zipfile 解压文件名乱码
zipfile 中文文件名 解压乱码
上传文件功能模块需求及BUG现象:
环境
mac
django 1.11.13
python 3.6
功能需求:
上传一个.zip格式的压缩文件
解压该test.zip压缩文件
解压zip文件时,遍历其目录下所有子文件,同时计算出单个子文件的有效代码行数
这时,发现解压后的子文件名中文出现乱码,如下图:
BUG截图

解决思路
1、解压过程中,发现解压的文件内容正常;
2、使用的是第三方库zipfile模块,因为第1步得到正常的文件内容,本地业务逻辑可先不排查;
3、首先检查zipfile的源码中,针对编码/解码的执行过程仔细排查发现:
zipfile中根据文件 flag 检测的时候,只支持 cp437 和 utf-8
找到下面两处,并追加修正后,乱码现象解决:(追加的decode编码可根据实际情况修改,如win环境下乱码采用.decode('gbk'))
# zipfile.py # 第一处
if flags & 0x800:
# UTF-8 file names extension
filename = filename.decode('utf-8')
else:
# Historical ZIP filename encoding
filename = filename.decode('cp437')
# 追加此句
filename = filename.encode("cp437").decode('utf-8') # 第二处
if zinfo.flag_bits & 0x800:
# UTF-8 filename
fname_str = fname.decode("utf-8")
else:
fname_str = fname.decode("cp437")
# 追加此句
fname_str = fname_str.encode("cp437").decode('utf-8')
解决后,正常显示:

上传功能源码
import zipfile # 指定想要统计的文件类型
whitelist = ['py'] # 遍历文件, 递归遍历文件夹中的所有
def getFile(basedir):
# 存储上传解压后的文件列表
filelists = []
for parent, dirnames, filenames in os.walk(basedir):
# for dirname in dirnames:
# getFile(os.path.join(parent,dirname)) #递归
for filename in filenames:
ext = filename.split('.')[-1]
# 只统计指定的文件类型,略过一些log和cache文件
if ext in whitelist:
filelists.append(os.path.join(parent, filename)) # 统计一个文件的行数
def countLine(fname):
count = 0
single_quotes_flag = False
double_quotes_flag = False
with open(fname, 'rb') as f:
for file_line in f:
file_line = file_line.strip()
# print(file_line)
# 空行
if file_line == b'':
pass # 注释 # 开头
elif file_line.startswith(b'#'):
pass # 注释 单引号 ''' 开头
elif file_line.startswith(b"'''") and not single_quotes_flag:
single_quotes_flag = True
# 注释 中间 和 ''' 结尾
elif single_quotes_flag == True:
if file_line.endswith(b"'''"):
single_quotes_flag = False # 注释 双引号 """ 开头
elif file_line.startswith(b'"""') and not double_quotes_flag:
double_quotes_flag = True
# 注释 中间 和 """ 结尾
elif double_quotes_flag == True:
if (file_line.endswith(b'"""')):
double_quotes_flag = False # 代码
else:
count += 1 # print(fname + '----', count)
# 单个文件行数
print(fname, '----count:', count)
return count def un_zip(file_name):
"""unzip zip file"""
zip_file = zipfile.ZipFile(file_name)
# <zipfile.ZipFile filename='/Users/limengjie/Desktop/pyhon/SMS0614/upload_file/0617.zip' mode='r'>
if os.path.isdir(file_name + "_files"):
pass
else:
os.mkdir(file_name + "_files")
for names in zip_file.namelist():
zip_file.extract(names, file_name + "_files/")
# 遍历解压后得到的文件夹, 递归遍历文件夹中的所有子文件
getFile(file_name + "_files")
totalline = 0
# 遍历解压后的文件列表,统计单个文件的行数并汇总
for filelist in filelists:
totalline = totalline + countLine(filelist)
zip_file.close()
# 返回上传文件所有子文件的总行数
return totalline
补充:上传业务逻辑代码
class Uploading(View):
def get(self, request):
return render(request, "uploading.html", )
def post(self, request):
# 1、拿到压缩文件对象file_obj
file_obj = request.FILES.get("user_file")
file_name = os.path.join(file_dir, file_obj.name)
file_size = file_obj.size
with open(file_name, "wb") as f:
for line in file_obj.chunks():
f.write(line)
# 2、解压压缩文件,并获取代码行数属性
total_line = un_zip(file_name)
# 3、单个文件进行文件对象实例化,文件名,文件大小,代码行数
models.FileObj.objects.create(
fileName=file_obj.name,
fileSize=file_size,
fileLineCount=total_line
)
return redirect("/upload_file/")
优化需求
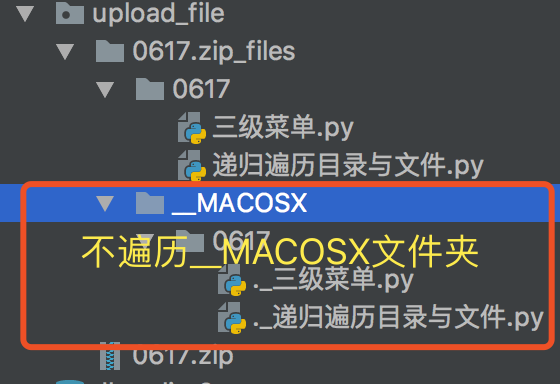
统计行数优化:mac环境解压文件时,系统会自动追加__MACOSX文件夹,为了不遍历此文件夹,需补充:
在getFIle函数中修改,即可:
# MAC环境下略过__MACOSX文件夹
if "__MACOSX" in dirnames:
pop_index = dirnames.index("__MACOSX")
dirnames.pop(pop_index)
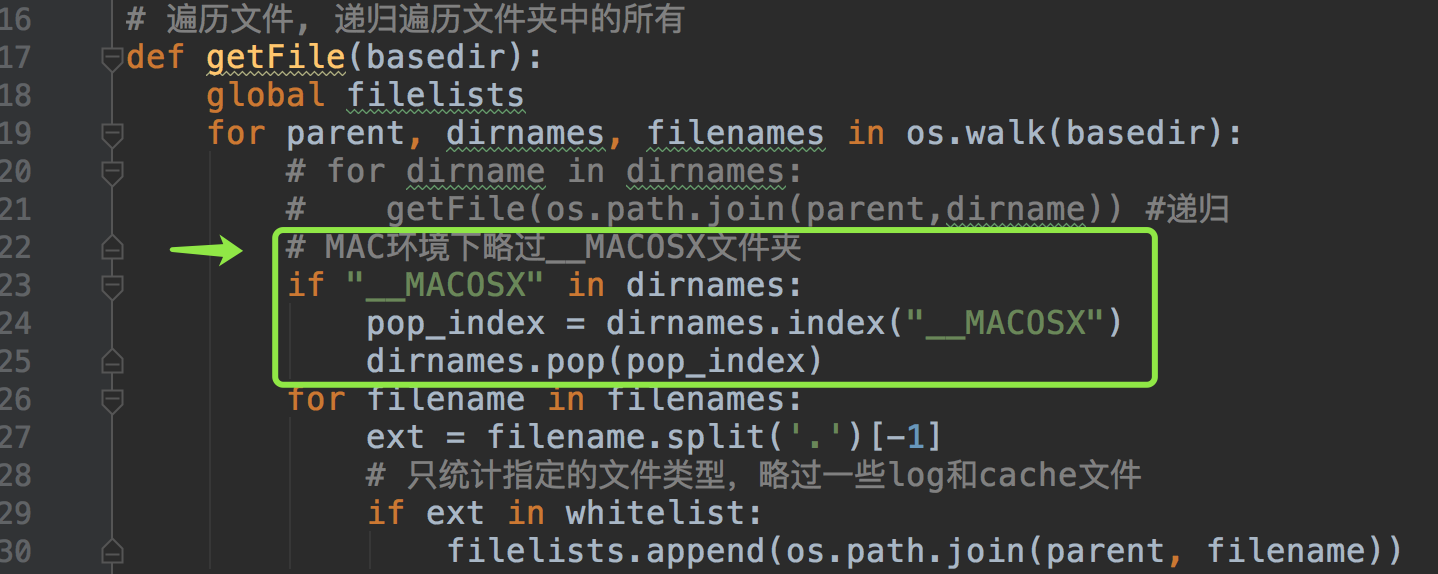
优化后,得到我们需要的结果:

(完)
zipfile 解压文件名乱码的更多相关文章
- Windows 压缩文件到 Linux中解压文件名乱码
问题 在Windows中将文件夹压缩后,拿到Ubuntu系统中解压,中文文件名乱码 解决 因为两个系统所使用的编码不同,Windows一般使用GBK编码,Ubuntu使用utf8编码,只需要在解压的时 ...
- python使用zipfile解压中文乱码问题
在zipfile.ZipFile中获得的filename有中日文则很大可能是乱码,这是因为 在zip标准中,对文件名的 encoding 用的不是 unicode,而可能是各种软件根据系统的默认字符集 ...
- 关于zipfile解压出现的字符编码问题
使用zipfile解压文件时,出现了中文乱码问题,具体解决方法有两个,直接上代码吧. def deco_zip(path, file_path): os.mkdir(file_path) # 方式一 ...
- Java中解压文件名有中文的rar包出现乱码问题的解决
import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import j ...
- Net Core解决ZipFile解压中文出现乱码
一.在main方法中添加 Encoding.RegisterProvider(CodePagesEncodingProvider.Instance); 二.解压添加 //sourceArchiveFi ...
- linux ubuntu12.04 解压中文zip文件,解压之后乱码
在windows下压缩后的zip包,在ubuntu下解压后显示为乱码问题 1.zip文件解压之后文件名乱码: 第一步 首先安装7zip和convmv(如果之前没有安装的话) 在命令行执行安装命令如下: ...
- 通过zipfile解压指定目录下的zip文件
代码: # -*- coding: utf-8 -*- import os import zipfile import platform import multiprocessing # 解压后的文件 ...
- ubuntu rar文件解压中文乱码问题
http://blog.csdn.net/android_huber/article/details/7382867 前段时间经常要在ubuntu系统中去解压rar的文件,但是每次解压出来却总是出现中 ...
- unzip解压中文乱码
1 问题描述 直接 unzip xxx.zip 乱码,肯定是编码问题了不用问.但是unzip没有指定编码的选项: 网上的解决方案如下: unzip -O GBK/GB18030CP936 xx.zip ...
随机推荐
- flask之flask-sqlalchemy(一)
一 安装flask-sqlalchemy pip install flask-sqlalchemy 二 导入相关模块和对象 from flask_sqlalchemy import SQLAlchem ...
- html元素 input各种输入限制
1.取消按钮按下时的虚线框,在input里添加属性值 hideFocus 或者 HideFocus=true <input type="submit" value=" ...
- java计数
计数 package com.demo; import java.util.Timer; import java.util.TimerTask; import java.util.concurrent ...
- jquery居中窗口-页面加载直接居中
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Angular的生命周期钩子
没有什么不能用一张图来解决.
- Swiper正方体,左右翻转轮播图
今天的轮播图,和往常的有一点点不同哦!可以说是有一点点的3D效果!因为他在运动的时候,是以正方体的样子左右滚动的; 先引插件: <link rel="stylesheet" ...
- js Array数组对象常见方法总结
Array对象一般用来存储数据. 其常用的方法包括: 1.concat()方法 concat() 方法用于合并两个或多个数组.它不会更改现有数组,而是返回一个新数组. 例如: var arr1=[1, ...
- 项目经验:GIS<MapWinGIS>建模第三天
记录下GIS工程进展
- JNLP文件具体说明编辑
JNLP(Java Network Launching Protocol )是java提供的一种可以通过浏览器直接执行java应用程序的途径,它使你可以直接通过一个网页上的url连接打开一个java应 ...
- 在Linux中安装redmine
Redmine是用Ruby开发的基于web的项目管理软件,是用ROR框架开发的一套跨平台项目管理系统. 如下即为安装步骤: (1)配置ruby环境,可用rvm进行安装匹配,参考http://ruby- ...