scrapy的简单使用以及相关设置属性的介绍
0. 楔子(一个最简单的案例)
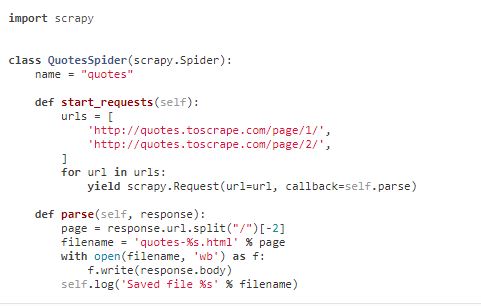
1.scrapy.Spider
scrapy.spiders.Spider
name
allowed_domains
start_urls
custom_settings
:在爬虫运行时用这个属性里的设置覆盖默认设置,它本身是字典格式的。
Crawler
该属性在初始化类之后由from_crawler()类方法设置,并链接到此蜘蛛实例绑定到的Crawler对象。
爬虫程序在项目中封装了大量的组件,用于单一入口访问(例如扩展,中间件,信号管理器等)。 请参阅Crawler API以了解更多关于它们的信息
Settings
这个爬虫的设置
Logger
日志
from_crawler(crawler, *args, **kwargs)
创建自己的爬虫,一般不需要重写,默认设置在scrapy.spider._init_py里。
start_requests()
返回一个生成器,用来发送爬取请求。Start_url[]中的url地址会默认的调用这个函数发送网页爬取请求。
parse(response)
解析响应,从返回的网页响应中提取数据。
log(message[, level, component])
设置爬虫的日志,
closed(reason)
关闭爬虫
2.CrawlSpider
scrapy.spiders.CrawlSpider
相较于spider.Spider它提供rules对象以便爬取跟随连接,实现多级爬虫
Rules对象定义如下,爬虫根据rules定义的规则爬取网站,多个规则匹配同一条连接的时候按照顺序只输出第一条连接。
parse_start_url(response):
处理响应,返回一个Item或者request,或者一个包含两者的可迭代对象。
Rules类定义如下
Class scrapy.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None,process_links=None, process_request=None)
link_extractor是连接提取器类,提取需要的链接。
Callback回调函数,解析或者爬取每一条提取出来的链接,返回一个Item/response列表,或者一个同时包括两者的列表。
Cb_kwargs回调函数字典类型的参数
Follow 对通过这个规则抽取出来的链接是否跟进,如果没有回调函数,默认为True,否则默认为False
Process-links是一个函数或则一个爬虫的名字,对提取出来的链接起一个过滤的作用。
Eg:
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com']
rules = (
# Extract links matching 'category.php' (but not matching 'subsection.php')
# and follow links from them (since no callback means follow=True by default).
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
def parse_item(self, response):
self.logger.info('Hi, this is an item page! %s', response.url)
item = scrapy.Item()
item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (\d+)')
item['name'] = response.xpath('//td[@id="item_name"]/text()').extract()
item['description'] = response.xpath('//td[@id="item_description"]/text()').extract()
return item
2.XMLFeedSpider
scrapy.spiders.XMLFeedSpider
主要用来爬取XML网页
3. CSVFeedSpider
主要用来解析CSF网页
4. SitemapSpider
scrapy.spiders.SitemapSpider
解析网站的robots.txt规则,建立网站地图,实现整站爬取(这个整站爬取是被动的,即你必须知道robots,或提前输入关于这个网站需要爬取的链接)
sitemap_urls一个需要爬取的url地址的列表
sitemap_rules一个存放爬取规则的列表,爬取规则为一个元组(regex, callback)
sitemap_follow所爬取的url地址所共同匹配的正则表达式列表
sitemap_alternate_links如果为真,取回除语言外完全相同的网址,如http://example.com/en
,默认为假。
5. 选择器:
Eg:
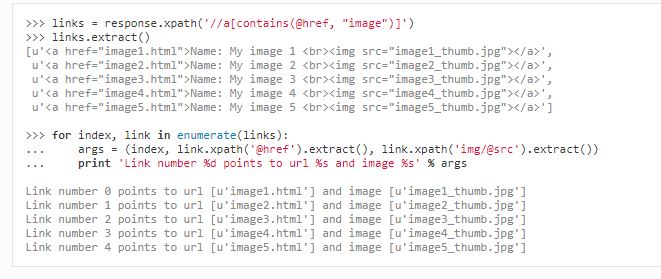
同时,选择器可以使用正则表达式

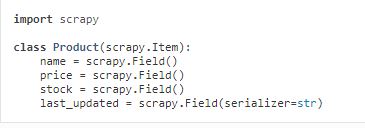
3.Item
将非结构化的数据变成结构化数据,
在classscrapy.item.Item([arg])中声明
使用条目装载机装载条目,
Eg:

3. Item Pipeline
classscrapy.loader.ItemLoader([item, selector, response, ]**kwargs)
当爬虫爬取一个条目时,这个条目将被发送到项目管道,通过依次执行的几个组件处理数据,每个管道组件(有时也称为“管道”)是一个实现简单方法的Python类。
项目管道的典型用途是:
- 获取干净的HTML数据
- 验证爬取的数据(检查项目是否包含某些字段)
- 检查重复(并删除它们)
- 将爬取的项目存储在数据库中
每个项目管道组件是一个Python类,必须实现process_item(self, item, spider)方法:
process_item(self, item, spider):返回一个字典或者一个Item类或者或者一个twited deferred(https://twistedmatrix.com/documents/current/core/howto/defer.html)对象或者一个异常。
Spider与item是对应的关系。
open_spider(self, spider):当spider开始运行时,运行这个函数
close_spider(self, spider)
from_crawler(cls, crawler):如果存在,则调用此类方法从Crawler创建管道实例。 它必须返回一个新的管道实例。 抓取对象提供对所有Scrapy核心组件的访问,如设置和信号; 这是管道访问它们并将其功能挂接到Scrapy的一种方式。
Eg:
异常:

存储到json:

存储到MongoDB

去重:
假设ID唯一

4.Requests
Class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback, flags])
由spider产生发送到downloader
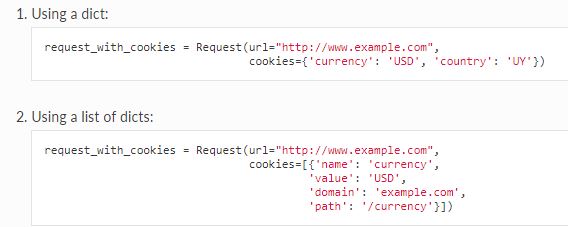
避免与现有cookies合并

priority (int):设置爬取的优先级,默认是0;
dont_filter(boolean)参数为true是表示这个请求不应该被调度器过滤掉。 当您想要多次执行相同的请求时使用此选项,以忽略重复过滤器。 小心使用它,否则你将进入爬行循环。 默认为False。
errback (callable)异常处理函数
flags (list):发送到请求的标志可用于日志记录或类似的目的。
Request.meta special keys:Request.meta属性可以包含任意的数据,但是Scrapy和它的内置扩展可以识别一些特殊的键。
Those are:
- · dont_redirect
- · dont_retry
- · handle_httpstatus_list
- · handle_httpstatus_all
- · dont_merge_cookies (see cookies parameter of Request constructor)
- · cookiejar
- · dont_cache
- · redirect_urls
- · bindaddress
- · dont_obey_robotstxt
- · download_timeout
- · download_maxsize
- · download_latency
- · download_fail_on_dataloss
- · proxy
- · ftp_user (See FTP_USER for more info)
- · ftp_password (See FTP_PASSWORD for more info)
- · referrer_policy
- · max_retry_times
class scrapy.http.FormRequest(url[, formdata, ...]):
requests的子类,主要用于表单处理
类方法:
from_response(response[, formname=None, formid=None, formnumber=0,formdata=None, formxpath=None, formcss=None, clickdata=None, dont_click=False, ...])
返回一个新的FormRequest对象,其表单字段值预填充在给定响应中包含的HTML <form>元素中。 有关示例,模拟用户登录。

该策略默认情况下会自动模拟任何可点击的表单控件(如<input type =“submit”>)的点击。 即使这是相当方便的,而且往往是所期望的行为,有时它可能会导致难以调试的问题。 例如,处理使用javascript填充和/或提交的表单时,默认的from_response()行为可能不是最合适的。 要禁用此行为,可以将dont_click参数设置为True。 另外,如果你想改变点击的控件(而不是禁用它),你也可以使用clickdata参数。
|
参数: |
|
5.response
class scrapy.http.Response(url[, status=200, headers=None, body=b'', flags=None, request=None])
urljoin(url):可以将相对url地址结合成绝对url地址
follow(url, callback=None, method='GET', headers=None, body=None, cookies=None, meta=None,encoding='utf-8', priority=0, dont_filter=False, errback=None):
返回请求实例以跟随链接url。 它接受与Request .__ init__方法相同的参数,但是url可以是相对URL或scrapy.link.Link对象,不仅是绝对URL。
除了绝对/相对URL和链接对象,TextResponse提供了一个支持选择器的follow()方法,这个两个函数可以用来翻页。
Eg:
Urljoin
Follow()

classscrapy.http.TextResponse(url[, encoding[, ...]]):response的子类,增加了编码功能。
新的属性有:
Text:Response body, as unicode.
Encoding:与此响应编码的字符串。 通过尝试以下机制来解决编码问题:
10.1 在构造函数编码参数中传递的编码
10.2在Content-Type HTTP头中声明的编码。 如果这种编码是无效的(即未知的),它将被忽略,并尝试下一个解析机制。
10.3在响应正文中声明的编码。 TextResponse类不提供任何特殊的功能。 但是,HtmlResponse和XmlResponse类可以。
10.4通过查看响应主体来推断编码。 这是更脆弱的方法,也是最后一个尝试。
Selector;选择器实例化类
xpath(query):可以直接用response.xpath('//p')
css(query):可以直接用response.css('p')class scrapy.http.HtmlResponse(url[, ...]):HtmlResponse类是TextResponse的一个子类,它通过查看HTML meta http-equiv属性来添加编码自动发现支持,对应10.3。
class scrapy.http.XmlResponse(url[, ...]):同上。
10.Link Extractors连接提取器
接口在scrapy.linkextractors.LinkExtractor
每个链接提取器唯一的公共方法是extract_links,它接收一个Response对象并返回一个scrapy.link.Link对象列表。 链接提取器的意图是实例化一次,他们的extract_links方法多次调用不同的响应来提取链接。
链接提取器通过一组规则在CrawlSpider类中使用(在Scrapy中可用),但是即使您不从CrawlSpider继承,也可以在您的蜘蛛中使用它,因为它的目的非常简单:提取链接。
Class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(),deny_domains=(), deny_extensions=None, restrict_xpaths=(), restrict_css=(), tags=('a', 'area'), attrs=('href', ),canonicalize=False, unique=True, process_value=None, strip=True):
LxmlLinkExtractor是推荐的链接提取器,具有方便的过滤选项。 它使用lxml健壮的HTMLParser实现。
参数:
allow(一个正则表达式(或者列表)) - 一个正则表达式(或者正则表达式列表),为了被提取,(绝对)url必须匹配。如果没有给(或空),它将匹配所有链接。
deny(正则表达式(或列表)) - (绝对)网址必须匹配才能排除(即未提取)的单个正则表达式(或正则表达式列表)。它优先于allow参数。如果没有给(或空)它不会排除任何链接。
allow_domains(str或list) - 一个单独的值或一个包含域的字符串列表,这些字段将被用于提取链接。
deny_domains(str或者list) - 一个单独的值或者一个包含域的字符串列表,不会被认为是用于提取链接。
deny_extensions(list) - 包含扩展的单个值或字符串列表,在提取链接时应被忽略。如果没有给出,它将默认为在scrapy.linkextractors包中定义的IGNORED_EXTENSIONS列表。
restrict_xpaths(str或list) - 是一个XPath(或XPath的列表),它定义了应该从中提取链接的响应内的区域。如果给定,只有这些XPath选择的文本将被扫描链接。看下面的例子。
restrict_css(str或者list) - 一个CSS选择器(或者选择器列表),它定义了应该从中提取链接的响应内的区域。具有与restrict_xpaths相同的行为。
tags(str或list) - 提取链接时要考虑的标记或标记列表。默认为('a','area')
attrs(list) - 查找提取链接时仅考虑在tags参数中指定的标签时应考虑的属性或属性列表。默认为('href',)
unique(boolean) - 是否应该对提取的链接应用重复过滤。
process_value(可调用) - 接收从tags和attrs中提取的每个值并且可以修改该值并返回新的值,或者返回None来忽略该链接的功能。如果没有给出,process_value默认为lambda x:x。
canonicalize(Boolean) - 规范每个提取的URL(使用w3lib.url.canonicalize_url)。 默认为False。 请注意,canonicalize_url是用于重复检查; 它可以更改服务器端可见的URL,因此对于使用规范化和原始URL的请求,响应可能会有所不同。 如果您使用LinkExtractor来跟踪链接,那么保持默认的canonicalize = False更健壮。
strip(boolean) - 是否从提取的属性中去除空白。 根据HTML5标准,必须从<a>,<area>和许多其他元素,<img>,<iframe>元素的src属性等从href属性中去除前导和尾随空白,因此LinkExtractor会在默认情况下删除空格字符。 设置strip = False将其关闭(例如,如果您从允许前/后空格的元素或属性中提取url)。
11. Setting
Setting源文件位置:scrapy.setting,default_settings,py
11.1 为每一个爬虫定制自己的设置选项

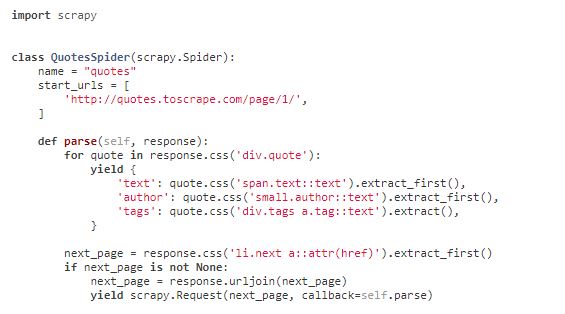
11.2 在命令行窗口下定制设置选项
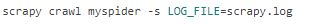
11.3 在项目的setting.py里直接修改
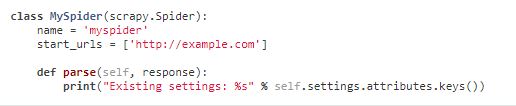
11.4 访问setting
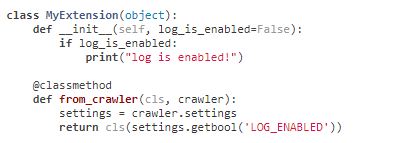
11.5 通过from_crawler()函数访问setting
11.6 默认的设置
AWS_ACCESS_KEY_ID:AWS访问口令字
AWS_SECRET_ACCESS_KE:AWS访问秘钥
BOT_NAME:项目名称
CONCURRENT_ITEMS:在项目处理器(也称为Item Pipeline)中并行处理的最大并行items数(每个响应)。
CONCURRENT_REQUESTS:Scrapy下载器将执行的并发(即同时)请求的最大数量。
CONCURRENT_REQUESTS_PER_DOMAIN: 对任何单个域执行的并发(即同时)请求的最大数目。
CONCURRENT_REQUESTS_PER_IP: 对任何单个IP执行的并发(即同时)请求的最大数目。
DEFAULT_ITEM_CLASS: Default: 'scrapy.item.Item'
DEFAULT_REQUEST_HEADERS:

DEPTH_LIMIT: Default:0
DEPTH_PRIORITY:默认是0,正值是广度优先爬取,负值深度优先爬取。
DEPTH_STATS:Default:True,是否收集最大的深度统计。
DEPTH_STATS_VERBOSE:默认是FALSE, 是否收集详细深度统计信息。 如果启用此功能,则会在统计信息中收集每个深度的请求数量。
DNSCACHE_ENABLED:Default:True是否启用DNS内存中缓存。
DNSCACHE_SIZE:Default:10000
DNS_TIMEOUT:60s
DOWNLOADER:Default: 'scrapy.core.downloader.Downloader'
DOWNLOADER_HTTPCLIENTFACTORY:Default:'scrapy.core.downloader.webclient.ScrapyHTTPClientFactory'
DOWNLOADER_CLIENT_TLS_METHOD:Default:'TLS',使用此设置可以自定义默认HTTP / 1.1下载器使用的TLS / SSL方法。
该设置必须是以下字符串值之一:
'TLS':映射到OpenSSL的TLS_method()(又名SSLv23_method()),它允许从平台支持的最高层开始进行协议协商。 默认,推荐
'TLSv1.0':这个值强制HTTPS连接使用TLS版本1.0; 设置这个如果你想Scrapy <1.1的行为
“TLSv1.1”:强制TLS版本1.1
“TLSv1.2”:强制TLS版本1.2
“SSLv3”:强制SSL版本3(不推荐)
DOWNLOADER_MIDDLEWARES:Default:{}
DOWNLOADER_MIDDLEWARES_BASE:
包含Scrapy中默认启用的下载器中间件的字典。 低序靠近引擎,高序靠近下载器。 您不应该在您的项目中修改此设置,而是修改DOWNLOADER_MIDDLEWARES。
DOWNLOADER_STATS:默认值:True,是否启用下载器统计信息收集。
DOWNLOAD_DELAY:默认值:0
从同一网站下载连续页面之前,下载者应等待的时间(以秒为单位)。 这可以用来限制爬行速度,以避免打太大的服务器。 支持十进制数字。 例:
DOWNLOAD_DELAY = 0.25#250毫秒的延迟
此设置也受到RANDOMIZE_DOWNLOAD_DELAY设置(默认情况下启用)的影响。 默认情况下,Scrapy不会在两次请求之间等待一段固定时间,而是使用0.5 * DOWNLOAD_DELAY和1.5 * DOWNLOAD_DELAY之间的随机时间间隔。
当CONCURRENT_REQUESTS_PER_IP非零时,每个IP地址而不是每个域强制执行延迟。
您也可以通过设置download_delay spider属性来更改每个蜘蛛的此设置。
DOWNLOAD_HANDLERS:默认:{}
包含在您的项目中启用的请求下载程序处理程序的字典。 例子,请参阅DOWNLOAD_HANDLERS_BASE格式。
DOWNLOAD_HANDLERS_BASE:

DOWNLOAD_TIMEOUT:默认:180
下载器在超时之前等待的时间(以秒为单位)
可以使用download_timeout spider属性和使用download_timeout Request.meta项的每个请求来为每个蜘蛛设置此超时。
DOWNLOAD_MAXSIZE:每个响应最大是下载尺寸,默认是:1073741824 (1024MB)
可以使用download_timeout spider属性和使用download_timeout Request.meta项的每个请求来为每个蜘蛛设置此超时。
如果设为0,则表示没有限制。
DOWNLOAD_WARNSIZE:默认:33554432(32MB)
下载器将开始发出警告的响应大小(以字节为单位)。
如果你想禁用它设置为0。
DOWNLOAD_FAIL_ON_DATALOSS:默认值:True.
损坏了的响应是否引发异常,即声明的Content-Length与服务器发送的内容不匹配,或者分块的响应没有正确完成。 如果为True,则这些响应会引发ResponseFailed([_DataLoss])错误。 如果为False,则通过这些响应,并将标志数据信息添加到响应中,即:response.flags中的'dataloss'为True。
或者,可以通过使用download_fail_on_dataloss Request.meta键为False来设置每个请求的基础。
在这几种情况下,从服务器配置错误到网络错误到数据损坏,都可能发生错误的响应或数据丢失错误。 由用户决定是否有意义处理破坏的回应,因为他们可能包含部分或不完整的内容。 如果设置:RETRY_ENABLED为True,并且此设置设置为True,则ResponseFailed([_ DataLoss])失败将照常重试。
DUPEFILTER_CLASS:默认:'scrapy.dupefilters.RFPDupeFilter',用于检测和过滤重复请求的类。
基于请求指纹的默认(RFPDupeFilter)过滤器使用scrapy.utils.request.request_fingerprint函数。 为了改变检查重复的方式,你可以继承RFPDupeFilter并覆盖它的request_fingerprint方法。 这个方法应该接受scrapy Request对象并返回它的指纹(一个字符串)。
您可以通过将DUPEFILTER_CLASS设置为“scrapy.dupefilters.BaseDupeFilter”来禁用对重复请求的过滤。 但是这样设置可能会进入爬行循环。 在不应该被过滤的特定请求上,将dont_filter参数设置为True通常是个好主意。
DUPEFILTER_DEBUG:默认:False
默认情况下,RFPDupeFilter只记录第一个重复的请求。 将DUPEFILTER_DEBUG设置为True将使其记录所有重复的请求。
EDITOR:默认:vi(在Unix系统上)或IDLE编辑器(在Windows上)
编辑器用于使用编辑命令编辑蜘蛛。 此外,如果EDITOR环境变量已设置,则编辑命令将优先于默认设置
EXTENSIONS:默认:: {}
包含在您的项目中启用的扩展的字典,以及他们的顺序。
EXTENSIONS_BASE:
FTP_PASSIVE_MODE:默认值:True
启动FTP传输时是否使用被动模式。
FTP_PASSWORD:默认值:“guest”
Request meta中没有“ftp_password”时用于FTP连接的密码。
FTP_USER:默认:“anonymous”
Request meta中没有“ftp_user”时用于FTP连接的用户名。
ITEM_PIPELINES:默认:{}
包含要使用的项目管道的字典及其顺序。 顺序值是任意的,但通常在0-1000范围内定义它们。低顺序的在高顺序之前执行。
LOG_ENABLED:Default:True
LOG_ENCODING:Default:'utf-8'
LOG_FILE:默认:None
用于记录输出的文件名。 如果没有,将使用标准(print)错误。
LOG_FORMAT:Default:'%(asctime)s [%(name)s] %(levelname)s: %(message)s'
LOG_DATEFORMAT:Default:'%Y-%m-%d %H:%M:%S'
LOG_LEVEL:Default:'DEBUG'
LOG_STDOUT:默认:False
如果为True,则所有标准输出(和错误)将被重定向到日志。 例如,如果您打印“hello”,它将出现在Scrapy日志中。
LOG_SHORT_NAMES:默认:False
如果为True,日志将只包含根路径。 如果设置为False,则显示负责日志输出的组件
MEMDEBUG_ENABLED:默认:False
是否启用内存调试
MEMDEBUG_NOTIFY:默认:[]
当启用内存调试时,如果此设置不为空,内存报告将被发送到指定的地址,否则报告将被写入日志。
Example:MEMDEBUG_NOTIFY = ['user@example.com']
MEMUSAGE_ENABLED:默认值:True
范围:scrapy.extensions.memusage
是否启用内存使用扩展。 该扩展跟踪进程使用的峰值内存(将其写入统计信息)。 当超过内存限制(见MEMUSAGE_LIMIT_MB)时,它也可以选择关闭Scrapy进程,并在发生这种情况时通过电子邮件通知(请参阅MEMUSAGE_NOTIFY_MAIL)。
MEMUSAGE_NOTIFY_MAIL:默认:False
范围:scrapy.extensions.memusage
如果已达到内存限制,则通知电子邮件列表。
例:MEMUSAGE_NOTIFY_MAIL = ['user@example.com']
REDIRECT_MAX_TIMES:Default:20
REDIRECT_PRIORITY_ADJUST:默认值:+2
范围:scrapy.downloadermiddlewares.redirect.RedirectMiddleware
调整相对于原始请求的重定向请求优先级:
积极的优先级调整(默认)意味着更高的优先级。
负面的优先调整意味着低优先级。
RETRY_PRIORITY_ADJUST:默认值:-1
范围:scrapy.downloadermiddlewares.retry.RetryMiddleware
调整相对于原始请求的重试请求优先级:
积极的优先调整意味着更高的优先。
否定优先级调整(默认)意味着优先级较低
ROBOTSTXT_OBEY:默认:False
范围:scrapy.downloadermiddlewares.robotstxt
如果启用,Scrapy将尊重robots.txt策略。 欲了解更多信息,请参阅RobotsTxtMiddleware。
SCHEDULER:默认:'scrapy.core.scheduler.Scheduler'
调度程序用于抓取。
SCHEDULER_DEBUG:Default: False
SPIDER_MIDDLEWARES:Default:{}
SPIDER_MIDDLEWARES_BASE:
SPIDER_MODULES:Default:[]
URLLENGTH_LIMIT:Default:2083
USER_AGENT:Default:"Scrapy/VERSION (+http://scrapy.org)"
12.Sending e-mail
http://python.usyiyi.cn/translate/scrapy_14/index.html
scrapy的简单使用以及相关设置属性的介绍的更多相关文章
- 如果需要将UIView的4个角全部都为圆角,做法相当简单,只需设置其Layer的cornerRadius属性即可
如果需要将UIView的4个角全部都为圆角,做法相当简单,只需设置其Layer的cornerRadius属性即可(项目需要使用QuartzCore框架).而若要指定某几个角(小于4)为圆角而别的不变时 ...
- C#反射技术的简单操作(读取和设置类的属性)
public class A { public int Property1 { get; set; } } static void Main(){ A aa = new A(); Type type ...
- JSP指令用来设置整个JSP页面相关的属性
JSP 指令 JSP指令用来设置整个JSP页面相关的属性,如网页的编码方式和脚本语言. 语法格式如下: <%@ directive attribute="value" %&g ...
- jquery简单使用(看教程:快全有实例)(固定样式:$().val()设置属性,$().click()设置方法)
jquery简单使用(看教程:快全有实例)(固定样式:$().val()设置属性,$().click()设置方法) 一.总结 1.jquery不懂之处直接看教程,案例都有,有简单又快 2.jquery ...
- Scrapy 框架,爬虫文件相关
Spiders 介绍 由一系列定义了一个网址或一组网址类如何被爬取的类组成 具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. 简单来说就是帮助你爬取数据的地方 内部行为 #1.生成初始的Re ...
- zend studio 9.0.4 破解、汉化和字体颜色及快捷键相关设置
转载:http://www.penglig.com/post-45.html 下载:http://www.geekso.com/component/zendstudio-downloads/ 破解:h ...
- CSS.01 -- 选择器及相关的属性文本、文字、字体、颜色、
与html相比,Css支持更丰富的文档外观,Css可以为任何元素的文本和背景设置颜色:允许在任何元素外围设置边框:允许改变文本的大小,装饰(如下划线),间隔,甚至可以确定是否显示文本. 什么是CSS? ...
- 你所不知道的 CSS 阴影技巧与细节 滚动视差?CSS 不在话下 神奇的选择器 :focus-within 当角色转换为面试官之后 NPOI 教程 - 3.2 打印相关设置 前端XSS相关整理 委托入门案例
你所不知道的 CSS 阴影技巧与细节 关于 CSS 阴影,之前已经有写过一篇,box-shadow 与 filter:drop-shadow 详解及奇技淫巧,介绍了一些关于 box-shadow ...
- zend studio 破解、汉化和字体颜色及快捷键相关设置
下载:http://www.geekso.com/component/zendstudio-downloads/ 破解:http://www.geekso.com/ZendStudio9-key/ 注 ...
随机推荐
- mysql与sql server参照对比学习mysql
mysql与sql server参照对比学习mysql 关键词:mysql语法.mysql基础 转自桦仔系列:http://www.cnblogs.com/lyhabc/p/3691555.html ...
- SQL JOIN使用方法
(转自W3School相关教程:http://www.w3school.com.cn,W3School是不错的在线教程,简洁高效!) 下面列出不同的SQL JOIN类型,以及他们之间的差异: JOIN ...
- 其他机器访问本机redis服务器
- LeetCode:组合总数II【40】
LeetCode:组合总数II[40] 题目描述 给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candi ...
- 12 Spring框架 SpringDAO的事务管理
上一节我们说过Spring对DAO的两个支持分为两个知识点,一个是jdbc模板,另一个是事务管理. 事务是数据库中的概念,但是在一般情况下我们需要将事务提到业务层次,这样能够使得业务具有事务的特性,来 ...
- Android 6.0 Kotlin 蓝牙BLE扫描(改为指定时间没有发现新设备后停止扫描使用interface)
package com.arci.myapplication import android.os.Bundleimport android.support.design.widget.Snackbar ...
- MongoRepository动态代理及jpa方法解析源码分析
public interface FzkRepository extends MongoRepository<Fzk, String> { Fzk findByName(String na ...
- 【Flask】Flask Cookie操作
### 什么是cookie:在网站中,http请求是无状态的.也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户.cookie的出现就是为了解决这个问题,第 ...
- MySQL5.7导入数据报错ERROR 1067 (42000) at line 1015: Invalid default value for 'service_time'
解决办法: 修改my.cnf,[mysqld] 下面添加sql_mode=STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_U ...
- Go语言学习之运算符(The way to go)
生命不止,继续go go go 今天介绍go中的运算符. 运算符大概分为: Arithmetic Operators Relational Operators Logical Operators Bi ...