生产环境Java应用服务内存泄漏分析与解决
有个生产环境CRM业务应用服务,情况有些奇怪,监控数据显示内存异常。内存使用率99.%多。通过生产监控看板发现,CRM内存超配或内存泄漏的现象,下面分析一下这个问题过程记录。
服务器配置情况:
生产服务器采用阿里云ECS机器,配置是4HZ、8GB,单个应用服务独占,CRM应用独立部署,即单台服务器仅部署一个java应用服务。
用了4个节点4台机器,每台机器都差不多情况。
监控看板如下:




内存分布统计:
从监控看板的数据来看,我们简单统计一下内存分配数据情况。
应用启动配置参数:
/usr/bin/java
-javaagent:/home/agent/skywalking-agent.jar
-Dskywalking.agent.service_name=xx-crm
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/xx-crm.hprof
-Dspring.profiles.active=prod
-server -Xms4884m -Xmx4884m -Xmn3584m
-XX:MetaspaceSize=512m
-XX:MaxMetaspaceSize=512m
-XX:CompressedClassSpaceSize=128m
-jar /home/xxs-crm.jar
堆内存 4.8G左右,其中新生代3.5G左右,
非堆内存:(Metaspace)512M+(CompressedClassSpace)128M+(Code Cache)240M约等1G左右.
堆内存(heap)+非堆内存(non-Heap)=5.8G,8GB物理内存除去操作系统本身占用大概500M,起码至少还有1~2GB空闲才合理呀!怎么竟然占了99%多,就意味着有1~2G不知道谁占去了,有点诡异!
先看一下JVM内存模型,环境是使用JDK8
JVM内存数据分区:

堆heap结构:
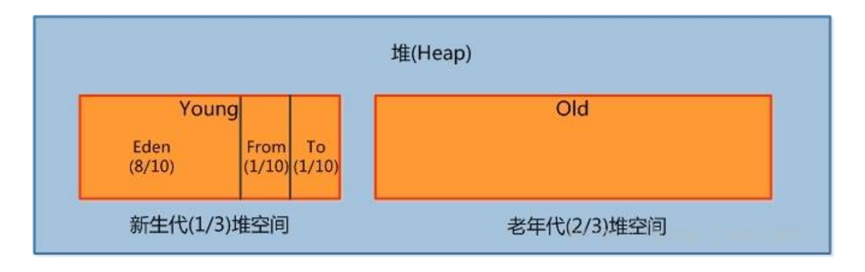
堆大家都比较容易理解的,也是java程序接触得最多的一块,不存在什么数据上统计错误,或占用不算之类的。
那说明额外占用也非堆里面,只不过没有统计到非堆里面去,曾经一度怀疑监控prometheus展示的数据有误。
先看一下dump文件数据,这里使用MAT工具(一个开源免费的内存分析工具,个人认为比较好用,推荐大家使用)。
通过下载内存dump镜像观察到

有个offHeapStore,这个东西堆外内存,可以初步判断是 ehcahe引起的。
通过ehcahe源码分析,发现ehcache里面也使用了netty的NIO方法内存,ehcache磁盘缓存写数据时会用到DirectByteBuffer。
DirectByteBuffer是使用非堆内存,不受GC影响。
当有文件需要暂存到ehcache的磁盘缓存时,使用到了NIO中的FileChannel来读取文件,默认ehcache使用了堆内的HeapByteBuffer来给FileChannel作为读取文件的缓冲,FileChannel读取文件使用的IOUtil的read方法,针对HeapByteBuffer底层还用到一个临时的DirectByteBuffer来和操作系统进行直接的交互。
ehcache使用HeapByteBuffer作为读文件缓冲:

IOUtil对于HeapByteBuffer实际会用到一个临时的DirectByteBuffer来和操作系统进行交互。

DirectByteBuffer泄漏根因分析
默认情况下这个临时的DirectByteBuffer会被缓存在一个ThreadLocal的bufferCache里不会释放,每一个bufferCache有一个DirectByteBuffer的数组,每次当前线程需要使用到临时DirectByteBuffer时会取出自己bufferCache里的DirectByteBuffer数据,选取一个不小于所需size的,如果bufferCache为空或者没有符合的,就会调用Bits重新创建一个,使用完之后再缓存到bufferCache里。
这里的问题在于 :这个bufferCache是ThreadLocal的,意味着极端情况下有N个调用线程就会有N组 bufferCache,就会有N组DirectByteBuffer被缓存起来不被释放,而且不同于在IO时直接使用DirectByteBuffer,这N组DirectByteBuffer连GC时都不会回收。我们的文件服务在读写ehcache的磁盘缓存时直接使用的tomcat的worker线程池,
这个worker线程池的配置上限是2000,我们的配置中心上的配置的参数:

所以,这种隐藏的问题影响所有使用到HeapByteBuffer的地方而且很隐秘,由于在CRM服务中大量使用了ehcache存在较大的sizeIO且调用线程比较多的场景下容易暴露出来。
获取临时DirectByteBuffer的逻辑:

bufferCache从ByteBuffer数组里选取合适的ByteBuffer:

将ByteBuffer回种到bufferCache:

NIO中的FileChannel、SocketChannel等Channel默认在通过IOUtil进行IO读写操作时,除了会使用HeapByteBuffer作为和应用程序的对接缓冲,但在底层还会使用一个临时的DirectByteBuffer来和系统进行真正的IO交互,为提高性能,当使用完后这个临时的DirectByteBuffer会被存放到ThreadLocal的缓存中不会释放,当直接使用HeapByteBuffer的线程数较多或者IO操作的size较大时,会导致这些临时的DirectByteBuffer占用大量堆外直接内存造成泄漏。
那么除了减少直接调用ehcache读写的线程数有没有其他办法能解决这个问题?并发比较高的场景下意味着减少业务线程数不是一个好办法。
在Java1.8_102版本开始,官方提供一个参数jdk.nio.maxCachedBufferSize,这个参数用于限制可以被缓存的DirectByteBuffer的大小,对于超过这个限制的DirectByteBuffer不会被缓存到ThreadLocal的bufferCache中,这样就能被GC正常回收掉。唯一的缺点是读写的性能会稍差一些,毕竟创建一个新的DirectByteBuffer的代价也不小,当然如上面列出的,性能也没有数量级的差别。
增加参数:
-XX:MaxDirectMemorySize=1600m
-Djdk.nio.maxCachedBufferSize=500000 ---注意不能带单位
就是调整了-Djdk.nio.maxCachedBufferSize=500000(注意这里是字节数,不能用m、k、g等单位)。
增加调整参数之后,运行一段时间,持续观察整体DirectByteBuffer稳定控制在1.5G左右,性能也几乎没有衰减。一切恢复正常,再看监控看板没有看到占满内存告警。
业务系统调整后的启动命令参数如下:
java
-javaagent:/home/agent/skywalking-agent.jar
-Dskywalking.agent.service_name=xx-crm
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/xx-crm.hprof
-Dspring.profiles.active=prod
-server -Xms4608m -Xmx4608m -Xmn3072m
-XX:MetaspaceSize=300m
-XX:MaxMetaspaceSize=512m
-XX:CompressedClassSpaceSize=64m
-XX:MaxDirectMemorySize=1600m
-Djdk.nio.maxCachedBufferSize=500000
-jar /home/xx-crm.jar
参考文章《Troubleshooting Problems With Native (Off-Heap) Memory in Java Applications》:
https://dzone.com/articles/troubleshooting-problems-with-native-off-heap-memo
生产环境Java应用服务内存泄漏分析与解决的更多相关文章
- Android 内存泄漏分析与解决方法
在分析Android内存泄漏之前,先了解一下JAVA的一些知识 1. JAVA中的对象的创建 使用new指令生成对象时,堆内存将会为此开辟一份空间存放该对象 垃圾回收器回收非存活的对象,并释放对应的内 ...
- Android开发之漫漫长途 番外篇——内存泄漏分析与解决
该文章是一个系列文章,是本人在Android开发的漫漫长途上的一点感想和记录,我会尽量按照先易后难的顺序进行编写该系列.该系列引用了<Android开发艺术探索>以及<深入理解And ...
- JAVA简单内存泄露分析及解决
一.问题产生 项目采用Tomcat6.0为服务器,数据库为mysql5.1,数据库持久层为hibernate3.0,以springMVC3.0为框架,项目开发完成后,上线前夕进行稳定性拷机,测试 ...
- 生产环境如何快速跟踪、分析、定位问题-Java
我相信做技术的都会遇到过这样的问题,生产环境服务遇到宕机的情况下如何去分析问题?比如说JVM内存爆掉.CPU持续高位运行.线程被夯住或线程deadlocks,面对这样的问题,如何在生产环境第一时间跟踪 ...
- Java内存泄漏分析与解决方案
Java内存泄漏是每个Java程序员都会遇到的问题,程序在本地运行一切正常,可是布署到远端就会出现内存无限制的增长,最后系统瘫痪,那么如何最快最好的检测程序的稳定性,防止系统崩盘,作者用自已的亲身经历 ...
- Java内存泄漏分析系列之五:常见的Thread Dump日志案例分析
原文地址:http://www.javatang.com 症状及解决方案 下面列出几种常见的症状即对应的解决方案: CPU占用率很高,响应很慢 按照<Java内存泄漏分析系列之一:使用jstac ...
- Java内存泄漏分析系列之二:jstack生成的Thread Dump日志结构解析
原文地址:http://www.javatang.com 一个典型的thread dump文件主要由一下几个部分组成: 上图将JVM上的线程堆栈信息和线程信息做了详细的拆解. 第一部分:Full th ...
- Java内存泄漏分析和预防
1. 什么是内存泄漏?有什么危害 书面说法: 内存泄漏:对象已经没有被应用程序使用,但是垃圾回收器没办法移除它们,因为还在被引用着. 在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个 ...
- Android内存泄漏分析及调试
尊重原创作者,转载请注明出处: http://blog.csdn.net/gemmem/article/details/13017999 此文承接我的另一篇文章:Android进程的内存管理分析 首先 ...
- android 内存泄漏分析技巧
java虚拟机执行一般都有一个内存界限,超过这个界限,就会报outofmemory.这个时候一般都是存在内存泄漏.解决内存泄漏问题,窃以为分为两个步骤:分析应用程序是否真的有内存泄漏,找到内存泄漏的地 ...
随机推荐
- hive支持的压缩算法
压缩格式的设置 set mapred.output.compression= 压缩格式 工具 算法 扩展名 是否支持分割 Hadoop编码/解码器 default deflate .deflate N ...
- spring jdbcTemplate 配置
1 <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" 2 d ...
- 065_VFPage中CallBack回调函数的解释
关于JS 的回调函数解释: https://blog.csdn.net/baidu_32262373/article/details/54969696 https://www.cnblogs.com/ ...
- 第八章 mysql的主从复制
mysql的主从复制 一 主从复制搭建 1. 准备三台主机 (这个是多实例) 3307 master3308 salve13309 salve2 2. master 节点设置 [mysqld] lo ...
- 启动Eureka报org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'configurationPropertiesBeans' defined in class path resource
我出现这种情况是下图两个版本不对应 要结合官文档的版本号 也就是说将parent版本号改为2.2.x或者2.3.x
- 2021/9/26 Leetcode 两数之和
题目:给你两个整数 a 和 b ,不使用 运算符 + 和 - ,计算并返回两整数之和. int getSum(int a, int b) { while(b != 0){ unsigne ...
- 通过ref调取子组件方法
子 async update(res){ //this.$refs.child.animates(); this.userform = res; }, 主 <DetailEdit @detail ...
- linux安装等
软碟通刻入某版本linux 推荐方法 2) 1) U盘启动 修改vmlinuz initrd=initrd.img linux dd quiet 查看U盘盘符 重启修改hd:/dev/sd** qui ...
- wpf 使用了 template 了的 combobox 中,displaymemberpath 有 bug,仅在 popup 中生效
需求是:仅想改变combobox的默认样式,所以 template 是直接在属性窗口点击转化为本地值的. using System.Collections.Generic; using System. ...
- howork7
" 形式化方法 阅读了解形式化方法形式化方法|形式化方法对软件开发的挑战:历史与发展 根据表达能力,形式化方法可以分为五类: 1)基于模型的方法:通过明确定义状态和操作来建立一个系统模型 ...