深度学习-08(PaddlePaddle文本分类)
深度学习-08(PaddlePaddle文本分类)
文章目录
NLP概述
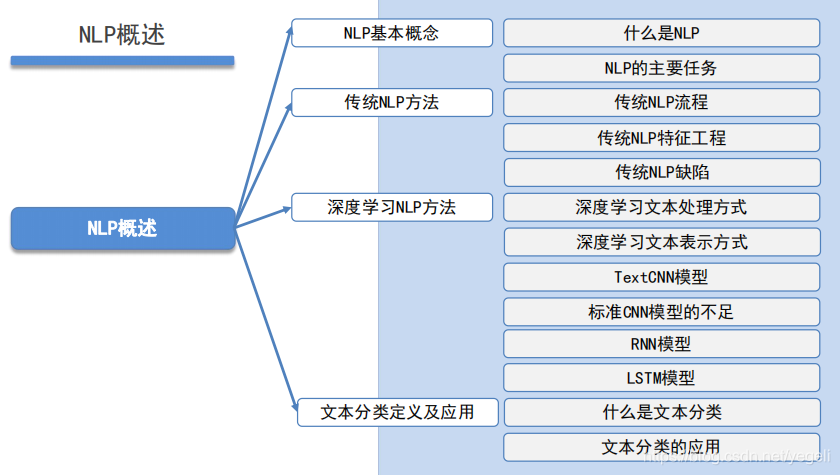
NLP基本概念
什么是NLP


NLP的主要任务




传统NLP方法
传统NLP流程

传统NLP特征工程



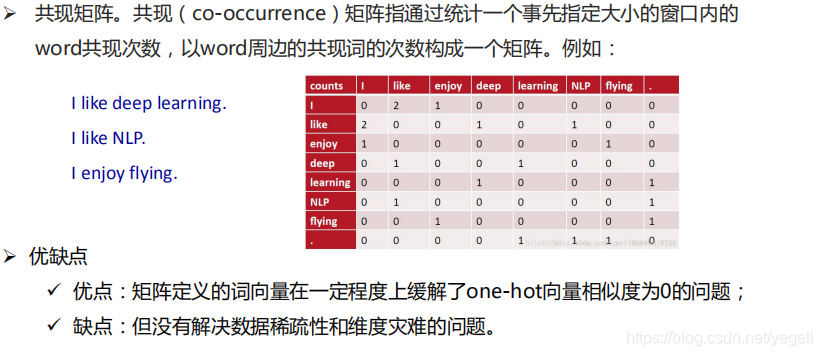

传统NLP缺陷

深度学习NLP方法
深度学习文本处理方式

深度学习文本表示方式


TextCNN模型

标准CNN模型的不足

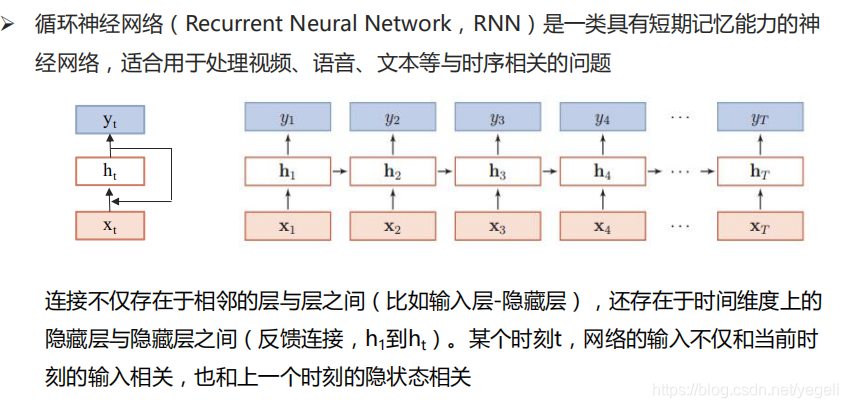
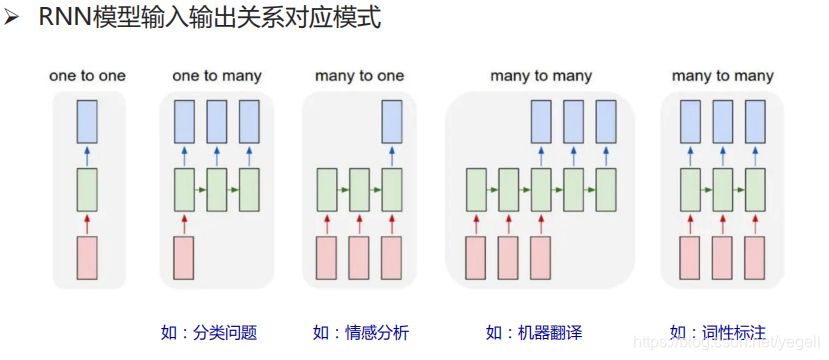
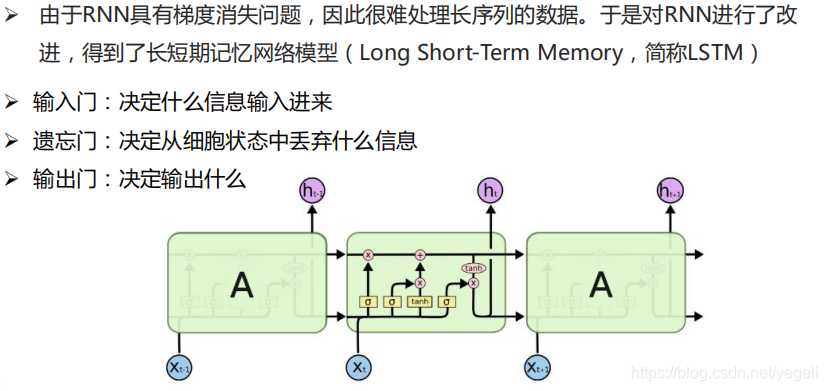
RNN模型


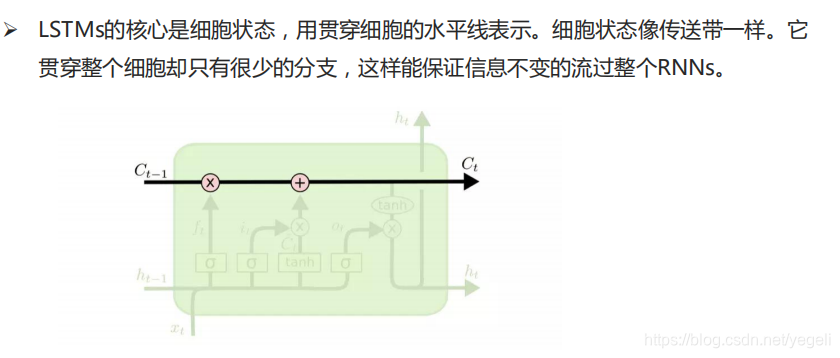
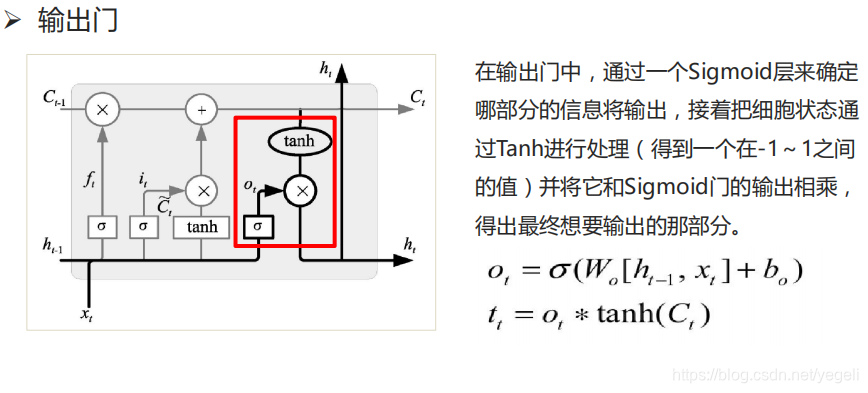
LSTM模型



文本分类定义及应用
什么是文本分类

文本分类的应用

TextCNN实现文本分类
思路及实现
案例目标

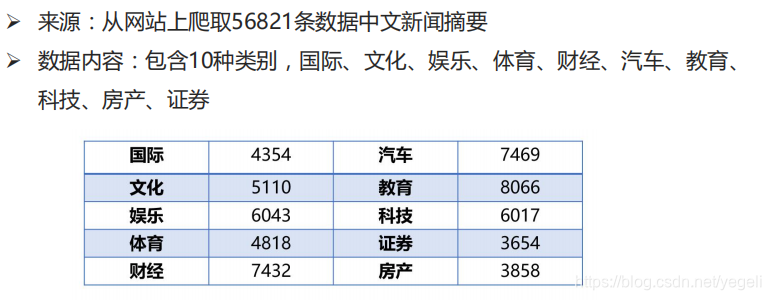
数据集介绍
原始数据格式

网络模型介绍
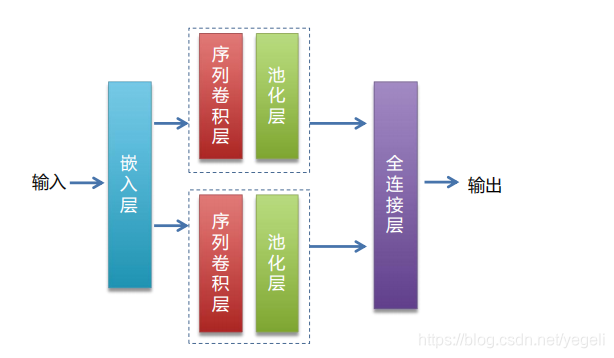
总体步骤

数据预处理
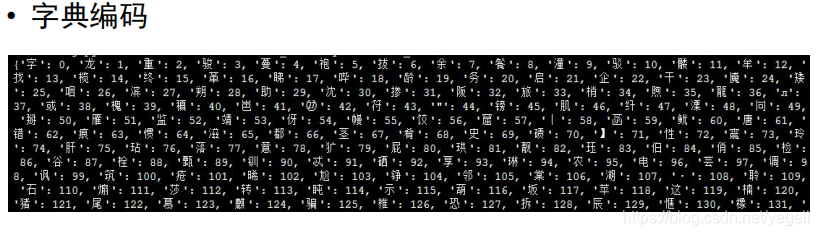
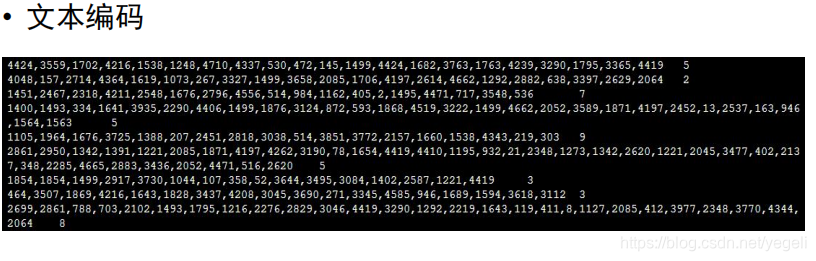
关键代码







训练过程
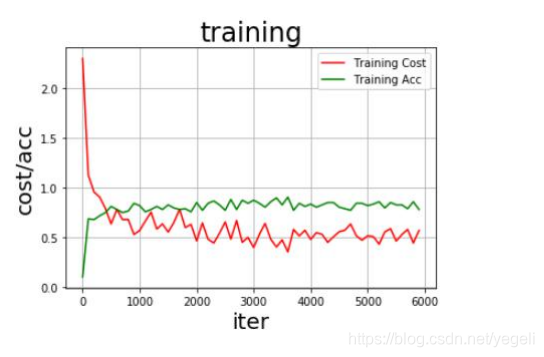
测试结果

代码
AI Studio-百度:中文资讯分类
1.数据预处理
# 中文资讯分类示例
# 任务:根据样本,训练模型,将新的文本划分到正确的类别
'''
数据来源:从网站上爬取56821条中文新闻摘要
数据类容:包含10类(国际、文化、娱乐、体育、财经、汽车、教育、科技、房产、证券)
'''
############################## 数据预处理 ##############################
import os
from multiprocessing import cpu_count
import numpy as np
import paddle
import paddle.fluid as fluid
# 定义公共变量
data_root = "data/news_classify/" # 数据集所在目录
data_file = "news_classify_data.txt" # 原始样本文件名
test_file = "test_list.txt" # 测试集文件名称
train_file = "train_list.txt" # 训练集文件名称
dict_file = "dict_txt.txt" # 编码后的字典文件
data_file_path = data_root + data_file # 样本文件完整路径
dict_file_path = data_root + dict_file # 字典文件完整路径
test_file_path = data_root + test_file # 测试集文件完整路径
train_file_path = data_root + train_file # 训练集文件完整路径
# 生成字典文件:把每个字编码成一个数字,并存入文件中
def create_dict():
dict_set = set() # 集合,去重
with open(data_file_path, "r", encoding="utf-8") as f: # 打开原始样本文件
lines = f.readlines() # 读取所有的行
# 遍历每行
for line in lines:
title = line.split("_!_")[-1].replace("\n", "") #取出标题部分,并取出换行符
for w in title: # 取出标题部分每个字
dict_set.add(w) # 将每个字存入集合进行去重
# 遍历集合,每个字分配一个编码
dict_list = []
i = 0 # 计数器
for s in dict_set:
dict_list.append([s, i]) # 将"文字,编码"键值对添加到列表中
i += 1
dict_txt = dict(dict_list) # 将列表转换为字典
end_dict = {"<unk>": i} # 未知字符
dict_txt.update(end_dict) # 将未知字符编码添加到字典中
# 将字典保存到文件中
with open(dict_file_path, "w", encoding="utf-8") as f:
f.write(str(dict_txt)) # 将字典转换为字符串并存入文件
print("生成字典完成.")
# 对一行标题进行编码
def line_encoding(title, dict_txt, label):
new_line = "" # 返回的结果
for w in title:
if w in dict_txt: # 如果字已经在字典中
code = str(dict_txt[w]) # 取出对应的编码
else:
code = str(dict_txt["<unk>"]) # 取未知字符的编码
new_line = new_line + code + "," # 将编码追加到新的字符串后
new_line = new_line[:-1] # 去掉最后一个逗号
new_line = new_line + "\t" + label + "\n" # 拼接成一行,标题和标签用\t分隔
return new_line
# 对原始样本进行编码,对每个标题的每个字使用字典中编码的整数进行替换
# 产生编码后的句子,并且存入测试集、训练集
def create_data_list():
# 清空测试集、训练集文件
with open(test_file_path, "w") as f:
pass
with open(train_file_path, "w") as f:
pass
# 打开原始样本文件,取出标题部分,对标题进行编码
with open(dict_file_path, "r", encoding="utf-8") as f_dict:
# 读取字典文件中的第一行(只有一行),通过调用eval函数转换为字典对象
dict_txt = eval(f_dict.readlines()[0])
with open(data_file_path, "r", encoding="utf-8") as f_data:
lines = f_data.readlines()
# 取出标题并编码
i = 0
for line in lines:
words = line.replace("\n", "").split("_!_") # 拆分每行
label = words[1] # 分类
title = words[3] # 标题
new_line = line_encoding(title, dict_txt, label) # 对标题进行编码
if i % 10 == 0: # 每10笔写一笔测试集文件
with open(test_file_path, "a", encoding="utf-8") as f:
f.write(new_line)
else: # 写入训练集
with open(train_file_path, "a", encoding="utf-8") as f:
f.write(new_line)
i += 1
print("生成测试集、训练集结束.")
create_dict() # 生成字典
create_data_list() # 生成训练集、测试集
2.模型训练与评估
# 读取字典文件,并返回字典长度
def get_dict_len(dict_path):
with open(dict_path, "r", encoding="utf-8") as f:
line = eval(f.readlines()[0]) # 读取字典文件内容,并返回一个字典对象
return len(line.keys())
# 定义data_mapper,将reader读取的数据进行二次处理
# 将传入的字符串转换为整型并返回
def data_mapper(sample):
data, label = sample # 将sample元组拆分到两个变量
# 拆分句子,将每个编码转换为数字, 并存入一个列表中
val = [int(w) for w in data.split(",")]
return val, int(label) # 返回整数列表,标签(转换成整数)
# 定义reader
def train_reader(train_file_path):
def reader():
with open(train_file_path, "r") as f:
lines = f.readlines() # 读取所有的行
np.random.shuffle(lines) # 打乱所有样本
for line in lines:
data, label = line.split("\t") # 拆分样本到两个变量中
yield data, label
return paddle.reader.xmap_readers(data_mapper, # reader读取的数据进行下一步处理函数
reader, # 读取样本的reader
cpu_count(), # 线程数
1024) # 缓冲区大小
# 读取测试集reader
def test_reader(test_file_path):
def reader():
with open(test_file_path, "r") as f:
lines = f.readlines()
for line in lines:
data, label = line.split("\t")
yield data, label
return paddle.reader.xmap_readers(data_mapper,
reader,
cpu_count(),
1024)
# 定义网络
def CNN_net(data, dict_dim, class_dim=10, emb_dim=128, hid_dim=128, hid_dim2=98):
# embedding(词嵌入层):生成词向量,得到一个新的粘稠的实向量
# 以使用较少的维度,表达更丰富的信息
emb = fluid.layers.embedding(input=data, size=[dict_dim, emb_dim])
# 并列两个卷积、池化层
conv1 = fluid.nets.sequence_conv_pool(input=emb, # 输入,上一个词嵌入层的输出作为输入
num_filters=hid_dim, # 卷积核数量
filter_size=3, # 卷积核大小
act="tanh", # 激活函数
pool_type="sqrt") # 池化类型
conv2 = fluid.nets.sequence_conv_pool(input=emb, # 输入,上一个词嵌入层的输出作为输入
num_filters=hid_dim2, # 卷积核数量
filter_size=4, # 卷积核大小
act="tanh", # 激活函数
pool_type="sqrt") # 池化类型
output = fluid.layers.fc(input=[conv1, conv2], # 输入
size=class_dim, # 输出类别数量
act="softmax") # 激活函数
return output
# 定义模型、训练、评估、保存
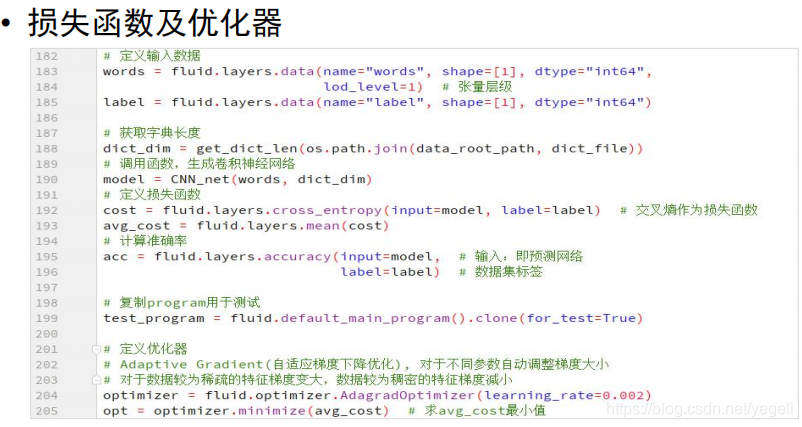
model_save_dir = "model/news_classify/" # 模型保存路径
words = fluid.layers.data(name="words", shape=[1], dtype="int64",
lod_level=1) # 张量层级
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
# 获取字典长度
dict_dim = get_dict_len(dict_file_path)
# 调用函数创建CNN
model = CNN_net(words, dict_dim)
# 定义损失函数
cost = fluid.layers.cross_entropy(input=model, # 预测结果
label=label) # 真实结果
avg_cost = fluid.layers.mean(cost) # 求损失函数均值
# 准确率
acc = fluid.layers.accuracy(input=model, # 预测结果
label=label) # 真实结果
# 克隆program用于模型测试评估
# for_test如果为True,会少一些优化
test_program = fluid.default_main_program().clone(for_test=True)
# 定义优化器
optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.001)
optimizer.minimize(avg_cost)
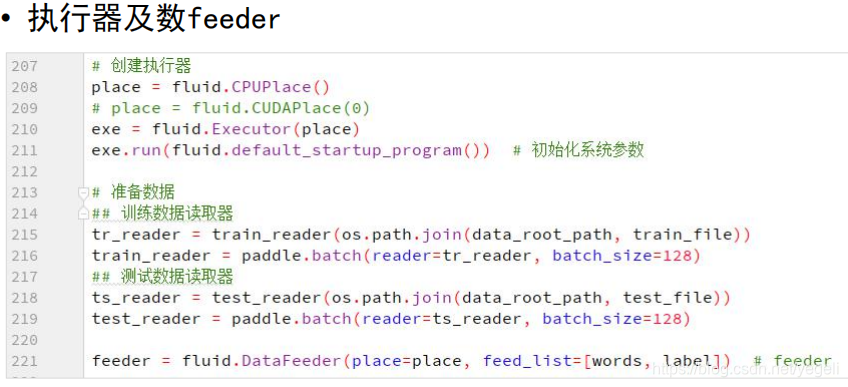
# 定义执行器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
# 准备数据
tr_reader = train_reader(train_file_path)
batch_train_reader = paddle.batch(reader=tr_reader, batch_size=128)
ts_reader = test_reader(test_file_path)
batch_test_reader = paddle.batch(reader=ts_reader, batch_size=128)
feeder = fluid.DataFeeder(place=place, feed_list=[words, label]) # feeder
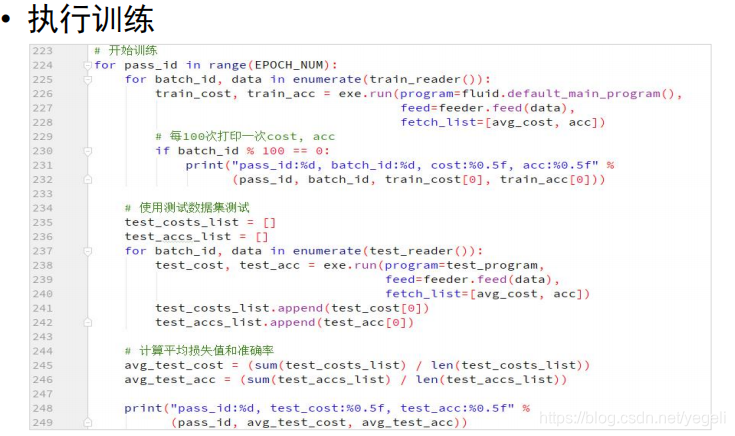
# 开始训练
for pass_id in range(20):
for batch_id, data in enumerate(batch_train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data), # 喂入数据
fetch_list=[avg_cost, acc]) # 要获取的结果
# 打印
if batch_id % 100 == 0:
print("pass_id:%d, batch_id:%d, cost:%f, acc:%f" %
(pass_id, batch_id, train_cost[0], train_acc[0]))
# 每轮次训练完成后,进行模型评估
test_costs_list = [] # 存放所有的损失值
test_accs_list = [] # 存放准确率
for batch_id, data in enumerate(batch_test_reader()): # 读取一个批次测试数据
test_cost, test_acc = exe.run(program=test_program, # 执行test_program
feed=feeder.feed(data), # 喂入测试数据
fetch_list=[avg_cost, acc]) # 要获取的结果
test_costs_list.append(test_cost[0]) # 记录损失值
test_accs_list.append(test_acc[0]) # 记录准确率
# 计算平均准确率和损失值
avg_test_cost = sum(test_costs_list) / len(test_costs_list)
avg_test_acc = sum(test_accs_list) / len(test_accs_list)
print("pass_id:%d, test_cost:%f, test_acc:%f" %
(pass_id, avg_test_cost, avg_test_acc))
# 保存模型
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir, # 模型保存路径
feeded_var_names=[words.name], # 使用模型时需传入的参数
target_vars=[model], # 预测结果
executor=exe) # 执行器
print("模型保存完成.")
3.预测
model_save_dir = "model/news_classify/"
def get_data(sentence):
# 读取字典中的内容
with open(dict_file_path, "r", encoding="utf-8") as f:
dict_txt = eval(f.readlines()[0])
keys = dict_txt.keys()
ret = [] # 编码结果
for s in sentence: # 遍历句子
if not s in keys: # 字不在字典中,取未知字符
s = "<unk>"
ret.append(int(dict_txt[s]))
return ret
# 创建执行器
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
print("加载模型")
infer_program, feeded_var_names, target_var = \
fluid.io.load_inference_model(dirname=model_save_dir, executor=exe)
# 生成测试数据
texts = []
data1 = get_data("在获得诺贝尔文学奖7年之后,莫言15日晚间在山西汾阳贾家庄如是说")
data2 = get_data("综合'今日美国'、《世界日报》等当地媒体报道,芝加哥河滨警察局表示")
data3 = get_data("中国队无缘2020年世界杯")
data4 = get_data("中国人民银行今日发布通知,降低准备金率,预计释放4000亿流动性")
data5 = get_data("10月20日,第六届世界互联网大会正式开幕")
data6 = get_data("同一户型,为什么高层比低层要贵那么多?")
data7 = get_data("揭秘A股周涨5%资金动向:追捧2类股,抛售600亿香饽饽")
data8 = get_data("宋慧乔陷入感染危机,前夫宋仲基不戴口罩露面,身处国外神态轻松")
data9 = get_data("此盆栽花很好养,花美似牡丹,三季开花,南北都能养,很值得栽培")#不属于任何一个类别
texts.append(data1)
texts.append(data2)
texts.append(data3)
texts.append(data4)
texts.append(data5)
texts.append(data6)
texts.append(data7)
texts.append(data8)
texts.append(data9)
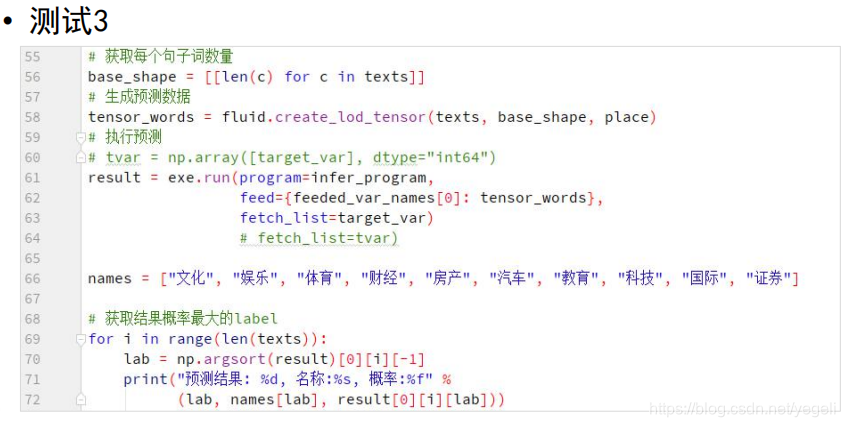
# 获取每个句子词数量
base_shape = [[len(c) for c in texts]]
# 生成数据
tensor_words = fluid.create_lod_tensor(texts, base_shape, place)
# 执行预测
result = exe.run(program=infer_program,
feed={feeded_var_names[0]: tensor_words}, # 待预测的数据
fetch_list=target_var)
# print(result)
names = ["文化", "娱乐", "体育", "财经", "房产", "汽车", "教育", "科技", "国际", "证券"]
# 获取最大值的索引
for i in range(len(texts)):
lab = np.argsort(result)[0][i][-1] # 取出最大值的元素下标
print("预测结果:%d, 名称:%s, 概率:%f" % (lab, names[lab], result[0][i][lab]))
深度学习-08(PaddlePaddle文本分类)的更多相关文章
- 深度学习-06(PaddlePaddle体系结构与基本概念[Tensor、Layer、Program、Variable、Executor、Place]线性回归、波士顿房价预测)
文章目录 深度学习-06(PaddlePaddle基础) paddlePaddle概述 PaddlePaddle简介 什么是PaddlePaddle 为什么学习PaddlePaddle PaddleP ...
- Python深度学习案例2--新闻分类(多分类问题)
本节构建一个网络,将路透社新闻划分为46个互斥的主题,也就是46分类 案例2:新闻分类(多分类问题) 1. 加载数据集 from keras.datasets import reuters (trai ...
- fastText、TextCNN、TextRNN……这里有一套NLP文本分类深度学习方法库供你选择
https://mp.weixin.qq.com/s/_xILvfEMx3URcB-5C8vfTw 这个库的目的是探索用深度学习进行NLP文本分类的方法. 它具有文本分类的各种基准模型,还支持多标签分 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
- 深度学习与NLP简单应用
在深度学习中,文本分类的主要原型:Text label,坐边是输入端“X”,右边是输出端“Y”.行业baseline:用BoW(bag of words)表示sentences(如何将文本表达成一 ...
- 文本分类(六):使用fastText对文本进行分类--小插曲
http://blog.csdn.net/lxg0807/article/details/52960072 环境说明:python2.7.linux 自己打自己脸,目前官方的包只能在linux,mac ...
- NLP文本分类方法汇总
模型: FastText TextCNN TextRNN RCNN 分层注意网络(Hierarchical Attention Network) 具有注意的seq2seq模型(seq2seq with ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
随机推荐
- 2020/5/26-笔记:Oracle数据库表空间的管理
1新建表空间 (1)普通(本地管理)表空间: create tablespace 表空间名 datafile'OS系统文件路径\文件名.dbf' size nM; 或 create tablespac ...
- windows系统,自动设置--shutdown命令了解
参考:https://baike.baidu.com/item/shutdown/10469108?fr=aladdin 比如你的电脑要在24:00关机,可以选择"开始运行",输入 ...
- api加密与校验
一.函数代码 /** * 校验 * @data (请求的数组) * @salt (加密盐) * */ private function verify(array $data, $salt){ $sig ...
- swiper常见问题、动态加载数据问题
swiper加载静态文件是没有问题的 swiper加载动态文件需要在请求后再加载这个函数 参考链接: https://blog.csdn.net/webzrh/article/details/781 ...
- DB2通过java代码生成自定义uuid()函数
一.简单的方法 此种方法在快速大量生成时,会有重复 SELECT concat (hex (RAND ()), hex (RAND ())) as uuid FROM SYSIBM.SYSDUMMY1 ...
- 函数XLOOKUP
这个公式非OFFICE 365用户需要选中执行范围后 按Ctrl+Shift+Enter三键 (因为不支持公式溢出) XLOOKUP函数的基本结构是: =XLOOKUP(lookup_value,lo ...
- flask接口动态注册--依赖于蓝图
# 实现代码 blueprint_d = dict() dirs = os.listdir(base_dir) # 获取apps路径下所有文件夹列表 for d in dirs: ## 1.遍历模块文 ...
- k8s探针
探针是由kubelet对容器执行的定期诊断.要执行诊断,kubelet调用由容器实现的Handler.有三类处理程序: ExecAction:在容器内执行指定命令.如果命令退出时返回码为0认为诊断成功 ...
- 写Java程序有感
最近我练习了Java的学生管理系统的程序代码,多亏了前段时间小学期的系统类练习,让我比较容易地就能够理解该题的题意,再根据我学到的相关的Java知识,就好像是一个套用公式的逻辑. 用到的相关知识: 1 ...
- 全网最详细中英文ChatGPT-GPT-4示例文档-智能编写Python注释文档字符串从0到1快速入门——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)
目录 Introduce 简介 setting 设置 Prompt 提示 Sample response 回复样本 API request 接口请求 python接口请求示例 node.js接口请求示 ...