R-CNN for Small Object Detection
R-CNN for Small Object Detection
文章方法概括
- 这篇文章主要讨论针对小目标的目标检测
- 文章为了证明:对传统R-CNN style的方法进行改进,可以用于小目标检测,并且性能比DPM方法好
- 整个检测流程
- 用改进版的RPN(修改了anchor的尺度,称为modified RPN)提取候选区域
- 用改进版的CNN(结合了上下文信息的CNN模型,base的CNN可以用AlexNet或者VGG,称为ContextNet)对候选区域进行分类,不做Box Regression
文章创新点和贡献
这篇文章从三个角度对比了小目标检测的方法:
- 候选区域生成:传统RPN vs. modified RPN(更好)
- 上采样策略:上采样比例小 + 去掉全连接 vs. 上采样比例大 + 保留全连接(更好)
- 是否使用上下文信息:不实用上下文 vs. 使用上下文(更好)
- 这篇文章的贡献在于:
- 提出了一个专门针对于小目标的目标检测benchmark库
- 提出了一个把传统R-CNN方法进行改进用于小目标检测的思路和流程
- 小目标检测的难点:
- 一张图中小目标比大目标往往更多
- 小目标的像素少(信息少)
- 目前针对小目标的研究非常有限,大部分文献都是针对VOC库中的大目标
文章方法和细节
- 小目标benchmark库的建立
- 小目标的定义
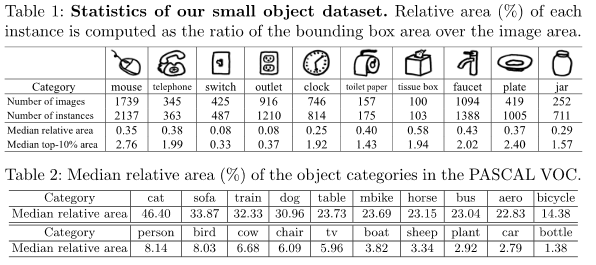
- 现实生活中的目标的物理大小相对较小,比如,鼠标,插孔,盘子等等,即实际大小也比较小
- 在图像中所占整张图像的比例小
- 小目标的定义

- 大库(包含大、小目标)如何做成小库(仅包含小目标)
- 使用Microsoft COCO和SUN库的子集
- 只挑选了10类(Mouse,Telephone,Switch,Outlet,Clock,Toilet paper,Tissue box,Faucet,Plate,Jar)
- 去掉10类中目标比较大的(即使是鼠标类,在有的图像中鼠标也很大,把这些样本去掉)
- 数据库大小
- 4295张图像,8393个目标(train:test = 2:1)
- relative area即相对面积 = Area(Bounding box of the object) / Area(image)
- 小目标的相对面积(relative area)的中位数(media relative area) 分布在0.08%~0.58%(约16*16~42*42像素)
- 一般的大目标的media relative area 分布在1.38%~46.4%
- 具体的类别,图像数,相对面积分布如下表
- 评估标准(mAP,和普通的多类目标检测一样)
- 单类的PR曲线(调整IOU的阈值)
- 单类的average precision:(PR曲线求积分,面积)
- 多类的mAP:每类的average precision直接取平均
针对R-CNN style方法进行修改得到小目标检测方法和流程
- 候选区域生成
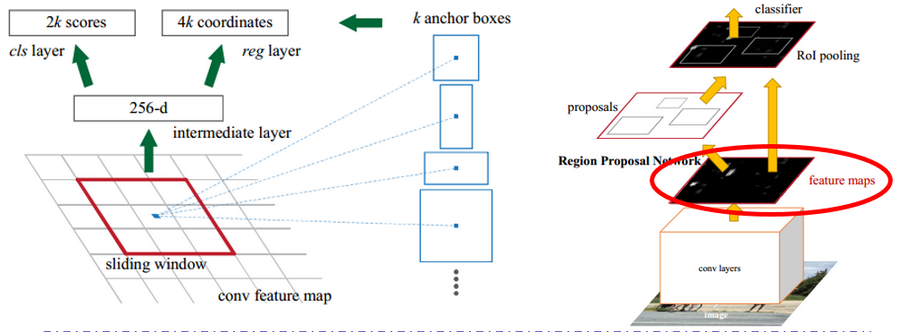
- 本文方法(modified RPN):普通的RPN修改了anchor大小 + feature map选择
- anchor大小修改: 128^2,256^2,512^2 → 16^2,40^2,100^2
- feature map选择:conv5 → conv4_3
- 初始RPN的anchor和流程如下:
- 拿来对比的两种方法:DPM(据说在R-CNN出现之前最好的方法,HOG+SVM),原始的RPN(用来检测大目标的)
- 实验结果对比:

- 实验结论:修改anchor尺度(modefied RPN)比DPM好,比原始RPN好
- 本文方法(modified RPN):普通的RPN修改了anchor大小 + feature map选择
- 上采样策略
- 本文方法(Full AlexNet):直接把modefied RPN得到的候选区域resize成分类要用的CNN的原始输入图像(Alexnet是227,VGG是224)
- 对比方法(Partial AlexNet):把候选区域resize成67*67,输入到分类要用的CNN(因为AlexNet和VGG有全连接层,所以只能处理固定成规定大小的图像,但是如果把全连接层去掉,只取卷积层,就能处理大小和规定的固定大小不一样的输入图像),最后连接分类层
- 实验对比结果:
- 因为候选区域的大小很小,如果用Full AlexNet(全连接层),则必须resize成227或者224,都是放大了好几倍,所以作者考虑这样的放大可能引入了artificats,这个部分的实验就是在证明即使这样的放大效果也比不用整个网络仅使用全卷积层得到的效果更好。
- 作者认为,第一因为输入图像大小变小了,所以相同的感受野大小(网络结构相同)对小图而言,可能就是对应了原图的很大部分,属于coarse的scale,而对于大图,因为只对应原图的一小部分,所以更加fine,细节更多,信息更丰富
- 第二,从得到的特征来看,小图的feature更短,大图的feature更长(只考虑卷积层)
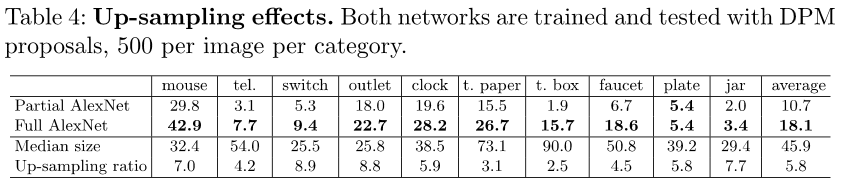
- 实验结论:取整个(包括Full Concation层)分类网络(Full AlexNet)比只取卷积部分的网络(Partial AlexNet)好
- 因为候选区域的大小很小,如果用Full AlexNet(全连接层),则必须resize成227或者224,都是放大了好几倍,所以作者考虑这样的放大可能引入了artificats,这个部分的实验就是在证明即使这样的放大效果也比不用整个网络仅使用全卷积层得到的效果更好。
- 上下文信息的结合
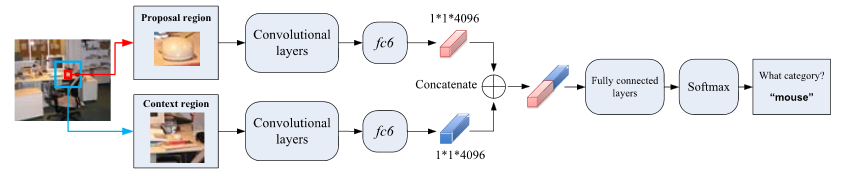
- 本文方法(Context-AlexNet)网络结构如下图:
- 网络结构分为两部分,front-end和back-end
- front-end由两个并行的CNN组成,一个以proposal region直接作为输入,经过6个conv层(Alex或者VGG)+ 1个fc层,得到4096维的特征;另一个以proposal region为中心,在原图上取4倍的proposal region的一个context region作为输入,经过6个conv层 + 1个fc层,得到4096维的特征
- back-end以front-end的两个4096的特征串起来作为输入,经过2个fc层 + 1个softmax层得到每个proposal region的分类信息
- 结构图如下:
- 对比的方法(Baseline AlexNet):普通的AlexNet,没有context信息。另外作者对比了上下文尺度的大小(放大3倍还是7倍)

- 实验结果对比:

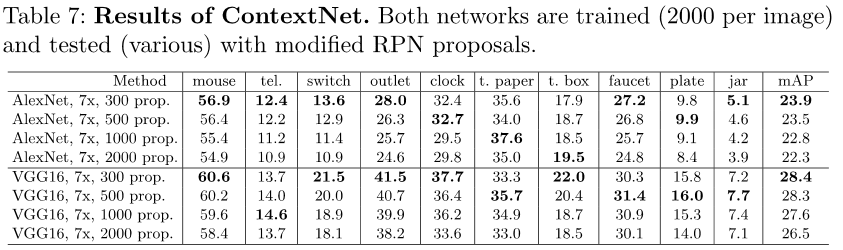
- 实验结论:用了上下文(ContextNet)比不用上下文(Baseline AlexNet)好,3倍和7倍差别不大!
- 本文方法(Context-AlexNet)网络结构如下图:
实验结果
- 最终的mAP上和其他的方法进行对比(比DPM,AlexNet R-CNN,和VGG R-CNN都要好)

- 最终的mAP上AlexNet和VGG的对比(VGG好,层数更深),不同proposal个数对比(取300好,false positive少)
总结
- 做小目标检测的几个思路:专门建立小目标库,对小目标大小进行统计分析,对网络进行修改(卷积核大小,anchor大小),利用目标周围的上下文信息
R-CNN for Small Object Detection的更多相关文章
- object detection[content]
近些年,随着DL的不断兴起,计算机视觉中的对象检测领域也随着CNN的广泛使用而大放异彩,其中Girshick等人的<R-CNN>是第一篇基于CNN进行对象检测的文献.本文欲通过自己的理解来 ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 目标检测(一)RCNN--Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik 该论文提出了一种简单且可扩展的检测算法,在VOC2012数据集上取得的mAP比当 ...
- 深度学习论文翻译解析(四):Faster R-CNN: Down the rabbit hole of modern object detection
论文标题:Faster R-CNN: Down the rabbit hole of modern object detection 论文作者:Zhi Tian , Weilin Huang, Ton ...
- (转)Awesome Object Detection
Awesome Object Detection 2018-08-10 09:30:40 This blog is copied from: https://github.com/amusi/awes ...
- 论文阅读 | FCOS: Fully Convolutional One-Stage Object Detection
论文阅读——FCOS: Fully Convolutional One-Stage Object Detection 概述 目前anchor-free大热,从DenseBoxes到CornerNet. ...
- 中文版 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 摘要 最先进的目标检测网络依靠区域提出算法 ...
- 关于目标检测 Object detection
NO1.目标检测 (分类+定位) 目标检测(Object Detection)是图像分类的延伸,除了分类任务,还要给定多个检测目标的坐标位置. NO2.目标检测的发展 R-CNN是最早基于C ...
- Parallel Feature Pyramid Network for Object Detection
Parallel Feature Pyramid Network for Object Detection ECCV2018 总结: 文章借鉴了SPP的思想并通过MSCA(multi-scale co ...
- [C4W3] Convolutional Neural Networks - Object detection
第三周 目标检测(Object detection) 目标定位(Object localization) 大家好,欢迎回来,这一周我们学习的主要内容是对象检测,它是计算机视觉领域中一个新兴的应用方向, ...
随机推荐
- HTML5与XML的区别
XHTML 是 XML 风格的 HTML 4.01. HTML5 是HTML的第五大版本,取代 HTML 4.01. XHTML是基于XML发布的HTML规范,旨在规范HTML的格式. 两者提出的目的 ...
- 基于Java语言开发jt808、jt809技术文章精华索引
很多技术开发人员喜欢追逐最新的技术,如Node.js, go等语言,这些语言只是解决了某一个方面,如只是擅长异步高并发等等,却在企业管理后台开发方面提供的支持非常不够,造成项目团队技术选项失败,开发后 ...
- HTML5自定义属性之data-index
#使用jquery获取data-index的值 jquery 的版本最好高一些 #html <div id = 'div'><span data-field='demo'>&l ...
- 跑测试没有web环境的情况
有时候 当你跑测试的main方法的时候,会有一些莫名其妙的错误,明明mave pom的包是全的,web跑起来不会报错,可是在main方法下就是报错了,这个时候引入 <dependency> ...
- js----Navigator对象,查看浏览器信息,Screen对象,查看屏幕信息
Navigator对象 Navigator 对象包含有关浏览器的信息,通常用于检测浏览器与操作系统的版本. 对象属性: 查看浏览器的名称和版本,代码如下: <script type=" ...
- NumberUtils
package cn.edu.hbcf.common.utils; import java.math.BigDecimal; import java.text.NumberFormat; import ...
- 27. Retrofit2 -- How to Use Dynamic Urls for Requests
27. Retrofit2 -- How to Use Dynamic Urls for Requests Retrofit tutorial 用户案例场景 如何使用动态 Url 相对于基本地址,动态 ...
- quartz定时任务框架之实例
import org.quartz.*; import org.quartz.impl.StdSchedulerFactory; import java.util.Date; public class ...
- spring的容器(控制反转、依赖注入)
一.spring的容器 ”容器“是spring的一个重要概念,其主要作用是完成创建成员变量,并完成装配. 而容器的特点”控制反转“和”依赖注入“是两个相辅相成的概念. 控制反转:我们在使用一个类型的实 ...
- telnet master主机的NodePort服务不通的问题
硬件环境: 两台物理机: 172.16.114.210(master主机) 172.16.114.211(node主机) 软件环境: kubernetes 1.5.2 flannel 0.5.5 问题 ...