elasticsearch实现基于拼音搜索
1、背景
一般情况下,有些搜索需求是需要根据拼音和中文来搜索的,那么在elasticsearch中是如何来实现基于拼音来搜索的呢?可以通过elasticsearch-analysis-pinyin分析器来实现。
2、安装拼音分词器
# 进入 es 的插件目录
cd /usr/local/es/elasticsearch-8.4.3/plugins
# 下载
wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v8.4.3/elasticsearch-analysis-pinyin-8.4.3.zip
# 新建目录
mkdir analysis-pinyin
# 解压
mv elasticsearch-analysis-pinyin-8.4.3.zip analysis-pinyin && cd analysis-pinyin && unzip elasticsearch-analysis-pinyin-8.4.3.zip && rm -rvf elasticsearch-analysis-pinyin-8.4.3.zip
cd ../ && chown -R es:es analysis-pinyin
# 启动es
/usr/local/es/elasticsearch-8.4.3/bin/elasticsearch -d
3、拼音分词器提供的功能
拼音分词器提供如下功能

每个选项的含义 可以通过 文档中的例子来看懂。
4、简单测试一下拼音分词器
4.1 dsl
GET _analyze
{
"text": ["我是中国人"],
"analyzer": "pinyin"
}
"analyzer": "pinyin" 此处的pinyin是拼音分词器自带的。
4.2 运行结果

从图片上,实现了拼音分词,但是这个不一定满足我们的需求,比如没有中文了,单个的拼音(比如:wo)是没有什么用的,需要对拼音分词器进行定制化。
5、es中分词器的组成
在elasticsearch中分词器analyzer由如下三个部分组成:
character filters:用于在tokenizer之前对文本进行处理。比如:删除字符,替换字符等。tokenizer:将文本按照一定的规则分成独立的token。即实现分词功能。tokenizer filter:将tokenizer输出的词条做进一步的处理。比如:同义词处理,大小写转换、移除停用词,拼音处理等。
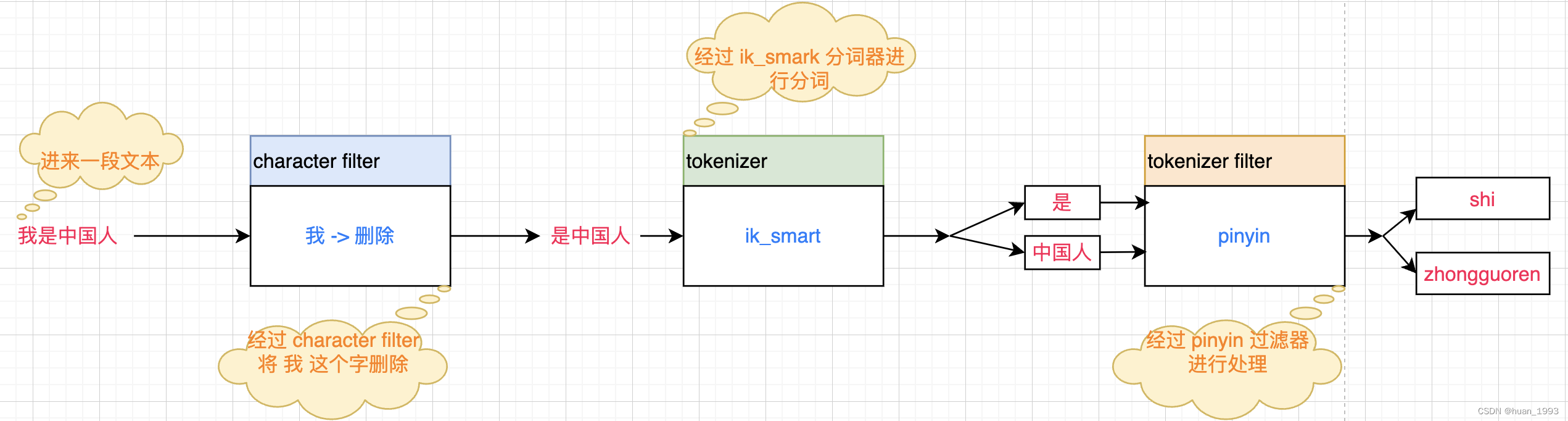
6、自定义一个分词器实现拼音和中文的搜索
需求: 自定义一个分词器,即可以实现拼音搜索,也可以实现中文搜索。
1、创建mapping
PUT /test_pinyin
{
"settings": {
// 分析阶段的设置
"analysis": {
// 分析器设置
"analyzer": {
// 自定义分析器,在tokenizer阶段使用ik_max_word,在filter上使用py
"custom_analyzer": {
"tokenizer": "ik_max_word",
"filter": "custom_pinyin"
}
},
// 由于不满足pinyin分词器的默认设置,所以我们基于pinyin
// 自定义了一个filter,叫py,其中修改了一些设置
// 这些设置可以在pinyin分词器官网找到
"filter": {
"custom_pinyin": {
"type": "pinyin",
// 不会这样分:刘德华 > [liu, de, hua]
"keep_full_pinyin": false,
// 这样分:刘德华 > [liudehua]
"keep_joined_full_pinyin": true,
// 保留原始token(即中文)
"keep_original": true,
// 设置first_letter结果的最大长度,默认值:16
"limit_first_letter_length": 16,
// 当启用此选项时,将删除重复项以保存索引,例如:de的> de,默认值:false,注意:位置相关查询可能受影响
"remove_duplicated_term": true,
// 如果非汉语字母是拼音,则将其拆分为单独的拼音术语,默认值:true,如:liudehuaalibaba13zhuanghan- > liu,de,hua,a,li,ba,ba,13,zhuang,han,注意:keep_none_chinese和keep_none_chinese_together应首先启用
"none_chinese_pinyin_tokenize": false
}
}
}
},
// 定义mapping
"mappings": {
"properties": {
"name": {
"type": "text",
// 创建倒排索引时使用的分词器
"analyzer": "custom_analyzer",
// 搜索时使用的分词器,搜索时不使用custom_analyzer是为了防止 词语的拼音一样,但是中文含义不一样,导致搜索错误。 比如: 科技 和 客机,拼音一样,但是含义不一样
"search_analyzer": "ik_smart"
}
}
}
}
注意:
可以看到 我们的 name字段 使用的分词器是 custom_analyzer,这个是我们在上一步定义的。但是搜索的时候使用的是 ik_smart,这个为甚么会这样呢?
假设我们存在如下2个文本 科技强国和 这是一架客机, 那么科技和客机的拼音是不是就是一样的。 这个时候如果搜索时使用的分词器也是custom_analyzer那么,搜索科技的时候客机也会搜索出来,这样是不对的。因此在搜索的时候中文就以中文搜,拼音就以拼音搜。
{
"name": {
"type": "text",
"analyzer": "custom_analyzer",
"search_analyzer": "ik_smart"
}
}
当 analyzer和search_analyzer的值都是custom_analyzer,搜索时也会通过拼音搜索,这样的结果可能就不是我们想要的。
2、插入数据
PUT /test_pinyin/_bulk
{"index":{"_id":1}}
{"name": "科技强国"}
{"index":{"_id":2}}
{"name": "这是一架客机"}
{"index":{"_id":3}}
3、搜索数据
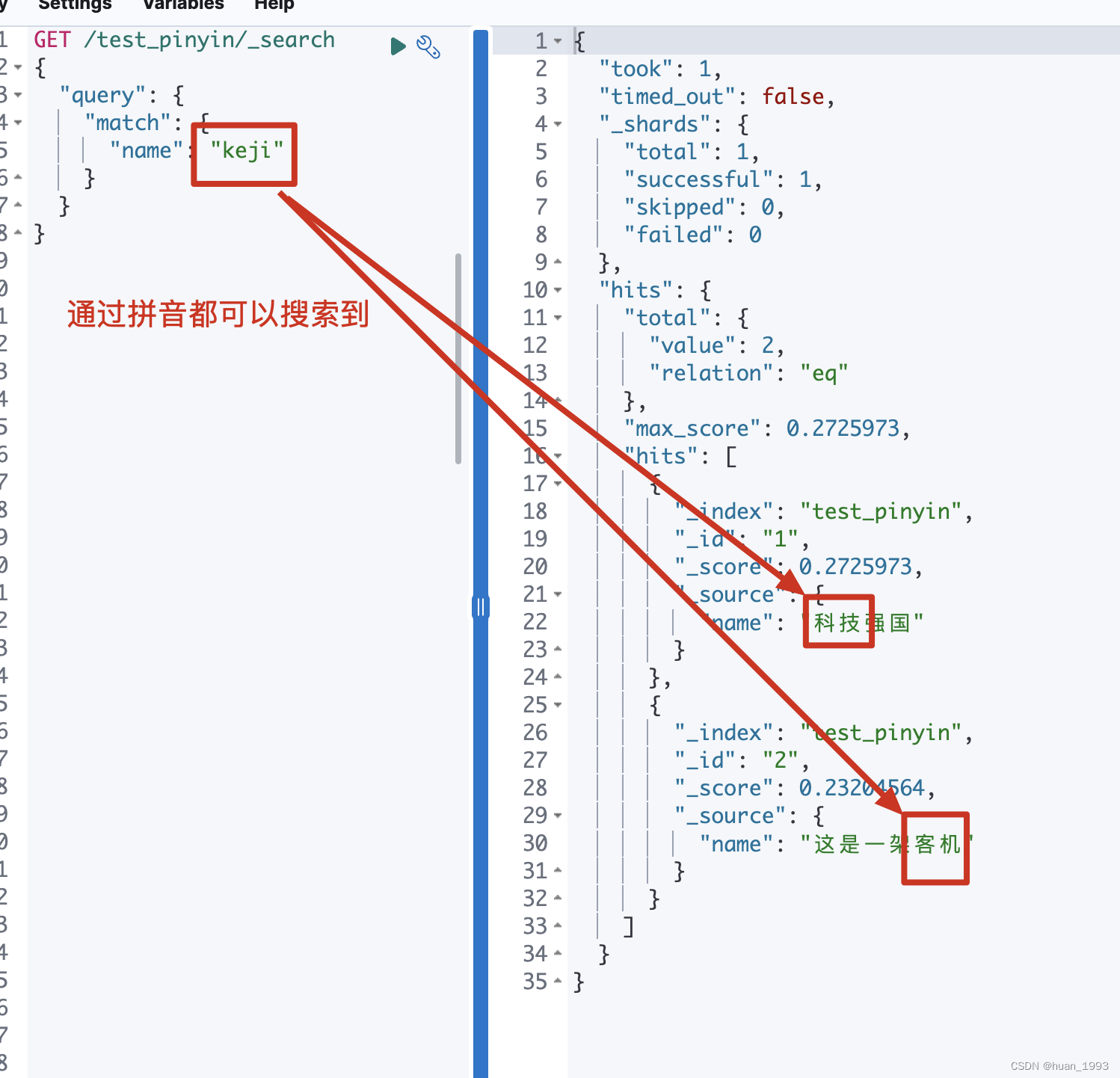
7、参考文档
1、https://github.com/medcl/elasticsearch-analysis-pinyin/tree/master
elasticsearch实现基于拼音搜索的更多相关文章
- php根据汉字获取拼音(php基于拼音搜索实现原理)
php根据汉字获取拼音(php基于拼音搜索实现原理) 代码一:获取字符串汉字首字母,兼容GBK和UTF-8 <?php function getfirstchar($s0){ //获取单个汉 ...
- elasticsearch实战 中文+拼音搜索
需求 雪花啤酒 需要搜索雪花.啤酒 .雪花啤酒.xh.pj.xh啤酒.雪花pj ik导入 参考https://www.cnblogs.com/LQBlog/p/10443862.html,不需要修改 ...
- elasticsearch之拼音搜索
拼音搜索在中文搜索环境中是经常使用的一种功能,用户只需要输入关键词的拼音全拼或者拼音首字母,搜索引擎就可以搜索出相关结果.在国内,中文输入法基本上都是基于汉语拼音的,这种在符合用户输入习惯的条件下缩短 ...
- Elasticsearch实现类似 like '?%' 搜索
在做搜索的时候,下拉联想词的搜索肯定是最常见的一个场景,用户在输入的时候,要自动补全词干,说得简单点,就是以...开头搜索,如果是数据库,一句SQL就很容易实现,但在elasticsearch如何实现 ...
- 转:在ElasticSearch之下(图解搜索的故事)
ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事) 摘要 先自上而下,后自底向上的介绍ElasticSearch的底层工作原理,试图回答以下问题: 为什么我 ...
- Elasticsearch java api 基本搜索部分详解
文档是结合几个博客整理出来的,内容大部分为转载内容.在使用过程中,对一些疑问点进行了整理与解析. Elasticsearch java api 基本搜索部分详解 ElasticSearch 常用的查询 ...
- ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事)
ElasticSearch 2 (9) - 在ElasticSearch之下(图解搜索的故事) 摘要 先自上而下,后自底向上的介绍ElasticSearch的底层工作原理,试图回答以下问题: 为什么我 ...
- 从零搭建 ES 搜索服务(四)拼音搜索
一.前言 上篇介绍了 ES 的同义词搜索,使我们的搜索更强大了,然而这还远远不够,在实际使用中还可能希望搜索「fanqie」能将包含「番茄」的结果也罗列出来,这就涉及到拼音搜索了,本篇将介绍如何具体实 ...
- ElasticSearch 2 (18) - 深入搜索系列之控制相关度
ElasticSearch 2 (18) - 深入搜索系列之控制相关度 摘要 处理结构化数据(比如:时间.数字.字符串.枚举)的数据库只需要检查一个文档(或行,在关系数据库)是否与查询匹配. 布尔是/ ...
- ElasticSearch 2 (17) - 深入搜索系列之部分匹配
ElasticSearch 2 (17) - 深入搜索系列之部分匹配 摘要 到目前为止,我们介绍的所有查询都是基于完整术语的,为了匹配,最小的单元为单个术语,我们只能查找反向索引中存在的术语. 但是, ...
随机推荐
- HTML+CSS基础知识(5)相对定位、绝对定位、固定定位
文章目录 1.相对定位 1.1 代码 1.2 测试结果 2.绝对定位 2.1 代码 2.2 测试 3.固定定位 3.1 代码 3.2 测试结果 1.相对定位 1.1 代码 <!DOCTYPE h ...
- 齐博X1模板页面之间的继承关系
本节说明下模板页面间的继承 我们在前面建立了一个公共布局模板,并且利用{block name=xxx}...{/block}分割了三个部分区块 本节我们来看下模板之前的继承如何实现,首先我们建立一个i ...
- 5.@pytest.mark.parametrize()数据驱动
简介: pytest.mark.parametrize 是 pytest 的内置装饰器,它允许你在 function 或者 class 上定义多组参数和 fixture 来实现数据驱动. @pytes ...
- windows下cmd补全键注册表修改
1:使用win+r打开 运行 控制台 2:输入 regedit 打开注册表 3:进入HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Command Processor\ ...
- 分享几个关于Camera的坑
最近忙于开发一款基于Camera2 API的相机应用,部分功能涉及到广角镜头,因此踩了不少坑,在此与大家分享下以作记录交流... 经过查阅资料发现在安卓上所谓的广角镜头切换其实是用一个逻辑摄像头包含多 ...
- WPF 鼠标移动到图片变大,移开还原,单击触发事件效果
<Grid> <Canvas x:Name="LayoutRoot"> <Image Cursor=" ...
- 【神经网络】丢弃法(dropout)
丢弃法是一种降低过拟合的方法,具体过程是在神经网络传播的过程中,随机"沉默"一些节点.这个行为让模型过度贴合训练集的难度更高. 添加丢弃层后,训练速度明显上升,在同样的轮数下测试集 ...
- 关系抽取--Relation Extraction: Perspective from Convolutional Neural Networks
一种使用CNN来提取特征的模型,通过CNN的filter的大小来获得不同的n-gram的信息,模型的结构如下所示: 输入 输入使用word2vec的50维词向量,加上 position embeddi ...
- 类的编写模板之简单Java类
简单Java类是初学java时的一个重要的类模型,一般由属性和getter.setter方法组成,该类不涉及复杂的逻辑运算,仅仅是作为数据的储存,同时该类一般都有明确的实物类型.如:定义一个雇员的类, ...
- 安装nvm 和 yarn
安装nvm curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash 执行上面的命令 如果出现问题 ...