分布式链路监控与追踪系统Zipkin
1.分布式链路监控与追踪产生背景
2.SpringCloud Sleuth + Zipkin
3.分布式服务追踪实现原理
4.搭建Zipkin服务追踪系统
5.搭建Zipkin集成RabbitMQ异步传输
6.SpringCloud2.x新知识介绍
分布式链路监控与追踪产生背景
在微服务系统中,随着业务的发展,系统会变得越来越大,那么各个服务之间的调用关系也就变得越来越复杂。一个 HTTP 请求会调用多个不同的微服务来处理返回最后的结果,在这个调用过程中,可能会因为某个服务出现网络延迟过高或发送错误导致请求失败,这个时候,对请求调用的监控就显得尤为重要了。Spring Cloud Sleuth 提供了分布式服务链路监控的解决方案。下面介绍 Spring Cloud Sleuth 整合 Zipkin 的解决方案。
Zipkin框架介绍
Zipkin 是 Twitter 的一个开源项目,它基于 Google Dapper 实现的。我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助查询跟踪数据以实现对分布式系统的监控程序,从而及时发现系统中出现的延迟过高问题。除了面向开发的 API 接口之外,它还提供了方便的 UI 组件来帮助我们直观地搜索跟踪信息和分析请求链路明细,比如可以查询某段时间内各用户请求的处理时间等。
Zipkin 和 Config 结构类似,分为服务端 Server,客户端 Client,客户端就是各个微服务应用。
微服务中,如果服务与服务之间的依赖关系非常复杂,如果某个服务出现一些问题,很难知道原因。

Spring Cloud提供ZipKin组件
SpringCloud Zipkin 与Sleuth
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。
每个服务向zipkin报告计时数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
zipkin会根据调用关系通过Zipkin UI生成依赖关系图。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
Spring Cloud Sleuth可以结合Zipkin,将信息发送到Zipkin,利用Zipkin的存储来存储信息,利用Zipkin Ui来展示数据。
搭建Zipkin服务追踪系统
在 Spring Boot 2.0 版本之后,官方已不推荐自己搭建定制了,而是直接提供了编译好的 jar 包。详情可以查看官网:https://zipkin.io/pages/quickstart.html
注意:zipkin官网已经提供定制了,使用官方jar运行即可。
启动方式:
默认端口号启动zipkin服务
java –jar zipkin.jar 默认端口号; 9411
访问地址:http://192.168.18.220:9411
指定端口号启动8080启动zipkin服务
java -jar zipkin.jar --server.port=8080
访问地址:http://192.168.18.220:8080
指定访问rabbitmq 启动
java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=127.0.0.1
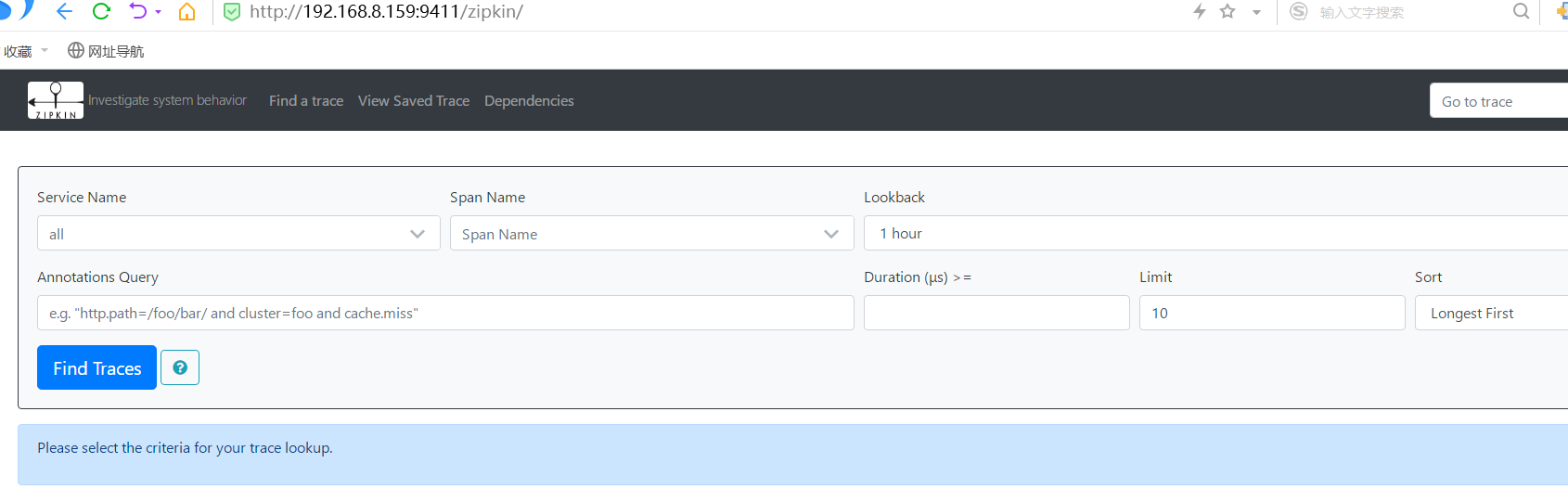
访问:http://192.168.8.159:9411/zipkin/
默认的值是在内存中 需要设置持久化到内存中哦
案例展示 order ---> member ---> msg
在Order服务、Member、Msg服务里面引入:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
pom:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.1.RELEASE</version>
</parent>
<!-- 管理依赖 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Finchley.M7</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- SpringBoot整合eureka客户端 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency> </dependencies>
<!-- 注意: 这里必须要添加, 否者各种依赖有问题 -->
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/libs-milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
yml配置 收集方式有抽样收集 有全部收集 收集到平台的ip+端口号
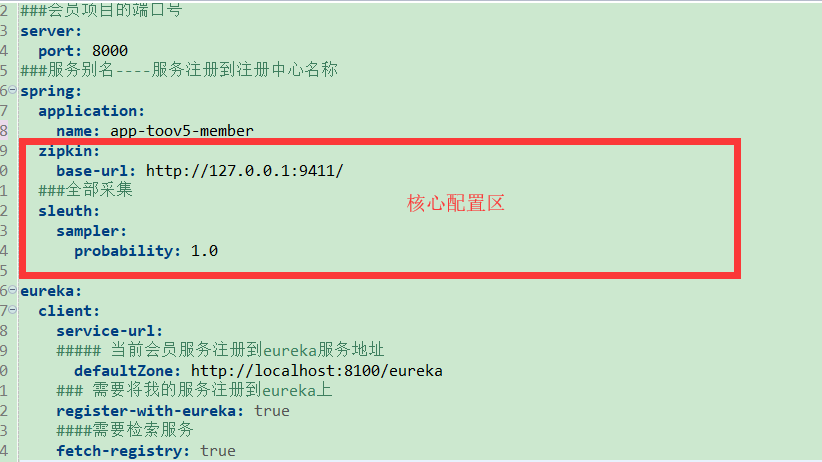
###会员项目的端口号
server:
port: 8000
###服务别名----服务注册到注册中心名称
spring:
application:
name: app-toov5-member
zipkin:
base-url: http://127.0.0.1:9411/
###全部采集
sleuth:
sampler:
probability: 1.0 eureka:
client:
service-url:
##### 当前会员服务注册到eureka服务地址
defaultZone: http://localhost:8100/eureka
### 需要将我的服务注册到eureka上
register-with-eureka: true
####需要检索服务
fetch-registry: true
底层原理:
服务跟踪原理
为了实现请求跟踪,当请求发送到分布式系统的入口端点时, 只需要服务跟踪框架为该请求创建一个唯的跟踪标识, 同时在分布式系统内部流转的时候,框架始终保持传递该唯一标识, 直到返回给请求方为止,这个唯一标识就是前 文中提到的Trace ID。通过Trace ID的记录,我们就能将所有请求过程的日志关联起来。
为了统计各处理单元的时间延迟,当请求到达各个服务组件时,或是处理逻辑到达某个状态时,也通过一个唯一 标识来标记它的开始、 具体过程以及结束,该标识就是前文中提到的Span ID。对于每个Span来说,它必须有开始和结束两个节点,通过记录开始Span和结束Span的时间戳,就能统计出该Span的时间延迟,除了时间戳记录之外,它还可以包含一些其他元数据, 比如事件名称、请求信息等
SpanId记录每一次请求, TraceID记录整个调用链全局ID
TraceId 和 SpanId 在微服务中传递追踪
TraceId记录每一次请求,耗时时间、接口调用关系
TraceId和SpanId在微服务中传递追踪
在微服务中,使用请求头传递TraceId和SpanId,一个TraceId由多个SpanId组合起来。获取到整个微服务调用依赖关系
下一级的parentId就是上一级的spanId 形成一个链
每次请求生成一个新的spanId
在微服务中,使用请求头传递TraceId和SpanId,一个TraceId由多个SpanId组合起来,获取到整个微服务调用依赖关系。
案例如下:
Eureka略
Order:
controller:
import javax.servlet.http.HttpServletRequest; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate; @RestController
public class OrderControler { // RestTemplate 是有SpringBoot Web组件提供 默认整合ribbon负载均衡器
// rest方式底层是采用httpclient技术
@Autowired
private RestTemplate restTemplate; /**
* 在SpringCloud 中有两种方式调用 rest、fegin(SpringCloud)
*
* @return
*/ // 订单服务调用会员服务
@RequestMapping("/getOrder")
public String getOrder() {
// 有两种方式,一种是采用服务别名方式调用,另一种是直接调用 使用别名去注册中心上获取对应的服务调用地址
String url = "http://app-itmayiedu-member/getMember";
String result = restTemplate.getForObject(url, String.class);
System.out.println("订单服务调用会员服务result:" + result);
return result;
} @RequestMapping("/orderToMemberMsg")
public String orderToMemberMsg(HttpServletRequest request) {
System.out.println(
"TraceId:" + request.getHeader("X-B3-TraceId") + ",spanid:" + request.getHeader("X-B3-SpanId"));
// 有两种方式,一种是采用服务别名方式调用,另一种是直接调用 使用别名去注册中心上获取对应的服务调用地址
String url = "http://app-itmayiedu-member/memberAndMsg";
String result = restTemplate.getForObject(url, String.class);
System.out.println("订单服务调用会员服务result:" + result);
return result;
} }
yml:
###订单服务的端口号
server:
port: 8001
###服务别名----服务注册到注册中心名称
spring:
application:
name: app-itmayiedu-order
zipkin:
base-url: http://127.0.0.1:9411/
###全部采集
sleuth:
sampler:
probability: 1.0
eureka:
client:
service-url:
##### 当前会员服务注册到eureka服务地址
defaultZone: http://localhost:8100/eureka
### 需要将我的服务注册到eureka上
register-with-eureka: true
####需要检索服务
fetch-registry: true
启动类:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate; @SpringBootApplication
@EnableEurekaClient
public class AppOrder {
public static void main(String[] args) {
SpringApplication.run(AppOrder.class, args); // 如果使用rest方式以别名方式进行调用依赖ribbon负载均衡器 @LoadBalanced
// @LoadBalanced就能让这个RestTemplate在请求时拥有客户端负载均衡的能力
} // 解决RestTemplate 找不到原因 应该把restTemplate注册SpringBoot容器中 @bean
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
} }
Member:
import javax.servlet.http.HttpServletRequest; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate; @RestController
public class MemberApiController {
@Value("${server.port}")
private String serverPort;
@Autowired
private RestTemplate restTemplate; @RequestMapping("/getMember")
public String getMember(HttpServletRequest request) { return "this is member,我是会员服务,springcloud2.0版本!端口号:" + serverPort
+ request.getHeader("X-B3-TraceId") + ",spanid:" + request.getHeader("X-B3-SpanId"); } @RequestMapping("/memberAndMsg")
public String sndMsg() {
String url = "http://app-itmayiedu-msg/sndMsg";
String result = restTemplate.getForObject(url, String.class);
System.out.println("会员服务调用消息服务result:" + result);
return result;
} }
yml:
###会员项目的端口号
server:
port: 8000
###服务别名----服务注册到注册中心名称
spring:
application:
name: app-toov5-member
zipkin:
base-url: http://127.0.0.1:9411/
###全部采集
sleuth:
sampler:
probability: 1.0 eureka:
client:
service-url:
##### 当前会员服务注册到eureka服务地址
defaultZone: http://localhost:8100/eureka
### 需要将我的服务注册到eureka上
register-with-eureka: true
####需要检索服务
fetch-registry: true
启动类:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate; @SpringBootApplication
@EnableEurekaClient
public class AppMember { // @EnableEurekaClient 将当前服务注册到eureka上
public static void main(String[] args) {
SpringApplication.run(AppMember.class, args);
} // 解决RestTemplate 找不到原因 应该把restTemplate注册SpringBoot容器中 @bean
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
} }
Msg
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; @SpringBootApplication
@RestController
public class MsgController { @RequestMapping("/sndMsg")
public String sndMsg() {
try {
Thread.sleep(5000);
} catch (Exception e) {
// TODO: handle exception
}
return "我是消息服务平台";
} public static void main(String[] args) {
SpringApplication.run(MsgController.class, args);
} }
启动类:
###订单服务的端口号
server:
port: 8003
###服务别名----服务注册到注册中心名称
spring:
application:
name: app-toov5-msg
zipkin:
base-url: http://127.0.0.1:9411/
###全部采集
sleuth:
sampler:
probability: 1.0
eureka:
client:
service-url:
##### 当前会员服务注册到eureka服务地址
defaultZone: http://localhost:8100/eureka
### 需要将我的服务注册到eureka上
register-with-eureka: true
####需要检索服务
fetch-registry: true
Eureka:
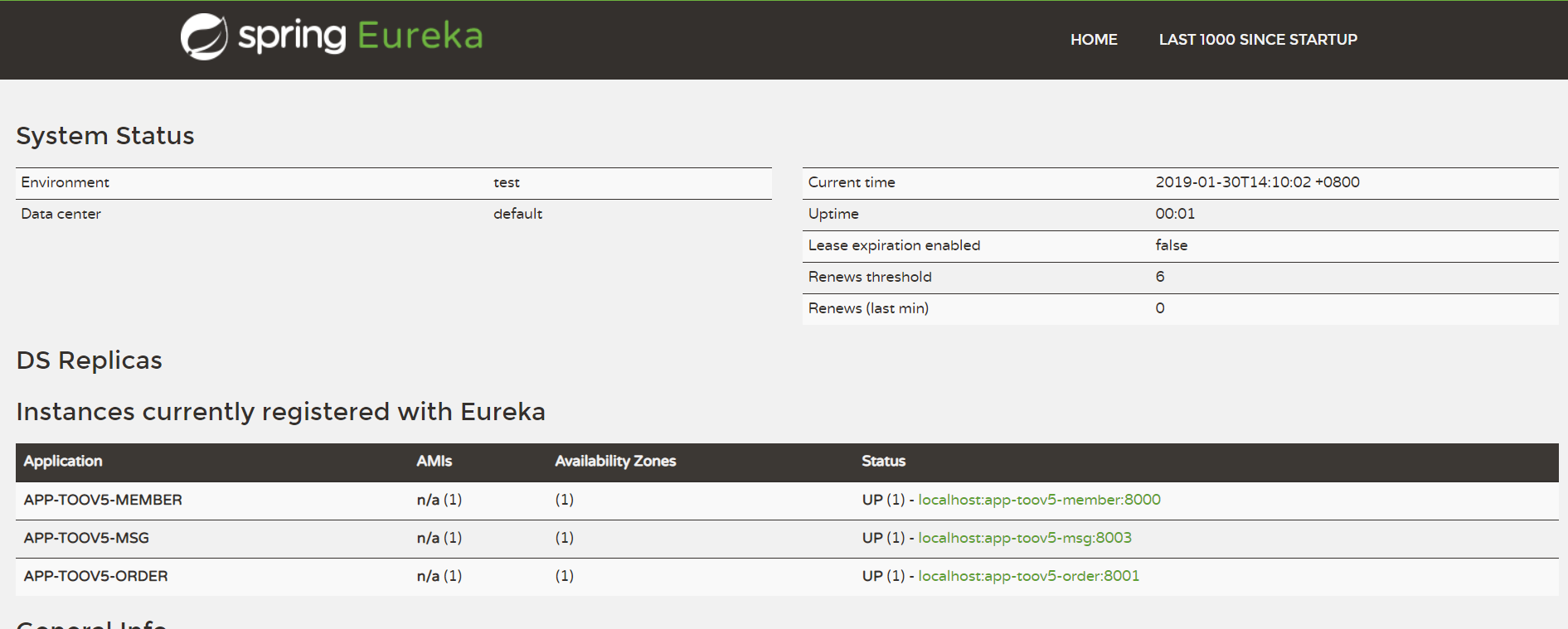
访问: http://127.0.0.1:8001/orderToMemberMsg
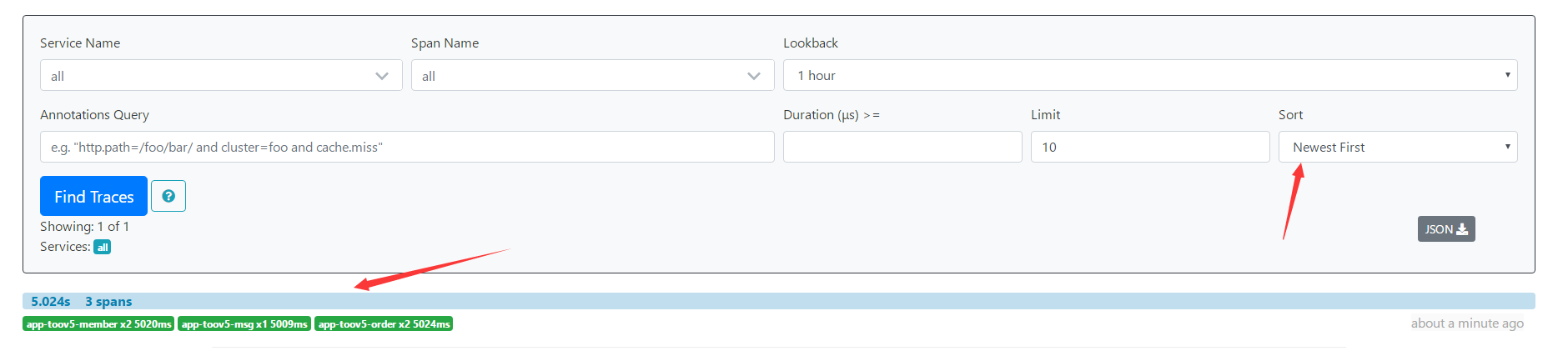
点击上面的实际三5.024s

分布式链路监控与追踪系统Zipkin的更多相关文章
- Spring cloud系列十四 分布式链路监控Spring Cloud Sleuth
1. 概述 Spring Cloud Sleuth实现对Spring cloud 分布式链路监控 本文介绍了和Sleuth相关的内容,主要内容如下: Spring Cloud Sleuth中的重要术语 ...
- 数据追踪系统Zipkin 及其 Zipkin的php客户端驱动hoopak
Zipkin是Twitter的一个开源项目,是一个致力于收集Twitter所有服务的监控数据的分布式跟踪系统,它提供了收集数据,和查询数据两大接口服务.Zipkin 是一款开源的分布式实时数据追踪系统 ...
- 三、链路追踪系统 zipkin
一.构建项目 用到的依赖直接看pom.xml的注释吧 <?xml version="1.0" encoding="UTF-8"?> <proj ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
- Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin[Finchley 版] 发表于 2018-04-24 | 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请 ...
- 每天学点SpringCloud(十二):Zipkin全链路监控
Zipkin是SpringCloud官方推荐的一款分布式链路监控的组件,使用它我们可以得知每一个请求所经过的节点以及耗时等信息,并且它对代码无任何侵入,我们先来看一下Zipkin给我们提供的UI界面都 ...
- Laravel + go-micro + grpc 实践基于 Zipkin 的分布式链路追踪系统 摘自https://mp.weixin.qq.com/s/JkLMNabnYbod-b4syMB3Hw?
分布式调用链跟踪系统,属于监控系统的一类.系统架构逐步演进时,后期形态往往是一个平台由很多不同的服务.组件构成,用户请求过来后,可能会经过其中多个服务,如图 不过,出问题时往往很难排查,如整个请求变慢 ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
随机推荐
- 编写高质量代码--改善python程序的建议(一)
原文发表在我的博客主页,转载请注明出处! 初衷 python是一个入门十分容易的编程语言,但是想要写好python却是一件不容易的事情,如果不是专业使用python的人,只是将python作为一个脚本 ...
- JMeter java.net.URISyntaxException: Illegal character in query at index
请求参数未编码,会造成请求解析失败.把编码勾上,就可以了.
- 【Git和GitHub】学习笔记
1. 书籍推荐: 先看一本比较简单并且好的入门书籍 Git - Book https://git-scm.com/book/zh/v2 2. 书籍理解: Git 有三种状态,你的文件可能处于其中之一: ...
- ThinkPHP中通过URL重写隐藏应用的入口文件index.php的相关服务器的配置
[ Apache ] 将httpd.conf配置文件中mod_rewrite.so所在行前面的‘#’去掉 AllowOverride None 将None改为 All 效果图
- JAVA源码之JDK(一)——java.lang.Object
想要深入学习JAVA,还需追本溯源,从源码学起.这是我目前的想法.如今JAVA各种开源框架涌出,很多JAVA程序员都只停留在如何熟练使用的层次.身为其中一员的我深感惭愧,所以要加快学习的脚步,开始研究 ...
- hdu 1159 Common Subsequence 【LCS 基础入门】
链接: http://acm.hdu.edu.cn/showproblem.php?pid=1159 http://acm.hust.edu.cn/vjudge/contest/view.action ...
- IO流入门-第十一章-PrintStream_PrintWriter
DataInputStream和DataOutputStream基本用法和方法示例 /* java.io.PrintStream:标准的输出流,默认打印到控制台,以字节方式 java.io.Print ...
- python基础之类的封装
从封装本身的意思去理解,封装就好像是拿来一个麻袋,把小猫,小狗,小王八,还有alex一起装进麻袋,然后把麻袋封上口子.但其实这种理解相当片面 一 封装什么 你钱包的有多少钱(数据的封装) 你的性取向( ...
- JS给TR隔行换色,鼠标经过有动感
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DT ...
- screenX clientX pageX区别
screenX:鼠标位置相对于用户屏幕水平偏移量,而screenY也就是垂直方向的,此时的参照点也就是原点是屏幕的左上角. clientX:跟screenX相比就是将参照点改成了浏览器内容区域的左上角 ...