【Spark】Spark性能优化之Whole-stage code generation
一、技术背景
Spark1.x版本中执行SQL语句,使用的是一种最经典,最流行的查询求职策略,该策略主要基于 Volcano Iterator Model(火山迭代模型)。一个查询会包含多个Operator,每个Operator都会实现一个接口,提供一个next()方法,该方法返回Operator Tree的下一个Operator,能够让查询引擎组装任意Operator,而不需要去考虑每个Operator具体的处理逻辑,所以Volcano Iterator Model 才成为了20年中SQL执行引擎最流行的一种标准。
比如如下SQL语句:
select count(*) from employees where salary == 1000
使用Java代码手写实现的SQL功能的代码如下
int count = 0;
for(emp : employees){
if(emp == 1000){
count += 1;
}
}
有人实验了Volcano Iterator Model 方式与直接手写Java代码实现的方式,直接手写Java代码是专门为了实现某个指定的功能而编写的,不具有良好的组装性和扩展性,这两种方式进行了性能的对比结果如下图。
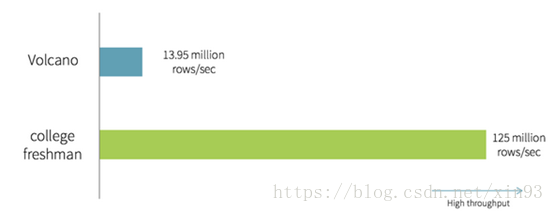
可以看到直接手写Java代码实现某一特定功能的性能比Volcano模型的性能高出了一个数量级,主要的原因有三点:
1. 避免了虚函数调用(Virtual Function Dispatch),Volcano Iterator Model至少需要调用一次next()获取下一个Operator,在操作系统层面会被编译为Virtual Function Dispatch,会执行多个CPU指令,并且速度慢。而直接编写的Java代码中没有任何函数调用逻辑。
2. 使用CPU寄存器存取中间数据 。 Volcano Iterator Model将数据交给下一个Operator时,都需要将数据写入内存缓冲,但是在手写代码中,JVM JIT编译器会将这些数据写入CPU寄存器,CPU直接从寄存器中读写数据比在内存缓冲中读写数据的性能要高一个数量级。
3.编译器Loop Unrolling。手写代码针对某特定功能使用简单循环,而现代的编译器可以自动的对简单循环进行Unrolling,生成单指令多数据流(SIMD),在每次CPU指令执行时处理多条数据。而这些优化特点无法在Volcano Iterator Model复杂的函数调用场景中施展。
二、Whole-stage code generation
1. Spark性能调优思路
在以上论述的技术背景下,如果要对Spark进行性能优化,应该避免使用Volcano模型,在运行时动态生成代码。由此,Spark2.x版本中,基于Tungsten引擎的Whole-stage code generation 技术应运而生。SQL语句编译后的Operator-Tree中,每个Operator不再执行逻辑,而是通过全流式代码生成技术在运行时动态生成代码,并尽量将所有的操作打包到一个函数中。如果是简单查询,Spark会尽量生成一个Stage,如果是复杂的查询,就可能会生成多个Stage。
2. Spark2.x的SQL执行计划
Spark提供了一个explain( )方法来查询SQL的执行计划。
例子:
准备工作:通过saprk读取HDFS上的员工表信息(emp.csv),执行操作如下:
scala> case class Emp(eno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
defined class Emp scala> val lines = sc.textFile("hdfs://bigdata11:9000/input/emp.csv").map(_.split(","))
lines: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[9] at map at <console>:24 scala> val allEmp = lines.map(x => Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt))
allEmp: org.apache.spark.rdd.RDD[Emp] = MapPartitionsRDD[10] at map at <console>:28 scala> val empDF = allEmp.toDF
empDF: org.apache.spark.sql.DataFrame = [eno: int, ename: string ... 6 more fields]
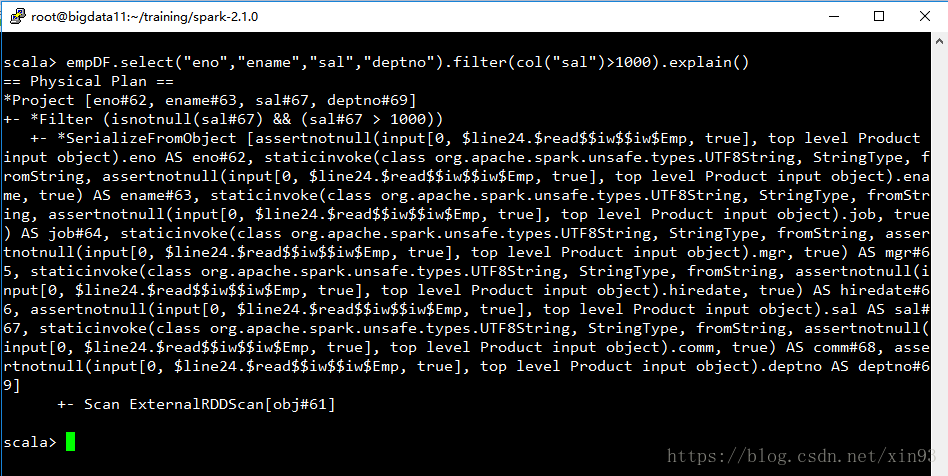
查看执行计划:通过explain()方法查看执行计划。前面带*号的步骤就是通过whole-stage code generation生成的。
三、总结
从以上分析可以看出Spark2.x引入的whole-stage code generation技术,使Spark2.x的性能比Spark1.x的性能有所提高。但并不是所有的操作都能够大幅提升性能,whole-stage code generation技术是从CPU密集操作的方面进行性能调优,对IO密集操作的层面是无法提高效率的,比如Shuffle中产生的读写磁盘操作是无法通过该技术提升性能的,Spark未来版本的更新还需要从IO密集操作层面进行性能调优。
【Spark】Spark性能优化之Whole-stage code generation的更多相关文章
- SparkSQL的一些用法建议和Spark的性能优化
1.写在前面 Spark是专为大规模数据处理而设计的快速通用的计算引擎,在计算能力上优于MapReduce,被誉为第二代大数据计算框架引擎.Spark采用的是内存计算方式.Spark的四大核心是Spa ...
- [看图说话] 基于Spark UI性能优化与调试——初级篇
Spark有几种部署的模式,单机版.集群版等等,平时单机版在数据量不大的时候可以跟传统的java程序一样进行断电调试.但是在集群上调试就比较麻烦了...远程断点不太方便,只能通过Log的形式,进行分析 ...
- Spark实践 -- 性能优化基础
性能调优相关的原理讲解.经验总结: 掌握一整套Spark企业级性能调优解决方案:而不只是简单的一些性能调优技巧. 针对写好的spark作业,实施一整套数据倾斜解决方案:实际经验中积累的数据倾斜现象的表 ...
- spark mongo 性能优化
性能优化事项 http://www.mongoing.com/wp-content/uploads/2016/08/MDBSH2016/TJ_MongoDB+Spark.pdf MongoDB + S ...
- Spark SQL 性能优化再进一步:CBO 基于代价的优化
摘要: 本文将介绍 CBO,它充分考虑了数据本身的特点(如大小.分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划,即 SparkPlan. Spark ...
- Spark Streaming性能优化: 如何在生产环境下应对流数据峰值巨变
1.为什么引入Backpressure 默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > ...
- Spark Streaming性能优化系列-怎样获得和持续使用足够的集群计算资源?
一:数据峰值的巨大影响 1. 数据确实不稳定,比如晚上的时候訪问流量特别大 2. 在处理的时候比如GC的时候耽误时间会产生delay延迟 二:Backpressure:数据的反压机制 基本思想:依据上 ...
- 《Spark大数据处理:技术、应用与性能优化 》
基本信息 作者: 高彦杰 丛书名:大数据技术丛书 出版社:机械工业出版社 ISBN:9787111483861 上架时间:2014-11-5 出版日期:2014 年11月 开本:16开 页码:255 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】 下载
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
随机推荐
- Winform访问本地SQLServer数据库文件
Winform访问本地SQLServer数据库文件 1.项目中添加config配置,如下: <configuration> <connectionStrings> <ad ...
- You must not call setTag() on a view Glide is targeting when use Glide
以下代码是一个显示图片的RecyclerView 的Adapter用到的,当点击图片,跳到另一个Activity显示大图.RecyclerView 与ListView不同 然而没有setOnClick ...
- Word 2010 去除文字或段落背景色
在复制网页文本到Word时,有时会带有网页上的背景颜色.下面采用两种方法解决这种问题,可根据不同需要进行选择. 方法一:清除样式 此种方法适用于只需要网页文字,而不想要网页任何样式信息,如字体大小,段 ...
- sqlserver2008 insert语句性能
在sqlserver2008中“新建查询”,执行批量添加语句的执行时间: declare @i int ) begin INSERT INTO [xxx].[dbo].[北京万奇亚讯科技_QueryL ...
- 从0开始学CentOS7(1)
首先,先来几句简介吧.. java开发一枚,总觉得自己的技术提升缓慢... 最近看到同事有在论坛发发自己的心得什么的...我脑中晃出的灵光就是:好记性不如烂笔头,试试吧~ 好了,正式开始了..cent ...
- MongoDB插入文档
db.collection.insertOne() 插入单个文档.db.collection.insertMany() 插入多个文档.db.collection.insert() 插入单/多个文档. ...
- IntelliJ IDEA 2017.3-2018.1 全系列汉化包
JetBrains 系列软件汉化包 关键字: Android Studio 3.0-3.1 汉化包 GoLand 2017.3.2-2018.1 汉化包 IntelliJ IDEA 2017.3-20 ...
- MATLAB入门学习(七)
开始,线性代数和微积分了,不怕.不怕. 背命令就行了... 线性代数 解线性方程组: Ax=b A是系数矩阵,x未知数,b是列向量 如果有唯一解,直接x=b\A 第二 B=null(A,'r')求Ax ...
- ctrl + alt + o 快速删除掉没有使用的 import
ctrl + alt + o 优化导入,可以快速删除掉没有使用的 import
- Handler的简单使用介绍
Handler在android程序开发中使用的非常频繁.我们知道android是不允许在子线程中更新UI的,这就需要借助Handler来实现,那么你是否想过为什么一定要这个这样子做呢?而且Handle ...