Flink Table API & SQL 自定义Redis Sink 代码实现
在自定义source&sink这一块官方给的说明并不是很多,需要去看源代码熟悉,自己实现一个redis sink主要需要实现StreamTableSinkFactory,RichSinkFunction和AppendStreamTableSink/RetractStreamTableSink/UpsertStreamTableSink,代码逻辑依赖主要如下
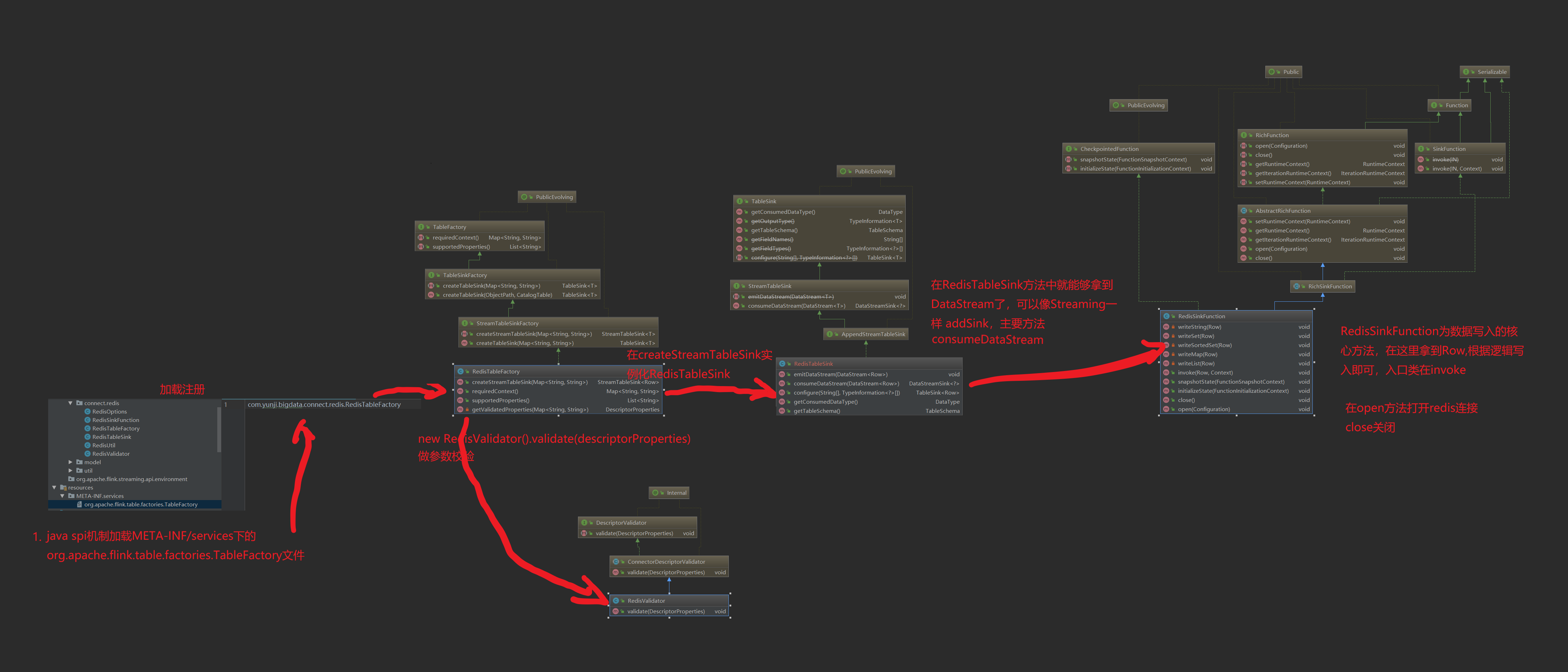
1.定义TableFactory
定义一个TableSinkFactory需要实现以下一个或者多个接口,在这里只实现StreamTableSinkFactory
- BatchTableSourceFactory: Creates a batch table source.
- BatchTableSinkFactory: Creates a batch table sink.
- StreamTableSourceFactory: Creates a stream table source.
- StreamTableSinkFactory: Creates a stream table sink.
- DeserializationSchemaFactory: Creates a deserialization schema format.
- SerializationSchemaFactory: Creates a serialization schema forma
createStreamTableSink():在这里能够拿到ddl的with参数,我们通过getValidatedProperties进行合法性校验,再将参数构建为一个RedisOptions供后续方法使用,tableSchema主要包含ddl语句字段信息,最后返回实例化的RedisTableSink
requiredContext():指定已为此工厂实现的上下文。该框架保证仅在满足指定的属性和值集的情况下才与此工厂匹配。典型的属性可能是connector.type,format.type或update-mode。 为将来的向后兼容情况保留了诸如connect.property-version和format.property-version之类的属性键。
supportedProperties():此工厂可以处理的属性键的列表。此方法将用于验证。如果传递了该工厂无法处理的属性,则将引发异常。该列表不得包含上下文指定的键。
getValidatedProperties():构建DescriptorProperties并作合法性校验
2.定义TableSink
定义一个TableSink可以实现BatchTableSink、RetractStreamTableSink、UpsertStreamTableSink或者AppendStreamTableSink,redis的数据写入,我们按照来一条写一条的思路来实现,不涉及到数据的删除,所以只需要继承AppendStreamTableSink
consumeDataStream():在这里能够拿到数据流,在addSink的时候将实例化的RedisSinkFunction写入方法传进去即可
emitDataStream():已经废弃
configure():拿到的是sql返回字段和类型,在这里我们和tableSchema做一致性校验,必须完全对应才能通过
getConsumedDataType():返回Consumed数据类型
getTableSchema():返回tableSchema信息
3.定义RedisSinkFunction
定义RedisSinkFunction需要继承RichSinkFunction,如果需要在Checkpoint时候做一些事情还可以实现CheckpointedFunction
open():可以在这里构建jedis方法
close():在这里执行销毁或者关闭方法
invoke():数据写入的执行方法,我们这里根据ddl的connector.data.type类型来确定调用的方法,目前先实现了string,set,list,map,sortedset五种
snapshotState():如果是mysql或者hbase那种定时/定量写入方式,可以在这里调用写入方法
4.创建java spi发现目录和文件
在resources目录下创建META-INF/services文件夹,创建一个名为org.apache.flink.table.factories.TableFactory的文件,将com.bigdata.connect.redis.RedisTableFactory写入,如果还有自定义的其他source/sink也一起写在这里
5.打包发布
注意打包的时候一定要确认把com.bigdata.connect.redis.RedisTableFactory打进去了,最好打包完反编译一下看时候被覆盖。我使用maven-assembly-plugin打包就会出现被覆盖的问题,后面改为maven-shade-plugin打包就没问题,所以一定要检查下。
6.遇到的问题
org.apache.flink.table.api.TableException: Table sink does not implement a table schema.
在RedisTableSink中忘记重写getTableSchema方法
org.apache.flink.table.api.TableException: Table sink does not implement a consumed data type.
在RedisTableSink中忘记重写getConsumedDataType方法
org.apache.flink.api.common.InvalidProgramException: root
|-- pay_hour: STRING
|-- item_id: STRING
is not serializable. The object probably contains or references non serializable fields.
在RedisTableSink的emitDataStream方法中将tableSchema传到RedisSinkFunction方法中去,而TableSchema未实现Serializable,出现序列化的问题
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: The StreamTableSink#consumeDataStream(DataStream) must be implemented and return the sink transformation DataStreamSink. However, com.bigdata.connect.redis.RedisTableSink doesn't implement this method.
使用了废弃的emitDataStream方法,而且没有重写consumeDataStream
7.使用方式
sink使用方法:
参考文档
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sourceSinks.html
Flink Table API & SQL 自定义Redis Sink 代码实现的更多相关文章
- 【翻译】Flink Table Api & SQL — 自定义 Source & Sink
本文翻译自官网: User-defined Sources & Sinks https://ci.apache.org/projects/flink/flink-docs-release-1 ...
- Flink Table Api & SQL 翻译目录
Flink 官网 Table Api & SQL 相关文档的翻译终于完成,这里整理一个安装官网目录顺序一样的目录 [翻译]Flink Table Api & SQL —— Overv ...
- 【翻译】Flink Table Api & SQL — SQL客户端Beta 版
本文翻译自官网:SQL Client Beta https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/sqlCl ...
- 【翻译】Flink Table Api & SQL —— 概念与通用API
本文翻译自官网:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/common.html Flink Tabl ...
- 【翻译】Flink Table Api & SQL —— 连接到外部系统
本文翻译自官网:Connect to External Systems https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev ...
- 【翻译】Flink Table Api & SQL — SQL
本文翻译自官网:SQL https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/sql.html Flink Tab ...
- 【翻译】Flink Table Api & SQL — Hive —— Hive 函数
本文翻译自官网:Hive Functions https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/hive/h ...
- 【翻译】Flink Table Api & SQL —— Overview
本文翻译自官网:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/ Flink Table Api & ...
- 【翻译】Flink Table Api & SQL —— 数据类型
本文翻译自官网:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/types.html Flink Table ...
- 【翻译】Flink Table Api & SQL —Streaming 概念 ——在持续查询中 Join
本文翻译自官网 : Joins in Continuous Queries https://ci.apache.org/projects/flink/flink-docs-release-1.9 ...
随机推荐
- 【学习笔记】XR872 GUI Littlevgl 8.0 移植(文件系统)
不得不提 在移植的过程中,发现 LVGL 的文件操作接口并不十分完善,在我看来, LVGL 的文件操作接口,应该更多的是为了 LVGL 内部接口方便读取资源文件而设立的,例如读取图像文件,加载字库文件 ...
- 阿里百秀后台管理项目笔记 ---- Day04
来吧展示: step 1 : 实现评论管理数据渲染 利用 ajax 创建接口得到数据使用模板引擎渲染页面 1.1 引入文件 <script src="/static/assets/ve ...
- 11月9日内容总结——单例模式的多种实现方式、pickle序列号模块和选课系统
目录 一.单例模式实现的多种方式 方式一:使用类 方法二:使用metaclass方式(自定义元类) 方法三:自定义双下new 方法四:基于模块的单例模式 二.pickle序列化模块 优势: 缺陷: 方 ...
- Nginx01 简介和安装
1 简介 Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务.Nginx是由伊戈尔·赛索耶夫为俄罗斯访问量第二的Rambler ...
- echarts入门到应用学习笔记
背景: 做疫情数据管理可视化,需要用到热点图在web端进行数据可视化,而地图就是必不可少的一个,看完文档,可以解决大部分小白的问题,保姆级攻略,即使你的js,这些学得不咋样(我就是小菜鸟) 步骤 环境 ...
- Fiegn 声明式接口调用
五:Fiegn 声明式接口调用 什么是Fiegn Netfix,Fiegn 是一个提供模板式的Web Service客户端,使用Fiegn 可以简化Web Service 客户端的编写,开发者可以通过 ...
- 记一次 .NET 某医保平台 CPU 爆高分析
一:背景 1. 讲故事 一直在追这个系列的朋友应该能感受到,我给这个行业中无数的陌生人分析过各种dump,终于在上周有位老同学找到我,还是个大妹子,必须有求必应 . 妹子公司的系统最近在某次升级之后, ...
- 三天吃透MySQL八股文(2023最新整理)
本文已经收录到Github仓库,该仓库包含计算机基础.Java基础.多线程.JVM.数据库.Redis.Spring.Mybatis.SpringMVC.SpringBoot.分布式.微服务.设计模式 ...
- 第一个webpack例子demo1
1.运行webpack 在当前目录 管理员CMD下运行命令 : webpack PS: 只有安装webpack时才必须在管理员环境下运行,如今使用可以随便 问题1: 运行中会遇报错: 错误分析:HTM ...
- PostgreSQL 并行计算算法,参数,强制并行度设置
一.优化器并行计算的并行度计算方法 1.总worker进程数 postgres=# show ; max_worker_processes ---------------------- 128 (1 ...