python进阶(28)import导入机制原理
前言
在Python中,一个.py文件代表一个Module。在Module中可以是任何的符合Python文件格式的Python脚本。了解Module导入机制大有用处。
1. Module组成
一个.py文件就是一个module。Module中包括attribute, function等。 这里说的attribute其实是module的global variable。
我们创建1个test1.py文件,代码如下
# 定义1个全局变量a
a = 1
# 声明一个全局变量moduleName
global moduleName
# 定义一个函数printModuleName
def printModuleName():
print(a + 2)
print(__name__)
print(moduleName)
print(dir())
这里我们定义了3个全局变量a、moduleName、printModuleName,除了我们自己定义的以外还有module内置的全局变量
1.1 Module 内置全局变量
上面我们说到了,每一个模块都有内置的全局变量,我们可以使用dir()函数,用于查看模块内容,例如上面的例子中,使用dir()查看结果如下:
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'moduleName', 'printModuleName']
其中a, moduleName, printModuleName 是由用户自定义的。其他的全是内置的。下面介绍几个常用的内置全局变量
1.1.1 __name__
指的是当前模块的名称,比如上面的test1.py,模块的名称默认就是test1,如果一个module是程序的入口,那么__name__=__'main'__,这也是我们经常看到用到的
1.1.2 __builtins__
它就是内置模块builtins的引用。可以通过如下代码测试:
import builtins
print(builtins == __builtins__)
打印结果为True,在Python代码里,不需要我们导入就能直接使用的函数、类等,都是在这个内置模块里的。例如:range、dir
1.1.3 __doc__
它就是module的文档说明,具体是文件头之后、代码(包含import)之前的第一个多行注释,测试如下
点击查看代码
"""
模块导入机制测试
"""
import builtins
# 定义1个全局变量a
a = 1
# 声明一个全局变量moduleName
global moduleName
# 定义一个函数printModuleName
def printModuleName():
print(a + 2)
print(__name__)
print(moduleName)
print(__doc__)
最后打印结果为
模块导入机制测试
当然如果你想查看某个方法的说明,也可以这么使用
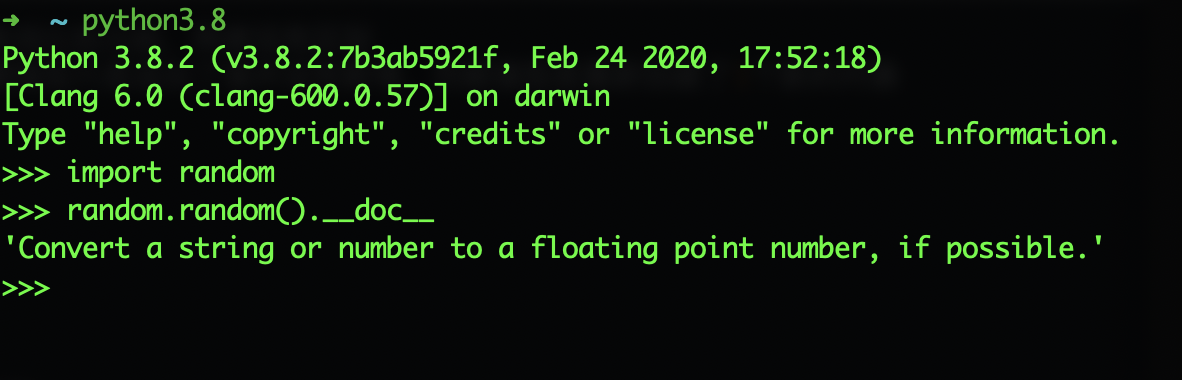
1.1.4 __file__
当前module所在的文件的绝对路径
1.1.5 __package__
当前module所在的包名。如果没有,为None。
2. 包package
为避免模块名冲突,Python引入了按目录组织模块的方法,称之为包(package)。包是含有Python模块的文件夹。
当一个文件夹下有init.py时,意为该文件夹是一个包(package),其下的多个模块(module)构成一个整体,而这些模块(module)都可通过同一个包(package)导入其他代码中。
其中init.py文件用于组织包(package),方便管理各个模块之间的引用、控制着包的导入行为。
该文件可以什么内容都不写,即为空文件,存在即可,相当于一个标记。
但若想使用from pacakge_1 import *这种形式的写法,需在init.py中加上:__all__ = ['file_a', 'file_b'] ,并且package_1下有file_a.py和file_b.py,在导入时init.py文件将被执行。
但不建议在init.py中写模块,以保证该文件简单。不过可在init.py导入我们需要的模块,以便避免一个个导入、方便使用。
其中,__all__是一个重要的变量,用来指定此包(package)被import *时,哪些模块(module)会被import进【当前作用域中】。不在__all__列表中的模块不会被其他程序引用。可以重写__all__,如__all__= ['当前所属包模块1名字', '模块1名字'],如果写了这个,则会按列表中的模块名进行导入
在模糊导入时,形如from package import *,*是由__all__定义的。
当我们在导入一个包(package)时(会先加载__init__.py定义的引入模块,然后再运行其他代码),实际上是导入的它的__init__.py文件(导入时,该文件自动运行,助我们一下导入该包中的多个模块)。我们可以在 init.py中再导入其他的包(package)或模块或自定义类。
2.1 实战案例
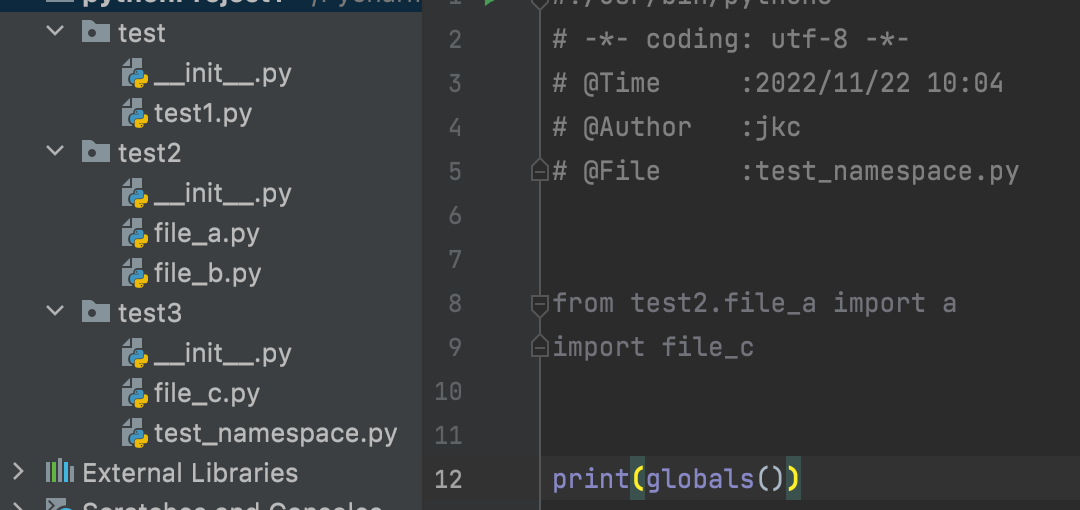
首先我们创建3个包,分别是test、test2、test3
test包下创建test1.py用来执行测试
test2包下创建file_a.py、file_b.py,用来测试包的导入
test3包下创建file_c.py,辅助测试
具体结构如下:

核心代码在test2/__init__.py中如下
__all__ = ['file_a', 'file_b', 'file_c', 'test_d']
from test3 import file_c
def test_d():
return "test_d"
解释下,当我们在test/test1.py中写了from test2 import *这句代码,程序不是直接导入test2下的所有模块,而是导入__init__.py文件并自动运行,由于我们写了__all__ = ['file_a', 'file_b', 'file_c', 'test_d'],file_a和file_b是当下包中的模块,file_c是我们从test3包中导入的,test_d是__init__.py下我们定义的函数。
所以from test2 import *就是把__all__中指定的模块和函数导入进来了,接着我们查看test1.py下的代码
from test2 import *
print(file_a.a())
print(file_b.b())
print(file_c.c())
print(test_d())
如果打印有结果,则证明了导入成功,并且导入的是__all__下的模块和函数
3.sys.modules、命名空间
3.1 sys.modules
sys.modules是一个将模块名称映射到已加载的模块的字典。可用来强制重新加载modules。Python一启动,它将被加载在内存中。
当我们导入新modules,sys.modules将自动记录下该module;当第二次再导入该module时,Python将直接到字典中查找,加快运行速度。
它是1个字典,故拥有字典的一切方法,如sys.modules.keys()、sys.modules.values()、sys.modules['os']。但请不要轻易替换字典、或从字典中删除某元素,将可能导致Python运行失败。
3.2 命名空间
命名空间就像一个dict,key是变量名字,value是变量的值。
- 每个函数function都有自己的命名空间,称local namespace,记录函数的变量。
- 每个模块module都有自己的命名空间,称global namespace,记录模块的变量,包括functions、classes、导入的modules、module级别的变量和常量。
- build-in命名空间,它包含build-in function和exceptions,可被任意模块访问。
假设你要访问某段Python代码中的变量x时,Python会在所有的命名空间中查找该变量,顺序是:
- local namespace 即当前函数或类方法。若找到,则停止搜索;
- global namespace 即当前模块。若找到,则停止搜索;
- build-in namespace Python会假设变量x是build-in的内置函数或变量。若变量x不是build-in的内置函数或变量,Python将报错NameError。
- 对于闭包,若在local namespace找不到该变量,则下一个查找目标是父函数的local namespace。
我们可以看一个小例子
# test_namespace.py
def func(a=1):
b = 2
print(locals()) # 打印当前函数的局部命名空间
'''
locs = locals() # 只读,不可写,会报错
locs['c'] = 3
print(c)
'''
return a + b
func()
glos = globals()
glos['d'] = 4
print(d)
print(globals())
执行func()会打印函数func的局部命名空间,结果如下:
{'a': 1, 'b': 2}
执行print(globals())会打印模块test_namespace的全局命名空间,结果如下:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7fde2605c730>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/jkc/PycharmProjects/pythonProject1/test_namespace.py', '__cached__': None, 'func': <function func at 0x7fde246b9310>, 'glos': {...}, 'd': 4}
内置函数locals()、globals()都会返回一个字典。区别:前者只读、后者可写。
命名空间在from module_name import 、import module_name中的体现:from关键词是导入模块或包中的某个部分。
- from module_A import X:会将该模块的函数/变量导入到当前模块的命名空间中,无须用module_A.X访问了。
- import module_A:modules_A本身被导入,但保存它原有的命名空间,故得用module_A.X方式访问其函数或变量。
接下来我们测试一下:
可以看到我们导入了函数a和模块file_c,接着我们打印了全局变量,结果如下:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7fab9585c730>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/jkc/PycharmProjects/pythonProject1/test3/test_namespace.py', '__cached__': None, 'a': <function a at 0x7fab95b04040>, 'file_c': <module 'file_c' from '/Users/jkc/PycharmProjects/pythonProject1/test3/file_c.py'>}
可以很清楚的看到全局变量中有函数a和模块file_c,接着我们尝试能否调用者2个
from test2.file_a import a
import file_c
print(globals())
file_c.c()
a()
最后也是可以成功调用
4. 导入
准备工作如下:

4.1 绝对导入
所有的模块import都从“根节点”开始。根节点的位置由sys.path中的路径决定,项目的根目录一般自动在sys.path中。如果希望程序能处处执行,需手动修改sys.path。
例1:c.py中导入B包/B1子包/b1.py模块
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
# 导入B包中的子包B1中的模块b1
from B.B1 import b1
例2:b1.py中导入b2.py模块
# 从B包中的子包B1中导入模块b2
from B.B1 import b2
4.2 相对导入
只关心相对自己当前目录的模块位置就好。不能在包(package)的内部直接执行(会报错)。不管根节点在哪儿,包内的模块相对位置都是正确的。
b1.py代码如下:
# from . import b2 # 这种导入方式会报错
import b2 # 正确
b2.print_b2()
b2.py代码如下:
def print_b2():
print('b2')
最后运行b1.py,打印b2。
4.3 单独导入包
单独import某个包名称时,不会导入该包中所包含的所有子模块。
c.py导入同级目录B包的子包B1包的b2模块,执行b2模块的print_b2()方法:
c.py代码
import B
B.B1.b2.print_b2()
运行c.py会以下错误
AttributeError: module 'B' has no attribute 'B1'
因为import B并不会自动将B下的子模块导入进去,需要手动添加,解决办法如下
在B/init.py代码下添加如下代码
from . import B1
在B/B1/init.py代码下添加如下代码
from . import b2
此时,执行c.py,成功打印b2。
5. import运行机制
我们要理解Python在执行import语句时,进行了啥操作?
step1:创建一个新的、空的module对象(它可能包含多个module);
step2:将该module对象 插入sys.modules中;
step3:装载module的代码(如果需要,需先编译);
step4:执行新的module中对应的代码。
在执行step3时,首先需找到module程序所在的位置,如导入的module名字为mod_1,则解释器得找到mod_1.py文件,搜索顺序是:
当前路径(或当前目录指定sys.path)->PYTHONPATH->Python安装设置相关的默认路径。
对于不在sys.path中,一定要避免用import导入自定义包(package)的子模块(module),而要用from…import… 的绝对导入或相对导入,且包(package)的相对导入只能用from形式。
5.1 标准import,顶部导入

5.2 嵌套import
5.2.1 顺序导入-import
- moduleB定义了变量b=2
- moduleA导入模块moduleB,当然moduleB还可以导入其他模块
- test模块导入moduleA

最后执行test.py,将打印3
5.2.2 循环导入/嵌套导入
moduleA.py
from moduleB import ClassB
class ClassA:
pass
moduleB.py
from moduleA import ClassA
class ClassB:
pass
当执行moduleA.py时会报错
ImportError: cannot import name 'ClassA' from partially initialized module 'moduleA'
报错分析:
- 在运行moduleA时,首选会执行
from moduleB import ClassB代码 - 程序会判断
sys.modules中是否有 - 有代表字在第一次执行时,创建的对象已经缓存在
sys.modules,直接得到,不过依然是空对象,因为__dict__找不到ClassB,会报错 - 没有会为moduleB.py创建1个module对象,此时创建的module对象为空
4.1 然后执行moduleB.py的第一条语句from moduleA import ClassA
PS:这么做的原因是python内部创建了module对象后立马执行moduleB.py,目的是填充<module moduleB>的__dict__,当然最终未能成功填充
4.2 接着判断sys.modules中是否有
4.3 没有会为moduleA.py创建1个module对象
PS:此时创建的module对象同样为空,则需要执行moduleA.py语句from moduleB import ClassB - 最后回到操作2的过程,这次判断有module对象,会进行操作3,最后就会报错
cannot import name 'ClassA'
解决办法:组织代码(重构代码):更改代码布局,可合并或分离竞争资源。
参考内如如下:
Python 3.x | 史上最详解的导入(import)
Python Module
python进阶(28)import导入机制原理的更多相关文章
- 7行代码,彻底告别python第三方包import导入问题!
最近有不少小伙伴咨询关于pyton第三方包导入的问题,今天我们就来聊聊第三方包导入那些事. 随着对python学习的渐入臻境,越来越多的小伙伴们开始导入自己所需的第三方包,实现各种各样的功能.但是,他 ...
- python tips(3);import的机制
1.标准的import python中,所有加载到内存中的模块都是放在sys.modules中,当import一个模块的时候,会在这个列表中查看是否加载了这个模块,如果加载了,则只是将模块名字加入到正 ...
- python进阶(一) 多进程并发机制
python多进程并发机制: 这里使用了multprocessing.Pool进程池,来动态增加进程 #coding=utf-8 from multiprocessing import Pool im ...
- Python高级语法-import导入-sys.path(4.4.1)
@ 目录 1.说明 2.代码 关于作者 1.说明 在开发程序的过程中,往往使用sys.path去验证下导入的目录,返回的是列表 先后顺序,就是扫描的先后顺序 ,也可以加入搜索路径 import有个特点 ...
- python进阶篇
python进阶篇 import 导入模块 sys.path:获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到. import sys ...
- 关于Python的import机制原理
很多人用过python,不假思索地在脚本前面加上import module_name,但是关于import的原理和机制,恐怕没有多少人真正的理解.本文整理了Python的import机制,一方面自己总 ...
- Python学习第二阶段,Day2,import导入模块方法和内部原理
怎样导入模块和导入包?? 1.模块定义:代码越来越多的时候,所有代码放在一个py文件无法维护.而将代码拆分成多个py文件,同一个名字的变量互不影响,模块本质上是一个.py文件或者".py&q ...
- Python进阶(十六)----面向对象之~封装,多态,鸭子模型,super原理(单继承原理,多继承原理)
Python进阶(十六)----面向对象之~封装,多态,鸭子模型,super原理(单继承原理,多继承原理) 一丶封装 , 多态 封装: 将一些东西封装到一个地方,你还可以取出来( ...
- python笔记-1(import导入、time/datetime/random/os/sys模块)
python笔记-6(import导入.time/datetime/random/os/sys模块) 一.了解模块导入的基本知识 此部分此处不展开细说import导入,仅写几个点目前的认知即可.其 ...
- python笔记-6(import导入、time/datetime/random/os/sys模块)
一.了解模块导入的基本知识 此部分此处不展开细说import导入,仅写几个点目前的认知即可.其它内容待日后有深入理解了再来细说 1.import可以导入的两种不同的内容 1.1 *.py文件结尾的文件 ...
随机推荐
- 八皇后代码C语言版本
y = x + b -> y-x = b 主对角线上,行下标与列下标之差相等y = -x + b -> y+x = b 副对角线上,行下标与列下标之和相等主对角线 ...
- TDengine概述以及架构模型
TDengine TDengine是一个高效的存储.查询.分析时序大数据的平台,专为物联网.车联网.工业互联网.运维监测等优化而设计. 您可以像使用关系型数据库MySQL一样来使用它. TDengin ...
- 解决swiper组件autoplay报错问题
最近在自定义一个swiper 插件 发现引用之后不定时一直在报错 Uncaught TypeError: Cannot read properties of undefined (reading 'a ...
- Java中的Optional
在我们日常的开发中,我们经常会遇到 NullPointerException.如何才能优雅的处理NPE?这里告诉大家一个较为流行的方法 java.util.Optional 使用Optional来修饰 ...
- 前端 vue表格数据导出Excel 文件实现
实现思路 使用json2csv将后台json数据转化为csv格式数据 采用创建Blob(二进制大对象)的方式来存放缓存数据: 生成下载链接: 创建一个a标签,设置href和download属性 触发a ...
- 关于Elasticsearch使用java的说明
从Elastic 7.0开始,我们可以不安装JAVA.安装包包含一个相匹配的JAVA版本在里面. Elasticsearch包含来自JDK维护者(GPLv2 + CE)的捆绑版OpenJDK. 要使用 ...
- Dockerfile文件全面详解
Docker 可以通过读取 Dockerfile 中的指令自动构建镜像.Dockerfile 是一个文本文档,其中包含了用户创建镜像的所有命令和说明. 一. 变量 变量用 $variable_name ...
- Elasticsearch:Split index API - 把一个大的索引分拆成更多分片
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/108960950
- Python-函数-字符串函数
函数 1.字符串函数 #(1)add() 对两个数组的元素进行字符串连接 import numpy as np print(np.char.add(["xiaodu"],[&quo ...
- C# 基础 之:Task 用法
参考来源:https://www.cnblogs.com/zhaoshujie/p/11082753.html 他介绍的可以说是非常详细,附带Demo例子讲解 1.入门 Task看起来像一个Threa ...