带你了解NLP的词嵌入
摘要:今天带领大家学习自然语言处理中的词嵌入的内容。
本文分享自华为云社区《【MindSpore易点通】深度学习系列-词嵌入》,作者:Skytier。
1 特征表示
在自然语言处理中,有一个很关键的概念是词嵌入,这是语言表示的一种方式,可以让算法自动的理解一些同类别的词,比如苹果、橘子,比如袜子、手套。
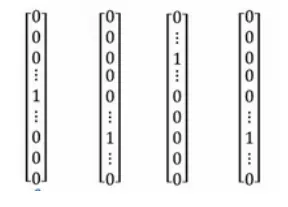
one-hot向量
比如我们通常会说:“I want a glass of orange juice.”但如果算法并不知道apple和orange的类似性(这两个one-hot向量的内积是0),那么当其遇到“I want a glass of apple __”时,并不知道这里也应该填写 juice。
如果用特征化的表示来表示库里的每个词,学习它们的特征或者数值。
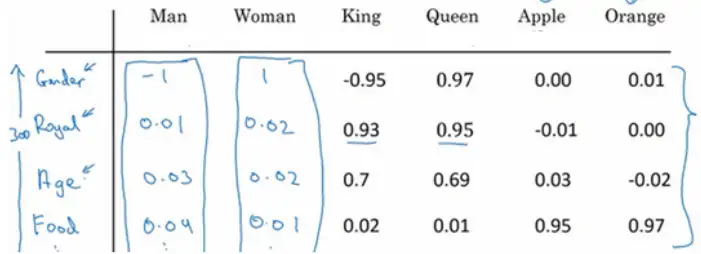

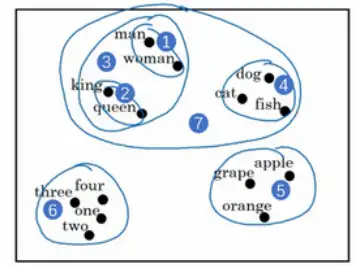
这样我们就可以选用t-SNE算法来对特征向量可视化,通过观察这种词嵌入的表示方法,最终同类别的单词会聚集在一块,词嵌入算法对于相近的概念,学到的特征也比较类似。
2 词嵌入的使用
参考案例——句中找人名:Jack Li is a teacher.
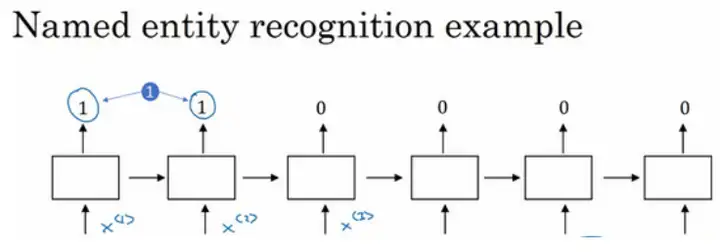
使用词嵌入作为输入训练好的模型,如果看到一个新的输入:“Jack Li is a farmer.”因为知道teacher和farmer很相近,那么算法很容易就知道Jack Li是一个人的名字。同时,如果遇到不太常见的单词,比如:Jack Li is a cultivator.(假设训练集里没有cultivator这个单词),但是词嵌入的算法通过考察大量的无标签文本,会发现farmer、teacher、cultivator相近,把它们都聚集在一块。这样一来即使只有一个很小的训练集,但是使用迁移学习,把从大量的无标签文本中学习到的知识迁移到一个任务中——比如少量标记的训练数据集的命名实体识别任务。
如何用词嵌入做迁移学习的步骤:
1.先从大量的文本集中学习词嵌入。
2.用这些词嵌入模型把它迁移到新的只有少量标注训练集的任务中,比如说用300维的词嵌入来表示单词,这样就可以用更低维度的特征向量代替原来的10000维的one-hot向量。
3.当在新的任务上训练模型时,只有少量的标记数据集,可以选择不进行微调,而是用新的数据调整词嵌入。
当你的任务的训练集相对较小时,词嵌入的作用最明显,所以它广泛用于NLP领域,但是其对于一些语言模型和机器翻译并不适用。
3 类比推理
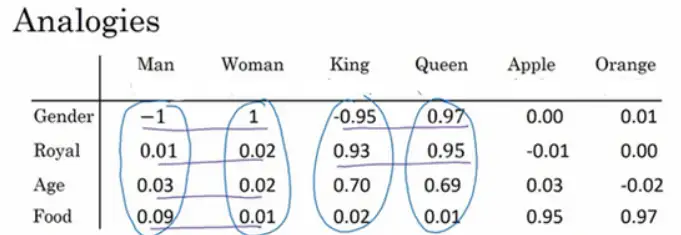
词嵌入有一个非常强大的特性就是可以帮助实现类比推理。比如从性别这个特征上来说,如果man应该对应woman,那么算法可以推导出king对应queen。



最常用的相似度函数是余弦相似度,假如在向量u和v之间定义相似度:
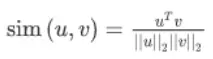
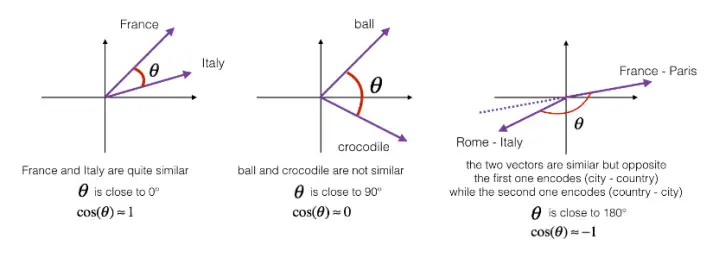
如果u和v非常相似,那么它们的内积将会很大,那么该式就是u和v的夹角Φ的余弦值,实际就是计算两向量夹角Φ角的余弦。夹角为0度时,余弦相似度就是1,当夹角是90度角时余弦相似度就是0,当夹角是180度时相似度等于-1,因此角度越小,两个向量越相似。
带你了解NLP的词嵌入的更多相关文章
- DLNg序列模型第二周NLP与词嵌入
1.使用词嵌入 给了一个命名实体识别的例子,如果两句分别是“orange farmer”和“apple farmer”,由于两种都是比较常见的,那么可以判断主语为人名. 但是如果是榴莲种植员可能就无法 ...
- NLP领域的ImageNet时代到来:词嵌入「已死」,语言模型当立
http://3g.163.com/all/article/DM995J240511AQHO.html 选自the Gradient 作者:Sebastian Ruder 机器之心编译 计算机视觉领域 ...
- Coursera Deep Learning笔记 序列模型(二)NLP & Word Embeddings(自然语言处理与词嵌入)
参考 1. Word Representation 之前介绍用词汇表表示单词,使用one-hot 向量表示词,缺点:它使每个词孤立起来,使得算法对相关词的泛化能力不强. 从上图可以看出相似的单词分布距 ...
- NLP之基于词嵌入(WordVec)的嵌入矩阵生成并可视化
词嵌入 @ 目录 词嵌入 1.理论 1.1 为什么使用词嵌入? 1.2 词嵌入的类比推理 1.3 学习词嵌入 1.4 Word2Vec & Skip-Gram(跳字模型) 1.5 分级& ...
- NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类(paper: ...
- 斯坦福NLP课程 | 第12讲 - NLP子词模型
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- cips2016+学习笔记︱简述常见的语言表示模型(词嵌入、句表示、篇章表示)
在cips2016出来之前,笔者也总结过种类繁多,类似词向量的内容,自然语言处理︱简述四大类文本分析中的"词向量"(文本词特征提取)事实证明,笔者当时所写的基本跟CIPS2016一 ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
随机推荐
- HCNP Routing&Switching之端口安全
前文我们了解了二层MAC安全相关话题和配置,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16618201.html:今天我们来聊一聊mac安全的综合解决方案端 ...
- 第七十五篇:Vue兄弟组件传值
好家伙, 兄弟组件的传值用到Eventbus组件, 1.EventBus的使用步骤 ① 创建 eventBus.js 模块,并向外共享一个Vue的实例对象 ②在数据发送方, 调用bus.$emit(' ...
- 03_Linux基础-文件类型-主辅提示符-第1提示符-Linux命令-内外部命令-快捷键-改为英文编码-3个时间-stat-其他基础命令
03_Linux基础-文件类型-主辅提示符-第1提示符-Linux命令-内外部命令-快捷键-改为英文编码-3个时间-stat-{1..100}-du-cd-cp-file-mv-echo-id-she ...
- SpringMVC 06: 日期类型的变量的注入和显示
日期处理和日期显示 日期处理 此时SpringMVC的项目配置和SpringMVC博客集中(指SpringMVC 02)配置相同 日期处理分为单个日期处理和类中全局日期处理 单个日期处理: 使用@Da ...
- alter role 导致的数据库无法登录问题
ALTER ROLE 用于更改一个数据库角色.只要改角色后续开始一个新会话,指定的值将会成为该会话的默认值,并且会覆盖 kingbase.conf中存在的值或者从命令行收到的值. 显性的更改角色的一 ...
- Cluster table 与性能
用户数据行存储在文件系统中的堆文件中,而这些行以不确定的顺序存储.如果表最初以插入/复制的顺序加载,那么以后的插入.更新和删除将导致在堆文件中以不可预测的顺序添加行.创建索引创建一个指向堆行的辅助文件 ...
- springMVC配置时,静态资源和jsp文件路径没错但是访问时controller的请求报404错误。
springMVC配置时,静态资源和jsp文件路径没错但是访问时controller的请求报404错误. 1.场景 如果在web.xml中servlet-mapping的url-pattern设置的是 ...
- Docker(一):初识
1.什么是Docker Docker 是一个基于Go 语言并遵从Apache2.0协议开源的.轻量级的容器引擎,主要运行于 Linux 和 Windows,用于创建.管理和编排容器.可以让开发者打 ...
- phpoffice文档笔记
目录 phpword html转word phpexcel 从数据库导出 phpword html转word <?php namespace app\index\controller; use ...
- 记录一下对jdk8后的接口的一些理解
对于jdk8后的接口,接口中加入了可以定义默认方法和静态方法. 为什么要这样设计呢? 是为了在给接口扩展方法的时候,不会影响已经实现了该接口的类 加入默认方法可以解决:在添加方法的同时,不影响现有的实 ...