zookeeper要点总结
简述:zookeeper分布式协调服务,节点数据存储在内存,高吞吐,低延时,zkserver cluster组建zookeeper service保证自身高可用
zookeeper数据模型为类文件目录树结构的文件系统,node节点可以存放1m数据(主要用于存储同步数据及节点元数据,注:数据存储在内存,log存储于磁盘)
角色组成:
- Leader:负责zxid维护,数据同步,与follower之间消息队列维护
- Follower:接受client请求,负责写请求转到leader数据的读取
- Observer:监控指定节点数据变化
数据模型:
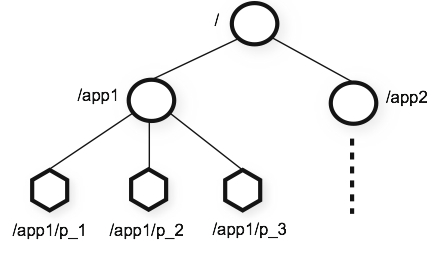
zookeeper节点类型:
- 持久节点:(persistent):client默认创建的znode节点,都是持久节点
- 临时节点(Ephemeral Nodes):client与zookeeper保持连接时有效,断开znode节点消失。用于session,session结束节点删除,此节点不能有子节点
- 顺序节点(Sequence Nodes):可以是临时也可以是持久的。zookeeper维护一个计数器,保证在相同父节点下,节点的唯一性,注:计数器使用4bytes的int存储下一个节点序号
zookeeper特征/保证:
- 顺序一致性:按client发送过来顺序对数据进行更新
- 原子性:数据更新只有失败和成功两种状态,没有其它结果
- 相同的视图:client无论连接到哪个server,client都将看到相同的视图
- 可靠性:一旦数据更新,从更新的那个时刻一直延续到下一次覆盖更新
- 及时性:clint的视图保证在特定时间内,client看到的视图是最新的
zookeeper角色关联:
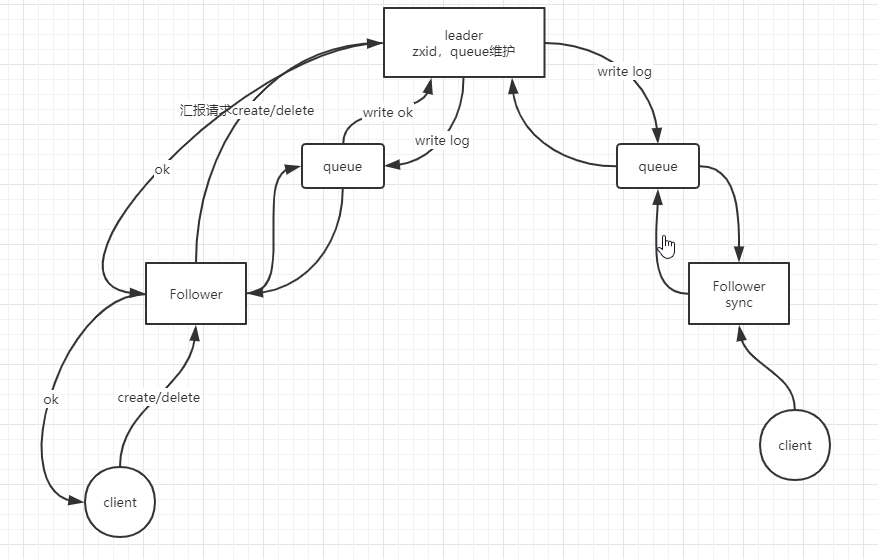
注:当leader挂掉,没有新的leader时则zookeeper拒绝对外服务
zookeeper会话(session):
client与server建立连接zookeeper会分配id,client在特定时间间隔内发送心跳到server保持session有效,如果指定时间未收到心跳,则认为client无效,session中创建的ephemeral节点会被删除
zookeeper监控(Watch):
client在读取特定的节点上设置watch,当此节点发生变化时,会向注册watch的client发送通知。注:这里指触发一次,如client想再次获取通知,则必须通过另一个读取操作来完成,client断开则watch也被删除
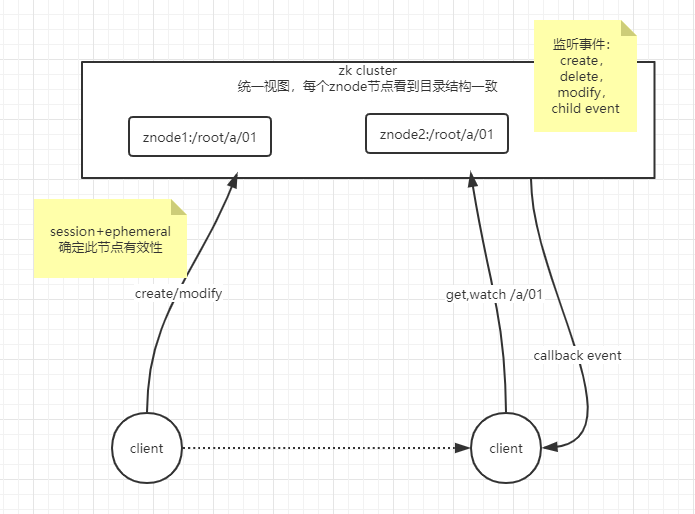
zookeeper应用:
1,HA,主的选举:
2,分布式锁:ephemeral特点
zookeeper要点总结的更多相关文章
- 《OD学hadoop》第三周0710
一.分布式集群安装1. Hadoop模式本地模式.伪分布模式.集群模式datanode 使用的机器上的磁盘,存储空间nodemanager使用的机器上的内存和CPU(计算和分析数据) 2. 搭建环境准 ...
- ZooKeeper架构设计及其应用要点
问题导读: 1.ZooKeeper的数据模型是什么 ?2.ZooKeeper应用有哪些陷阱 ?3.每个节点(ZNode)中存储的是什么?4.一个ZNode维护了一个状态结构都包含了什么?5.ZNode ...
- Zookeeper配置要点必看
注意点 zookeeper需要在各个节点的机器上搭建,它的启动也要在各个节点的$ZOOKEEPER_HOME/bin 下启动. 环境搭建 下载安装包并解压. 在$ZOOKEEPER_HOME/conf ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- 搭建zookeeper集群
简介: Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置 ...
- zookeeper集群
0,Zookeeper基本原理 ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower.当客户端Client连接到Zo ...
- 转载:ZooKeeper Programmer's Guide(中文翻译)
本文是为想要创建使用ZooKeeper协调服务优势的分布式应用的开发者准备的.本文包含理论信息和实践信息. 本指南的前四节对各种ZooKeeper概念进行较高层次的讨论.这些概念对于理解ZooKeep ...
- ZooKeeper程序员指南(转)
译自http://zookeeper.apache.org/doc/trunk/zookeeperProgrammers.html 1 简介 本文是为想要创建使用ZooKeeper协调服务优势的分布式 ...
- zookeeper 用法和日常运维
本文以ZooKeeper3.4.3版本的官方指南为基础:http://zookeeper.apache.org/doc/r3.4.3/zookeeperAdmin.html,补充一些作者运维实践中的要 ...
- 分布式中,zookeeper的部署
一:准备 1.概述 为分布式应用提供协调服务的项目 类似于文件系统那样的树形数据结构 目的:将分布式服务不再由于协作冲突而另外实现协作服务 2.数据结构 树形数据结构 zookeeper的每个节点都是 ...
随机推荐
- python解释器下载与基本使用
python介绍与解释器下载基本使用 1.python发展方向 web方向.自动化运维.自动化测试.自动化办公.网络爬虫.金融量化.人工智能.机器学习.数据分析 2.python解释器 历史 ...
- java逻辑运算中 | | 和 | 的区别
本文主要阐明逻辑运算中 | |(短路或) 和 |(逻辑或) 的异同 | | 和 | 的相同之处: 只有二者都是假时,结果才为假,否则结果为true. | | 和 | 的不同之处在于: a | | b: ...
- JavaScript:箭头函数:省略写法
之所以把箭头函数拎出来,是因为它不仅仅是声明函数的一种方式,它还是函数式编程的重要根基,它使得函数的使用更加的灵活,同时,它的语法,也相对于function声明的函数更加灵活和复杂. 箭头函数的省略写 ...
- 数据结构 传统链表实现与Linux内核链表
头文件: #pragma once #include<stdlib.h> //链表结点 struct LinkNode{ void *data; struct LinkNode *next ...
- Flask初步认识
1.Flask基本认识 Flask 本身相当于一个内核,其他几乎所有的功能都要用到扩展包(数据库Flask-SQLAlchemy),都需要用第三方的扩展来实现.比如可以用 Flask 扩展加入ORM. ...
- idea里面连接数据库进行sql操作
常用写法 1. private static void test01() throws ClassNotFoundException, SQLException{ Class.forName(&quo ...
- [OpenCV实战]48 基于OpenCV实现图像质量评价
本文主要介绍基于OpenCV contrib中的quality模块实现图像质量评价.图像质量评估Image Quality Analysis简称IQA,主要通过数学度量方法来评价图像质量的好坏. 本文 ...
- 这可能是Feign调用可重试的最佳方案了
前言 在我们公司里,不同的服务之间通过Feign进行远程调用,但是,我们在尝试使调用可重试时遇到了一个小问题,Feign框架本身可以配置的自己的重试机制,但是它是一刀切的方式,所有的调用都是同样的机制 ...
- 【深入浅出Seata原理及实战】「入门基础专题」带你透析认识Seata分布式事务服务的原理和流程(1)
分布式事务的背景 随着业务的不断发展,单体架构已经无法满足我们的需求,分布式微服务架构逐渐成为大型互联网平台的首选,但所有使用分布式微服务架构的应用都必须面临一个十分棘手的问题,那就是"分布 ...
- BUG日记---运行Tomcat报406错误:根据请求中接收到的主动协商头字段,目标资源没有用户代理可以接受的当前表示,而且服务器不愿意提供缺省表示。
网页报错内容 HTTP Status 406 – 不可接收 Type Status Report 描述 根据请求中接收到的主动协商头字段,目标资源没有用户代理可以接受的当前表示,而且服务器不愿意提供缺 ...