elasticsearch实现基于拼音搜索
1、背景
一般情况下,有些搜索需求是需要根据拼音和中文来搜索的,那么在elasticsearch中是如何来实现基于拼音来搜索的呢?可以通过elasticsearch-analysis-pinyin分析器来实现。
2、安装拼音分词器
# 进入 es 的插件目录
cd /usr/local/es/elasticsearch-8.4.3/plugins
# 下载
wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v8.4.3/elasticsearch-analysis-pinyin-8.4.3.zip
# 新建目录
mkdir analysis-pinyin
# 解压
mv elasticsearch-analysis-pinyin-8.4.3.zip analysis-pinyin && cd analysis-pinyin && unzip elasticsearch-analysis-pinyin-8.4.3.zip && rm -rvf elasticsearch-analysis-pinyin-8.4.3.zip
cd ../ && chown -R es:es analysis-pinyin
# 启动es
/usr/local/es/elasticsearch-8.4.3/bin/elasticsearch -d
3、拼音分词器提供的功能
拼音分词器提供如下功能

每个选项的含义 可以通过 文档中的例子来看懂。
4、简单测试一下拼音分词器
4.1 dsl
GET _analyze
{
"text": ["我是中国人"],
"analyzer": "pinyin"
}
"analyzer": "pinyin" 此处的pinyin是拼音分词器自带的。
4.2 运行结果

从图片上,实现了拼音分词,但是这个不一定满足我们的需求,比如没有中文了,单个的拼音(比如:wo)是没有什么用的,需要对拼音分词器进行定制化。
5、es中分词器的组成
在elasticsearch中分词器analyzer由如下三个部分组成:
character filters:用于在tokenizer之前对文本进行处理。比如:删除字符,替换字符等。tokenizer:将文本按照一定的规则分成独立的token。即实现分词功能。tokenizer filter:将tokenizer输出的词条做进一步的处理。比如:同义词处理,大小写转换、移除停用词,拼音处理等。
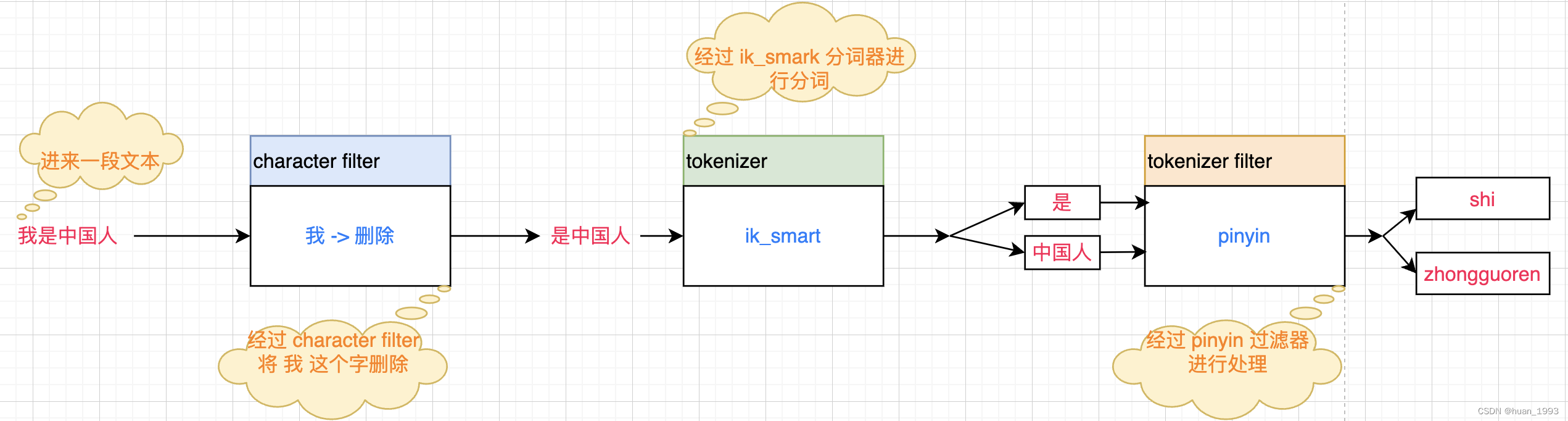
6、自定义一个分词器实现拼音和中文的搜索
需求: 自定义一个分词器,即可以实现拼音搜索,也可以实现中文搜索。
1、创建mapping
PUT /test_pinyin
{
"settings": {
// 分析阶段的设置
"analysis": {
// 分析器设置
"analyzer": {
// 自定义分析器,在tokenizer阶段使用ik_max_word,在filter上使用py
"custom_analyzer": {
"tokenizer": "ik_max_word",
"filter": "custom_pinyin"
}
},
// 由于不满足pinyin分词器的默认设置,所以我们基于pinyin
// 自定义了一个filter,叫py,其中修改了一些设置
// 这些设置可以在pinyin分词器官网找到
"filter": {
"custom_pinyin": {
"type": "pinyin",
// 不会这样分:刘德华 > [liu, de, hua]
"keep_full_pinyin": false,
// 这样分:刘德华 > [liudehua]
"keep_joined_full_pinyin": true,
// 保留原始token(即中文)
"keep_original": true,
// 设置first_letter结果的最大长度,默认值:16
"limit_first_letter_length": 16,
// 当启用此选项时,将删除重复项以保存索引,例如:de的> de,默认值:false,注意:位置相关查询可能受影响
"remove_duplicated_term": true,
// 如果非汉语字母是拼音,则将其拆分为单独的拼音术语,默认值:true,如:liudehuaalibaba13zhuanghan- > liu,de,hua,a,li,ba,ba,13,zhuang,han,注意:keep_none_chinese和keep_none_chinese_together应首先启用
"none_chinese_pinyin_tokenize": false
}
}
}
},
// 定义mapping
"mappings": {
"properties": {
"name": {
"type": "text",
// 创建倒排索引时使用的分词器
"analyzer": "custom_analyzer",
// 搜索时使用的分词器,搜索时不使用custom_analyzer是为了防止 词语的拼音一样,但是中文含义不一样,导致搜索错误。 比如: 科技 和 客机,拼音一样,但是含义不一样
"search_analyzer": "ik_smart"
}
}
}
}
注意:
可以看到 我们的 name字段 使用的分词器是 custom_analyzer,这个是我们在上一步定义的。但是搜索的时候使用的是 ik_smart,这个为甚么会这样呢?
假设我们存在如下2个文本 科技强国和 这是一架客机, 那么科技和客机的拼音是不是就是一样的。 这个时候如果搜索时使用的分词器也是custom_analyzer那么,搜索科技的时候客机也会搜索出来,这样是不对的。因此在搜索的时候中文就以中文搜,拼音就以拼音搜。
{
"name": {
"type": "text",
"analyzer": "custom_analyzer",
"search_analyzer": "ik_smart"
}
}
当 analyzer和search_analyzer的值都是custom_analyzer,搜索时也会通过拼音搜索,这样的结果可能就不是我们想要的。
2、插入数据
PUT /test_pinyin/_bulk
{"index":{"_id":1}}
{"name": "科技强国"}
{"index":{"_id":2}}
{"name": "这是一架客机"}
{"index":{"_id":3}}
3、搜索数据
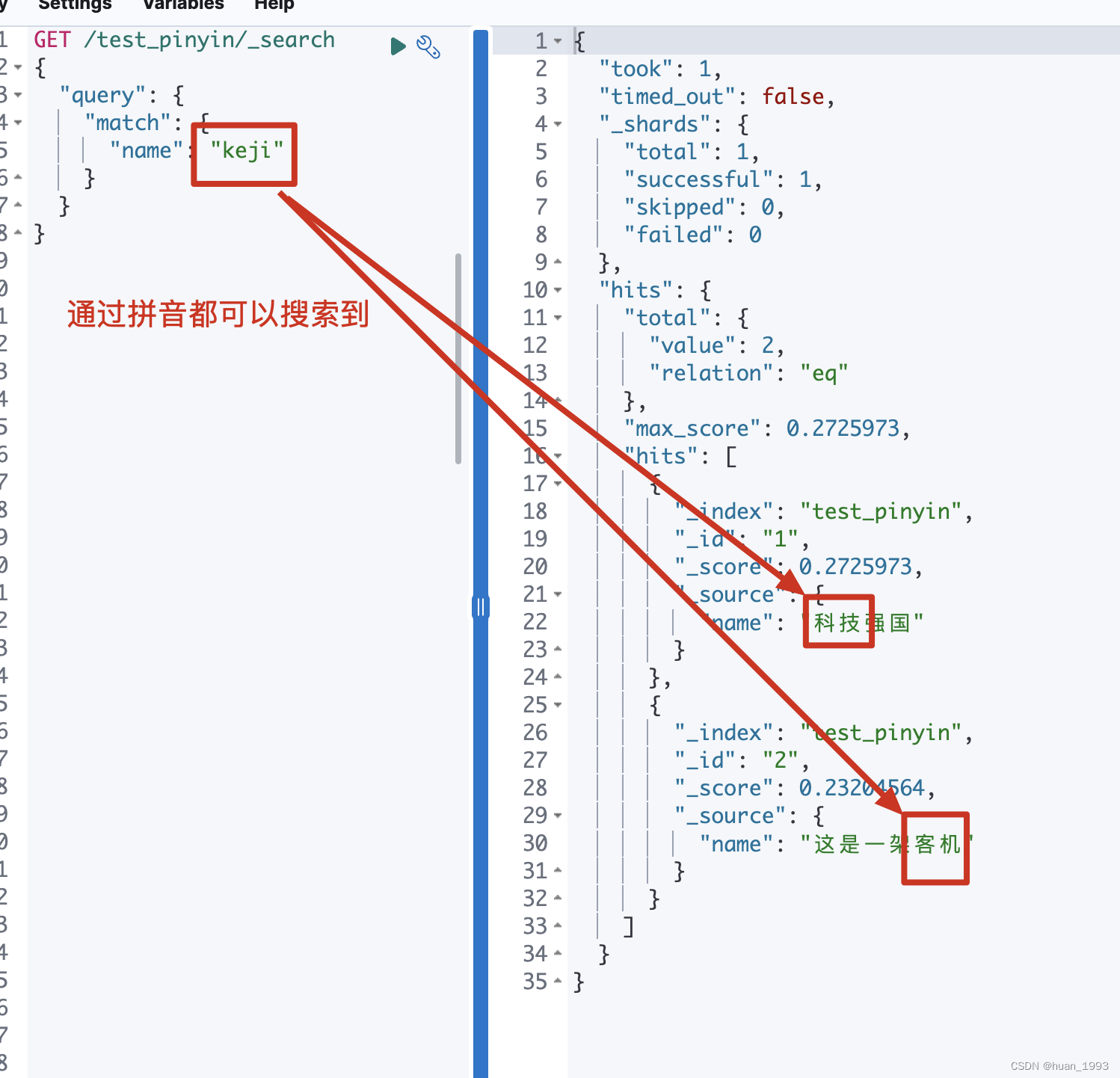
7、参考文档
1、https://github.com/medcl/elasticsearch-analysis-pinyin/tree/master
elasticsearch实现基于拼音搜索的更多相关文章
- php根据汉字获取拼音(php基于拼音搜索实现原理)
php根据汉字获取拼音(php基于拼音搜索实现原理) 代码一:获取字符串汉字首字母,兼容GBK和UTF-8 <?php function getfirstchar($s0){ //获取单个汉 ...
- elasticsearch实战 中文+拼音搜索
需求 雪花啤酒 需要搜索雪花.啤酒 .雪花啤酒.xh.pj.xh啤酒.雪花pj ik导入 参考https://www.cnblogs.com/LQBlog/p/10443862.html,不需要修改 ...
- elasticsearch之拼音搜索
拼音搜索在中文搜索环境中是经常使用的一种功能,用户只需要输入关键词的拼音全拼或者拼音首字母,搜索引擎就可以搜索出相关结果.在国内,中文输入法基本上都是基于汉语拼音的,这种在符合用户输入习惯的条件下缩短 ...
- Elasticsearch实现类似 like '?%' 搜索
在做搜索的时候,下拉联想词的搜索肯定是最常见的一个场景,用户在输入的时候,要自动补全词干,说得简单点,就是以...开头搜索,如果是数据库,一句SQL就很容易实现,但在elasticsearch如何实现 ...
- 转:在ElasticSearch之下(图解搜索的故事)
ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事) 摘要 先自上而下,后自底向上的介绍ElasticSearch的底层工作原理,试图回答以下问题: 为什么我 ...
- Elasticsearch java api 基本搜索部分详解
文档是结合几个博客整理出来的,内容大部分为转载内容.在使用过程中,对一些疑问点进行了整理与解析. Elasticsearch java api 基本搜索部分详解 ElasticSearch 常用的查询 ...
- ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事)
ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事) 摘要 先自上而下,后自底向上的介绍ElasticSearch的底层工作原理,试图回答以下问题: 为什么我 ...
- 从零搭建 ES 搜索服务(四)拼音搜索
一.前言 上篇介绍了 ES 的同义词搜索,使我们的搜索更强大了,然而这还远远不够,在实际使用中还可能希望搜索「fanqie」能将包含「番茄」的结果也罗列出来,这就涉及到拼音搜索了,本篇将介绍如何具体实 ...
- ElasticSearch 2 (18) - 深入搜索系列之控制相关度
ElasticSearch 2 (18) - 深入搜索系列之控制相关度 摘要 处理结构化数据(比如:时间.数字.字符串.枚举)的数据库只需要检查一个文档(或行,在关系数据库)是否与查询匹配. 布尔是/ ...
- ElasticSearch 2 (17) - 深入搜索系列之部分匹配
ElasticSearch 2 (17) - 深入搜索系列之部分匹配 摘要 到目前为止,我们介绍的所有查询都是基于完整术语的,为了匹配,最小的单元为单个术语,我们只能查找反向索引中存在的术语. 但是, ...
随机推荐
- JVM中的方法区
JVM中的方法区 方法区存储什么? 用于存储已被虚拟机加载的类型信息.常量.静态变量.即时编译器编译后的代码缓存 1.类型信息 对每个加载的类型(类class.接口interface.枚举.注解)jv ...
- 微服务架构学习与思考(11):开源 API 网关02-以 Java 为基础的 API 网关详细介绍
微服务架构学习与思考(11):开源 API 网关02-以 Java 为基础的 API 网关详细介绍 上一篇关于网关的文章: 微服务架构学习与思考(10):微服务网关和开源 API 网关01-以 Ngi ...
- CSS 渐变锯齿消失术
在 CSS 中,渐变(Gradient)可谓是最为强大的一个属性之一. 但是,经常有同学在使用渐变的过程中会遇到渐变图形产生的锯齿问题. 何为渐变锯齿? 那么,什么是渐变图形产生的锯齿呢? 简单的一个 ...
- .Net Core中获取appsettings.json中的节点数据
获取ConnectionStrings节点数据 //appsettings.json { "ConnectionStrings": { //DEV "DbConn&quo ...
- 九、docker swarm主机编排
一. 什么是Docker Swarm Swarm 是 Docker 公司推出的用来管理 docker 集群的平台,几乎全部用GO语言来完成的开发的,代码开源在https://github.com/do ...
- iptables和firewalld基础
1.四表五链概念: filter表 过滤数据包 Nat表 用于网络地址转换(IP.端口) Mangle表 修改数据包的服务类型.TTL.并且可以配置路由实现QOS Raw表 决定数据包是否被状态跟踪机 ...
- 51单片机-独立按键控制led矩阵的左移和右移
51单片机学习 独立按键 控制led灯光矩阵的左移和右移 开发板采用的是普中的A2学习开发板,具体的代码如下: typedef unsigned int u16; void delay(u16 tim ...
- Java自定义排序:继承Comparable接口,重写compareTo方法(排序规则)
代码: 1 import java.util.*; 2 3 /** 4 * 学习自定义排序:继承Comparable接口,重写compareTo方法(排序规则). 5 * TreeMap容器的Key是 ...
- @Retryable注解的使用
@Retryable 前言 在实际工作中,重处理是一个非常常见的场景,比如: 发送消息失败. 调用远程服务失败. 争抢锁失败. 这些错误可能是因为网络波动造成的,等待过后重处理就能成功.通常来说,会用 ...
- vcenter异常死机无法重启
esxi主机异常掉电重启后,vcenter启动失败 查阅相关资料发现,一般是由于时间同步异常造成, 推荐方法是先确认bios硬件时间已同步,再删除旧的本地服务json文件,重启vcenter的服务. ...