从HDFS的写入和读取中,我发现了点东西
摘要:从HDFS的写入和读取中,我们能学习到什么?
本文分享自华为云社区《从HDFS的写入和读取中,我们能学习到什么》,作者: breakDawn 。
最近开发过程涉及了一些和文件读取有关的问题,于是对hdfs的读取机制感到兴趣,顺便深入学习了一下。
写入
- 客户端向NameNode发出写文件请求,告诉需要写的文件名和路径、用户
- NameNode检查是否已存在文件、检查权限。如果通过,会返回一个输出流对象
- 注意此时会按照“日志先行“原则,写入NameNode的editLog
- 客户端按照128MB的大小切分文件。 也就是block大小
- 客户端把nameNode传来的DataNode列表和Data数据一同发送给 最近的第一个DataNode节点。
- 第一个dataNode节点收到数据和DataNode列表时, 会先根据列表,找到下一个自己要连接的最近DataNode, 删除自己后,再一样往下发。以此类推,发完3台或者N台。
- 传输单位是packet,包,比block小一点。
- dataNode每写完一个block块, 则返回ACK信息给上一个节点进行确认。(注意是写完block才确认)
- 写完数据, 关闭输出流, 发送完成信息给DataNode
写过程的核心总结:
- 客户端只向一个dataNode写数据,然后下一个dataNode接着往另一个dataNode写,串联起来。
- 按128MB分block。 每次传数据按pack传。 校验按照chunk 校验,每次chunk都会写入pack。
- 写完block才发ACK确认。
Q: NameNode的editlog有什么用?怎么起作用的?
A:作用:
- 硬盘中需要有一份元数据的镜像——FSImage
- 每次要修改元数据就信息时,必须得改文件(hdfs没有数据库)
- 可能会比较久,改的时候如果断电了,就丢失这个操作了
为了避免丢失,引入editlog,每次修改元数据前,先追加方式写入editlog, 然后再处理,这样即使断电了也能修复。
一般都是那些更改操作有断开风险,为了确保能恢复,都会引入这类操作。
Q: 什么时候发送完成信号? 全部节点都写入完成吗
A:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性
Q: 怎么验证写入时的数据完整性?
A:
- 因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个packet最终形成block,故可在block上求校验和。
- 当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。就是.meta文件
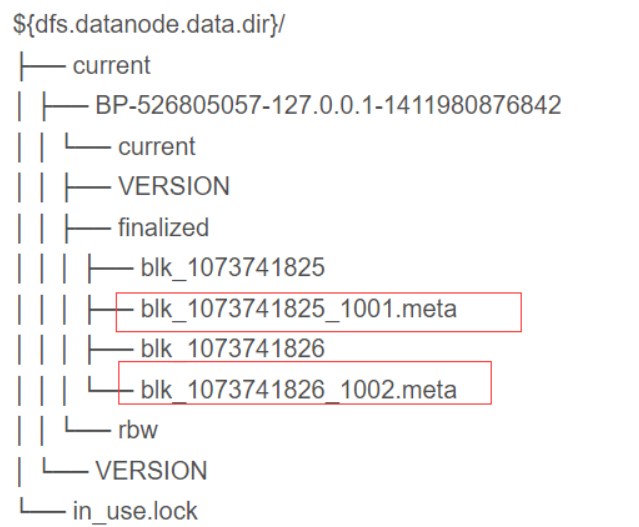
- 当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
Q: 写入时怎么确定最近节点?
A:按照按照hadoop时设置的机架、数据中心、节点来估算
假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
- Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
- Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
- Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
- Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)
读取
读取就比较简单了,没有那种复杂的串行过程。NameNode直接告诉客户端去哪读就行了。
- client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 就近挑选一台datanode服务器,请求建立输入流 。
- DataNode向输入流中中写数据,以packet为单位来校验。
- 关闭输入流
从HDFS的写入和读取中,我发现了点东西的更多相关文章
- HDFS 03 - 你能说说 HDFS 的写入和读取过程吗?
目录 1 - HDFS 文件的写入 1.1 写入过程 1.2 写入异常时的处理 1.3 写入的一致性 2 - HDFS 文件的读取 2.1 读取过程 2.2 读取异常时的处理 版权声明 1 - HDF ...
- HDFS写入和读取流程
HDFS写入和读取流程 一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而 ...
- HDFS数据流-剖析文件读取及写入
HDFS数据流-剖析文件读取及写入 文件读取 1. 客户端通过调用FileSystem对象的open方法来打开希望读取的文件,对于HDFS来说,这个对象是分布式文件系统的一个实例.2. Distrib ...
- iOS中plist的创建,数据写入与读取
iOS中plist的创建,数据写入与读取 Documents:应用将数据存储在Documents中,但基于NSuserDefaults的首选项设置除外Library:基于NSUserDefaults的 ...
- 蜗牛爱课- iOS中plist的创建,数据写入与读取
iOS中plist的创建,数据写入与读取功能创建一个test.plist文件-(void)triggerStorage{ NSArray *paths=NSSearchPathForDirect ...
- Java 实现Excel表数据的读取和写入 以及过程中可能遇到的问题
问题1:Unable to recognize OLE stream 格式的问题要可能是因为给的数据是2010年的数据表后缀为.xlsx,要先转化成2003版的后缀为.xls 问题2: Warning ...
- [转]VC++中对文件的写入和读取
本文转自:http://blog.csdn.net/fanghb_1984/article/details/7425705 本文介绍两种方法对文件进行读取和写入操作:1.采用fstream类:2.采用 ...
- 在C#程序中,创建、写入、读取XML文件的方法
一.在C#程序中,创建.写入.读取XML文件的方法 1.创建和读取XML文件的方法,Values为需要写入的值 private void WriteXML(string Values) { //保存的 ...
- ResquestInfoServlet类通过访问HttpServletRequest对象的各种方法来读取HTTP请求中的特定信息,并且把它们写入到HTML中
ResquestInfoServlet类通过访问HttpServletRequest对象的各种方法来读取HTTP请求中的特定信息,并且把它们写入到HTML中 ResquestInfoServlet.j ...
随机推荐
- Wi-Fi DFS与TPC介绍
DFS与TPC是wifi认证的其中一项测试内容,如果不需要DFS功能,可以不进行测试,但是某些属于DFS频段的wifi信道则不允许使用. 1. 什么是WIFI Auto DFS? 通俗的说就是:躲雷达 ...
- 【第一期百题计划进行中,快来打卡学习】吃透java、细化到知识点的练习题及笔试题,助你轻松搞定java
[快来免费打卡学习]参与方式 本期百题计划开始时间:2022-02-09,今日打卡题已在文中标红. 0.本文文末评论区打卡,需要登录才可以打卡以及查看其他人的打卡记录 1.以下练习题,请用对应的知识点 ...
- wmware15安装centos7.9
详细步骤如下: 下面位置应该写:D:\k8s\k8s-master01 也可以桥接 下面可以删除 从官方下载的,不需要test,所以选择第一个 默认英文的即可 改为上海 保持默认 配置静态ip 主机名 ...
- JS 逻辑运算符的特点
致谢 首先说一下,其他数据类型转换为布尔类型的规则: null.undefined.0.NaN.空字符串转换为false,其他转化为 true. 1. 取反 ! 首先把数据转化为布尔值,然后取反,结果 ...
- RFC3918组播组容量测试——网络测试仪实操
一.简介 1.RFC3918简介 历史 · 在1999年3月成为正式标准 功能 · 评测网络互连设备或网络系统的性能 · 网络设备: 交换机,路由器- 内容 · 定义了一整套测试方法,为不同厂家的设备 ...
- 从这3个方面考虑BI工具,选型一选一个准
BI工具在很多场合都能听到,那么BI工具有什么功能呢?能给企业带来什么?好用的BI工具长什么样?今天跟着小编走近BI工具,一探究竟! 首先要了解BI工具的定义,什么是BI工具.BI工具是指利用现代数据 ...
- BI平台能做什么,有哪些功能呢?
相信接触过数据分析工作的小伙伴们,对BI平台并不陌生.BI(Business Intelligence),也就是商业智能,它是一个完整的解决方案,可以有效地整合企业中的现有数据.BI通常被理解为将企 ...
- 字符串压缩(一)之ZSTD
前言 最近项目上有大量的字符串数据需要存储到内存,并且需要储存至一定时间,于是自然而然的想到了使用字符串压缩算法对"源串"进行压缩存储.由此触发了对一些优秀压缩算法的调研. 字符串 ...
- 在 Linux 下确认 NTP 是否同步的方法
NTP 意即网络时间协议Network Time Protocol,它通过网络同步计算机系统之间的时钟.NTP 服务器可以使组织中的所有服务器保持同步,以准确时间执行基于时间的作业.NTP 客户端会将 ...
- Java笔记——循环语句
Java笔记--循环语句 1. while语句 规律: 1. 首先计算表达式的值. 2. 若表达式为真,则执行循环语法,直至表达式为假,循环结束. while(表达式) 语句; 例如: i ...