Flink基本概念
Flink基本概念
1.The history of Flink?
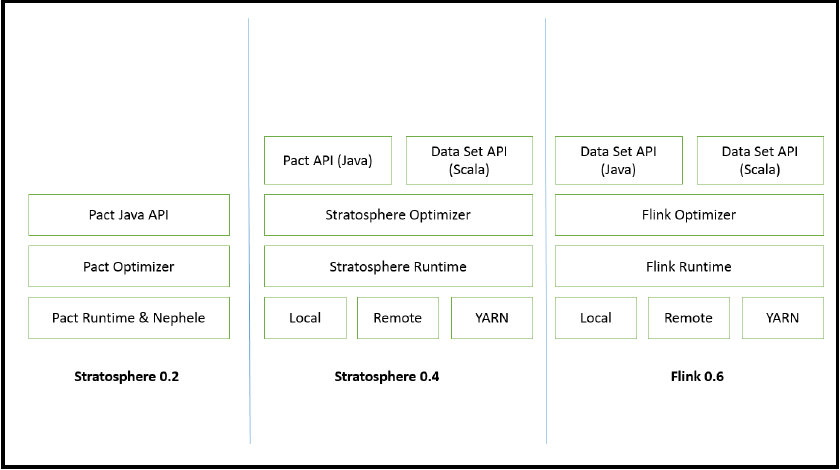
2.What is Flink?
Apache Flink是一个开源的分布式、高性能、高可用、准确的流处理框架,主要由Java代码实现,支持实时流(stream)处理和批(batch)处理,批数据只是流数据的一个极限的特例。原生支持了迭代管理、内存计算和程序优化。
3.The Feature of Flink?
流式优先(streaming-first:连续处理),容错(fault-tolerant:有状态的计算),可伸缩(scalable:可支持上千个节点),性能(performance:高吞吐-每秒处理的数据量很大、低延迟-数据产生时Flink立刻可以处理掉 数据的产生到处理间隔的时间很短)。
4.The Architecture of Flink?
(1)部署deploy : 支持local(single jvm)、支持cluster(standalone、yarn)、支持cloud(GCE、EC2) (2)核心core : 分布式流处理框架 (3)APIs : DataStream API、DataSet API (4)Libraries : DataStream API -- CEP、Table,DataSet API -- FLinkML、Gelly、Table

5.The basic components of Flink?
Data Source、Transformations、Data Sink
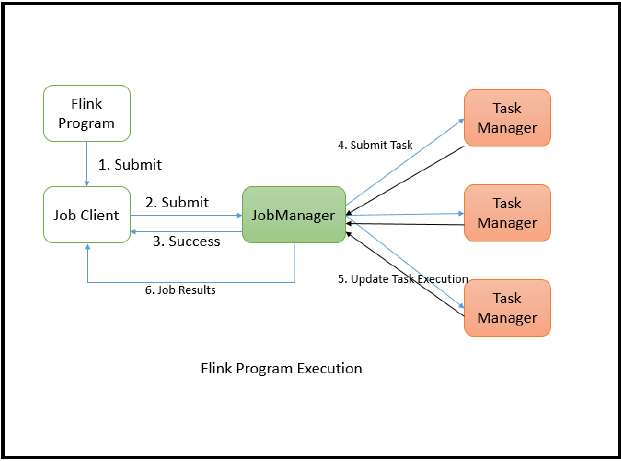
6.The Distributed Execution about Flink?
7.The different between Batch Processing and Streaming Processing?
流处理是一个节点把一条记录处理完后序列化到缓存里另一个节点立刻把数据从缓存中拉过去进行处理,批处理是一个节点处理一条记录放入缓存中另一个节点不会立刻从缓存中拉取记录直到所有的记录都执行完为止在统一从缓存里拉取数据。
8.The diagram of Flink Cluster?

9.The application scene of Flink?
优化电商网站的实时搜索结果如阿里巴巴的实时更新产品细节使用Flink,实时更新库存细节使用Blink。
10.Flink vs Storm vs Spark Streaming vs Trident?
Flink可以通过设置阈值来实现流处理或批处理,如果将阈值设为0那么就相和Storm一样的实时流处理来一条数据处理一条,真正的实现了低延迟但是相对的吞吐量会降低,如果阈值设为无限大相当于批处理一样那么吞吐量会提高却无法实现低延迟的效果,当然根据实际情况可以吧把值设为合适的值。Storm就是实时流处理来一条数据处理一条,保证数据至少被处理一次,所以可能会处理重复,其他三者都是保证了仅一次的处理。Spark Streaming是微批处理(mirco-batching),本质上不属于实时流处理,而是每隔一定的时间段会处理一次数据,一批一批的小批量处理。Trident是基于Storm的一个封装,是一批一批的小批量处理。
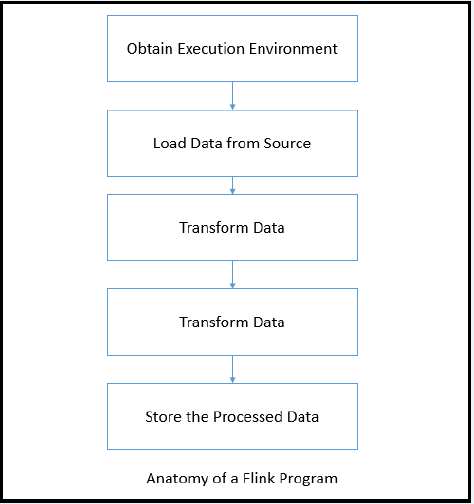
11.Flink execution process?
Flink基本概念的更多相关文章
- Flink资料(1)-- Flink基础概念(Basic Concept)
Flink基础概念 本文描述Flink的基础概念,翻译自https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/con ...
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- 入门大数据---Flink核心概念综述
一.Flink 简介 Apache Flink 诞生于柏林工业大学的一个研究性项目,原名 StratoSphere .2014 年,由 StratoSphere 项目孵化出 Flink,并于同年捐赠 ...
- Flink基础概念入门
Flink 概述 什么是 Flink Apache Apache Flink 是一个开源的流处理框架,应用于分布式.高性能.高可用的数据流应用程序.可以处理有限数据流和无限数据,即能够处理有边界和无边 ...
- flink学习笔记-快速生成Flink项目
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Apache Flink CEP 实战
本文根据Apache Flink 实战&进阶篇系列直播课程整理而成,由哈啰出行大数据实时平台资深开发刘博分享.通过一些简单的实际例子,从概念原理,到如何使用,再到功能的扩展,希望能够给打算使用 ...
- 带你玩转Flink流批一体分布式实时处理引擎
摘要:Apache Flink是为分布式.高性能的流处理应用程序打造的开源流处理框架. 本文分享自华为云社区<[云驻共创]手把手教你玩转Flink流批一体分布式实时处理引擎>,作者: 萌兔 ...
- 第03讲:Flink 的编程模型与其他框架比较
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 本课时我们主要介绍 ...
- Flink Program Guide (1) -- 基本API概念(Basic API Concepts -- For Java)
false false false false EN-US ZH-CN X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-n ...
随机推荐
- python 替换指定目录下,所有文本字符串
网页保存后,会把js文件起名为.下载,html里面的引用也会有,很不美观,解决方案:用python替换字符串 import os import re """将当前目录下所 ...
- SQL Server ->> 斐波那契数列(Fibonacci sequence)
斐波那契数列(Fibonacci sequence)的T-SQL实现 ;WITH T AS ( AS BIGINT) AS curr, CAST(NULL AS BIGINT) AS prv UNIO ...
- shell脚本需求
需求一:写一个脚本 1.设定变量FILE的值为/etc/passwd 2.依次向/etc/passwd中的每个用户问好,并且说出对方的ID是什么 形如:(提示:LINE=`wc -l /etc/pas ...
- mongoDB 创建数据库、删除数据库
创建数据库 use 命令 MongoDB 用 use + 数据库名称 的方式来创建数据库.use 会创建一个新的数据库,如果该数据库存在,则返回这个数据库. 语法格式 use 语句的基本格式如下: u ...
- pycharm 2016注册码
43B4A73YYJ-eyJsaWNlbnNlSWQiOiI0M0I0QTczWVlKIiwibGljZW5zZWVOYW1lIjoibGFuIHl1IiwiYXNzaWduZWVOYW1lIjoiI ...
- 类图(Rose) - Windows XP经典软件系列
版权声明:本文为xiaobin原创文章.未经博主同意不得转载. https://blog.csdn.net/xiaobin_HLJ80/article/details/24584625 ...
- StringUtils工具类介绍
1 abbreviate方法缩写一段文字 StringUtils.abbreviate("abcdefghijklmno", -1, 10) = "abcdefg...& ...
- 针对Restful风格参数传递的请求获取真实url
昨天遇到这样一个问题,先简单介绍下. 业务场景 我们想要统计热点请求URL,进而进行分析优化 方案 通过过滤器获取到请求url(调用方法request.getservletpath),通过redis进 ...
- PHP------XML
XML XML的含义:可扩展标记语言,设计出来的目的是:传输数据 HTML的含义:超文本标记语言,设计出来的目的是:显示数据 它们两个设计出来的目的是不一样的. 它们两个都是标记语言,相似性比较高. ...
- EasyUI使用之鼠标双击事件
easyui鼠标双击事件,使用 onDblClickRow(index, row) 事件,在用户双击一行的时候触发,参数包括: index:点击的行的索引值,该索引值从0开始. row:对应于点击行的 ...