在昇腾平台上对TensorFlow网络进行性能调优
摘要:本文就带大家了解在昇腾平台上对TensorFlow训练网络进行性能调优的常用手段。
本文分享自华为云社区《在昇腾平台上对TensorFlow网络进行性能调优》,作者:昇腾CANN 。
用户将TensorFlow训练网络迁移到昇腾平台后,如果存在性能不达标的问题,就需要进行调优。本文就带大家了解在昇腾平台上对TensorFlow训练网络进行性能调优的常用手段。
首先了解下性能调优的全流程:
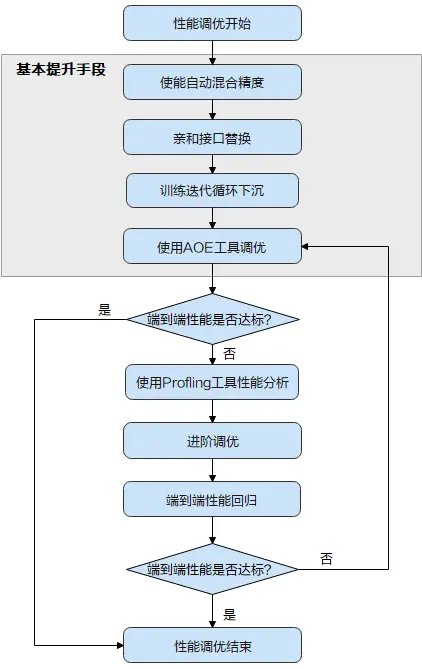
当TensorFlow训练网络性能不达标时,首先可尝试昇腾平台提供的“三板斧”操作,即上图中的“基本提升手段”:使能自动混合精度 > 进行亲和接口的替换 > 使能训练迭代循环下沉 > 使用AOE工具进行调优。
基本调优操作完成后,需要再次执行模型训练并评估性能,如果性能达标了,调优即可结束;如果未达标,需要使用Profling工具采集详细的性能数据进一步分析,从而找到性能瓶颈点,并进一步针对性的解决,这部分调优操作需要用户有一定的经验,难度相对较大,我们将这部分调优操作称为进阶调优。
本文主要带大家详细了解基本调优操作,即上图中的灰色底纹部分。
使能自动混合精度
混合精度是业内通用的性能提升方式,通过降低部分计算精度提升数据计算的并行度。混合计算训练方法通过混合使用float16和float32数据类型来加速深度神经网络的训练过程,并减少内存使用和存取,从而可以提升训练网络性能,同时又能基本保证使用float32训练所能达到的网络精度。
Ascend平台提供了“precision_mode”参数用于配置网络的精度模式,用户可以在训练脚本的运行配置中添加此参数,并将取值配置为“allow_mix_precision”,从而使能自动混合精度,下面以手工迁移的训练脚本为例,介绍配置方法。
- Estimator模式下,在NPURunConfig中添加precision_mode参数设置精度模式:
npu_config=NPURunConfig(
model_dir=FLAGS.model_dir,
save_checkpoints_steps=FLAGS.save_checkpoints_steps, session_config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=False),
precision_mode="allow_mix_precision"
)
- sess.run模式下,通过session配置项precision_mode设置精度模式:
config = tf.ConfigProto(allow_soft_placement=True)
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision")
…
with tf.Session(config=config) as sess:
print(sess.run(cost))
亲和接口替换
针对TensorFlow训练网络中的dropout、gelu接口,Ascend平台提供了硬件亲和的替换接口,从而使网络获得更优性能。
- 对于训练脚本中的nn.dropout,建议替换为Ascend对应的API实现,以获得更优性能:
layers = npu_ops.dropout()
- 若训练脚本中存在layers.dropout、tf.layers.Dropout、tf.keras.layers.Dropout、tf.keras.layers.SpatialDropout1D、tf.keras.layers.SpatialDropout2D、tf.keras.layers.SpatialDropout3D接口,建议增加头文件引用:
from npu_bridge.estimator.npu import npu_convert_dropout
- 对于训练脚本中的gelu接口,建议替换为Ascend提供的gelu接口,以获得更优性能。
例如,TensorFlow原始代码:
迁移后的代码:
from npu_bridge.estimator.npu_unary_ops import npu_unary_ops
layers = npu_unary_ops.gelu(x)
训练迭代循环下沉
训练迭代循环下沉是指在Host调用一次,在Device执行多次迭代,从而减少Host与Device间的交互次数,缩短训练时长。用户可通过iterations_per_loop参数指定训练迭代的次数,该参数取值大于1即可使能训练迭代循环下沉的特性。
使用该特性时,要求训练脚本使用TF Dataset方式读数据,并开启数据预处理下沉,即enable_data_pre_proc开关配置为True,例如sess.run配置示例如下:
custom_op.parameter_map["enable_data_pre_proc"].b = True
其他使用约束,用户可参见昇腾文档中心的《TensorFlow模型迁移和训练指南》。
Estimator模式下,通过NPURunConfig中的iterations_per_loop参数配置训练迭代循环下沉的示例如下:
session_config=tf.ConfigProto(allow_soft_placement=True)
config = NPURunConfig(session_config=session_config, iterations_per_loop=10)
AOE自动调优
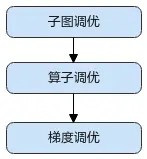
昇腾平台提供了AOE自动调优工具,可对网络进行子图调优、算子调优与梯度调优,生成最优调度策略,并将最优调度策略固化到知识库。模型再次训练时,无需开启调优,即可享受知识库带来的收益。
建议按照如下顺序使用AOE工具进行调优:
训练场景下使能AOE调优有两种方式:
- 通过设置环境变量启动AOE调优。
# 1:子图调优
# 2:算子调优
# 4:梯度调优
export AOE_MODE=2
- 修改训练脚本,通过“aoe_mode”参数指定调优模式,例如:
sess.run模式,训练脚本修改方法如下:
custom_op.parameter_map["aoe_mode"].s = tf.compat.as_bytes("2")
estimator模式下,训练脚本修改方法如下:
config = NPURunConfig(
session_config=session_config,
aoe_mode=2)
以上就是TensorFlow网络在昇腾平台上进行性能调优的常见手段。关于更多文档介绍,可以在昇腾文档中心查看,您也可在昇腾社区在线课程板块学习视频课程,学习过程中的任何疑问,都可以在昇腾论坛互动交流!
相关参考:
[1]昇腾文档中心
[2]昇腾社区在线课程
[3]昇腾论坛
在昇腾平台上对TensorFlow网络进行性能调优的更多相关文章
- tensorflow 性能调优相关
如何进行优化tensorflow 将极大得加速机器学习模型的训练的时间,下面是一下tensorflow性能调优相关的阅读链接: tensorflow 性能调优:http://d0evi1.com/te ...
- sql server 性能调优 资源等待之网络I/O
原文:sql server 性能调优 资源等待之网络I/O 一.概述 与网络I/O相关的等待的主要是ASYNC_NETWORK_IO,是指当sql server返回数据结果集给客户端的时候,会先将结果 ...
- Oracle 12C -- 网络性能调优
1.传输数据压缩 网络性能主要受两方面影响:bandwidth和data volume. 在网络层对数据进行压缩,可以减少对网络带宽的需求.而且对应用是透明的. 如果是CPU是瓶颈时开启网络层数据压缩 ...
- KVM网络性能调优
首先,我给大家看一张图,这张图是数据包从虚拟机开始然后最后到物理网卡的过程. 我们分析下这张图,虚拟机有数据包肯定是先走虚拟机自身的那张虚拟网卡,然后发到中间的虚拟化层,再然后是传到宿主机里的内核网桥 ...
- sql server 性能调优之 资源等待之网络I/O
一.概述 与网络I/O相关的等待的主要是ASYNC_NETWORK_IO,是指当sql server返回数据结果集给客户端的时候,会先将结果集填充到输出缓存里(ouput cache),同时网络层会开 ...
- Windows平台下tomcat 性能调优
Tomcat 线程查看工具: https://blog.csdn.net/jrainbow/article/details/49026365 16G内存 Tomcat并发优化.内存配置.垃圾回收.宕机 ...
- BEA WebLogic平台下J2EE调优攻略--转载
BEA WebLogic平台下J2EE调优攻略 2008-06-25 作者:周海根 出处:网络 前 言 随着近来J2EE软件广泛地应用于各行各业,系统调优也越来越引起软件开发者和应用服务器提供 ...
- 《Linux 性能及调优指南》1.5 网络子系统
翻译:飞哥 (http://hi.baidu.com/imlidapeng) 版权所有,尊重他人劳动成果,转载时请注明作者和原始出处及本声明. 原文名称:<Linux Performance a ...
- 《linux性能及调优指南》 3.5 网络瓶颈
3.5 Network bottlenecks A performance problem in the network subsystem can be the cause of many prob ...
- GitHub Android 最火开源项目Top20 GitHub 上的开源项目不胜枚举,越来越多的开源项目正在迁移到GitHub平台上。基于不要重复造轮子的原则,了解当下比较流行的Android与iOS开源项目很是必要。利用这些项目,有时能够让你达到事半功倍的效果。
1. ActionBarSherlock(推荐) ActionBarSherlock应该算得上是GitHub上最火的Android开源项目了,它是一个独立的库,通过一个API和主题,开发者就可以很方便 ...
随机推荐
- Linux基础第八章:操作系统引导过程、运行级别及开机问题处理
一.操作系统引导过程 1.开机自检(bios) 2.MBR引导 3.grub菜单 4.加载内核(kernel) 5.init进程初始化 二.操作系统运行级别(init0-init6) 1.init 0 ...
- django自定义管理类的save model和delete model记一次进一步了解
业务背景: 最近在写一个个人博客网站,文章分类是一个自关联的两层分类.希望在点开分类时,显示一级分类.一级分类下的所有二级分类以及每个二级分类有多少个文章.最简单办法就是关联查询,查询出所有二级分类, ...
- kvm介绍(1)
- 「DIARY」PKUSC 2021 游记
冬令营没了但是还有夏令营 (完蛋,前两天忘写游记了,完全没想起来--最后一天补一补) 试题分析在另外一篇博客上 # Day 0 早上去机场的时候把手机落在出租车上了 (还好之后找回来了),导致我前两天 ...
- .netcore 跨域问题
CORS(跨域资源共享)是一种W3C标准,允许服务器放宽同源策略.使用CORS,服务器可以在显式允许某些跨域请求时拒绝其他跨域请求.CORS是相比其他跨域技术(比如JSONP)更安全.更灵活. ASP ...
- tensorflow 模型批处理参数tensor快速赋值参考
批处理调用模型的时候,如果逐像素给tensor对象数据部分赋值的话,效率是很低的,尤其是对于一些图片数据,所以数据块直接拷贝可以大大提高效率, 先取得数据指针: output_tensor->f ...
- mysql之存储引擎-第二篇
什么是存储引擎? 数据库存储引擎是数据库底层软件组件,数据库管理系统使用数据引擎进行创建,查询,更新和删除数据操作.不同的存储引擎提供了不同的存储机制,索引技巧及特定功能. 存储引擎类型 InnoDB ...
- 解决nios eclipse报错: WARNING: Couldn't compute FAST_CWD pointer的方法
几天照着书上的例子弄nios的开发流程,编译的时候遇见了这个问题 WARNING: Couldn't compute FAST_CWD pointer 在网上找了大半天解决方法,如下: 链接:http ...
- this和箭头函数的this
https://www.cnblogs.com/lfri/p/11872696.html https://www.ruanyifeng.com/blog/2018/06/javascript-this ...
- Oracle学习-----基本SQL select语句
一.基本select语句 SELECT 标识 选择那些列 FROM 标识从哪个表中选择 select * 标识 全部选择 select department_id, location_id ...