容[特殊格式(段落标记)]设置为(^p^p,即点击两次段落标记),替换设置为(^ ...