[机器学习] PCA主成分分析原理分析和Matlab实现方法
转载于http://blog.csdn.net/guyuealian/article/details/68487833
网上关于PCA(主成分分析)原理和分析的博客很多,本博客并不打算长篇大论推论PCA理论,而是用最精简的语言说明鄙人对PCA的理解,并在最后给出用Matlab计算PCA过程的三种方法,方便大家对PCA的理解。
一、PCA原理简要说明
PCA算法主要用于降维,就是将样本数据从高维空间投影到低维空间中,并尽可能的在低维空间中表示原始数据。PCA的几何意义可简单解释为:
0维-PCA:将所有样本信息都投影到一个点,因此无法反应样本之间的差异;要想用一个点来尽可能的表示所有样本数据,则这个点必定是样本的均值。
1维-PCA:相当于将所有样本信息向样本均值的直线投影;
2维-PCA:将样本的平面分布看作椭圆形分布,求出椭圆形的长短轴方向,然后将样本信息投影到这两条长短轴方向上,就是二维PCA。(投影方向就是平面上椭圆的长短轴方向);
3维-PCA:样本的平面分布看作椭圆形分布,投影方法分别是椭圆球的赤道半径a和b,以及是极半径c(沿着z轴);
PCA简而言之就是根据输入数据的分布给输入数据重新找到更能描述这组数据的正交的坐标轴,比如下面一幅图,对于那个椭圆状的分布,最方便表示这个分布的坐标轴肯定是椭圆的长轴短轴而不是原来的x ,y轴。
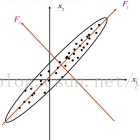
那么如何求出这个长轴和短轴呢?于是线性代数就来了:我们需要先求出这堆样本数据的协方差矩阵,然后再求出这个协方差矩阵的特征值和特征向量,对应最大特征值的那个特征向量的方向就是长轴(也就是主元)的方向,次大特征值的就是第二主元的方向,以此类推。
二、PCA实现方法
(1)方法一:[COEFF SCORE latent]=princomp(X)
参数说明:
1)COEFF 是主成分分量,即样本协方差矩阵的特征向量;
2)SCORE主成分,是样本X在低维空间的表示形式,即样本X在主成份分量COEFF上的投影 ,若需要降k维,则只需要取前k列主成分分量即可
3)latent:一个包含样本协方差矩阵特征值的向量;
- %% 样本矩阵X,有8个样本,每个样本有4个特征,使用PCA降维提取k个主要特征(k<4)
- k=2; %将样本降到k维参数设置
- X=[1 2 1 1; %样本矩阵
- 3 3 1 2;
- 3 5 4 3;
- 5 4 5 4;
- 5 6 1 5;
- 6 5 2 6;
- 8 7 1 2;
- 9 8 3 7]
- %% 使用Matlab工具箱princomp函数实现PCA
- [COEFF SCORE latent]=princomp(X)
- pcaData1=SCORE(:,1:k) %取前k个主成分
%% 样本矩阵X,有8个样本,每个样本有4个特征,使用PCA降维提取k个主要特征(k<4)
k=2; %将样本降到k维参数设置
X=[1 2 1 1; %样本矩阵
3 3 1 2;
3 5 4 3;
5 4 5 4;
5 6 1 5;
6 5 2 6;
8 7 1 2;
9 8 3 7]
%% 使用Matlab工具箱princomp函数实现PCA
[COEFF SCORE latent]=princomp(X)
pcaData1=SCORE(:,1:k) %取前k个主成分运行结果:
- X =
- 1 2 1 1
- 3 3 1 2
- 3 5 4 3
- 5 4 5 4
- 5 6 1 5
- 6 5 2 6
- 8 7 1 2
- 9 8 3 7
- COEFF =
- 0.7084 -0.2826 -0.2766 -0.5846
- 0.5157 -0.2114 -0.1776 0.8111
- 0.0894 0.7882 -0.6086 0.0153
- 0.4735 0.5041 0.7222 -0.0116
- SCORE =
- -5.7947 -0.6071 0.4140 -0.0823
- -3.3886 -0.8795 0.4054 -0.4519
- -1.6155 1.5665 -1.0535 1.2047
- -0.1513 2.5051 -1.3157 -0.7718
- 0.9958 -0.5665 1.4859 0.7775
- 1.7515 0.6546 1.5004 -0.6144
- 2.2162 -3.1381 -1.6879 -0.1305
- 5.9867 0.4650 0.2514 0.0689
- latent =
- 13.2151
- 2.9550
- 1.5069
- 0.4660
- pcaData1 =
- -5.7947 -0.6071
- -3.3886 -0.8795
- -1.6155 1.5665
- -0.1513 2.5051
- 0.9958 -0.5665
- 1.7515 0.6546
- 2.2162 -3.1381
- 5.9867 0.4650
X =
1 2 1 1
3 3 1 2
3 5 4 3
5 4 5 4
5 6 1 5
6 5 2 6
8 7 1 2
9 8 3 7
COEFF =
0.7084 -0.2826 -0.2766 -0.5846
0.5157 -0.2114 -0.1776 0.8111
0.0894 0.7882 -0.6086 0.0153
0.4735 0.5041 0.7222 -0.0116
SCORE =
-5.7947 -0.6071 0.4140 -0.0823
-3.3886 -0.8795 0.4054 -0.4519
-1.6155 1.5665 -1.0535 1.2047
-0.1513 2.5051 -1.3157 -0.7718
0.9958 -0.5665 1.4859 0.7775
1.7515 0.6546 1.5004 -0.6144
2.2162 -3.1381 -1.6879 -0.1305
5.9867 0.4650 0.2514 0.0689
latent =
13.2151
2.9550
1.5069
0.4660
pcaData1 =
-5.7947 -0.6071
-3.3886 -0.8795
-1.6155 1.5665
-0.1513 2.5051
0.9958 -0.5665
1.7515 0.6546
2.2162 -3.1381
5.9867 0.4650(2)方法二:自己编程实现
PCA的算法过程,用一句话来说,就是“将所有样本X减去样本均值m,再乘以样本的协方差矩阵C的特征向量V,即为PCA主成分分析”,其计算过程如下:
[1].将原始数据按行组成m行n列样本矩阵X(每行一个样本,每列为一维特征)
[2].求出样本X的协方差矩阵C和样本均值m;(Matlab可使用cov()函数求样本的协方差矩阵C,均值用mean函数)
[3].求出协方差矩阵的特征值D及对应的特征向量V;(Matlab可使用eigs()函数求矩阵的特征值D和特征向量V)
[4].将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P;(eigs()返回特征值构成的向量本身就是从大到小排序的)
[5].Y=(X-m)×P即为降维到k维后的数据;
- %% 自己实现PCA的方法
- [Row Col]=size(X);
- covX=cov(X); %求样本的协方差矩阵(散步矩阵除以(n-1)即为协方差矩阵)
- [V D]=eigs(covX); %求协方差矩阵的特征值D和特征向量V
- meanX=mean(X); %样本均值m
- %所有样本X减去样本均值m,再乘以协方差矩阵(散步矩阵)的特征向量V,即为样本的主成份SCORE
- tempX= repmat(meanX,Row,1);
- SCORE2=(X-tempX)*V %主成份:SCORE
- pcaData2=SCORE2(:,1:k)
%% 自己实现PCA的方法
[Row Col]=size(X);
covX=cov(X); %求样本的协方差矩阵(散步矩阵除以(n-1)即为协方差矩阵)
[V D]=eigs(covX); %求协方差矩阵的特征值D和特征向量V
meanX=mean(X); %样本均值m
%所有样本X减去样本均值m,再乘以协方差矩阵(散步矩阵)的特征向量V,即为样本的主成份SCORE
tempX= repmat(meanX,Row,1);
SCORE2=(X-tempX)*V %主成份:SCORE
pcaData2=SCORE2(:,1:k)- SCORE2 =
- -5.7947 0.6071 -0.4140 0.0823
- -3.3886 0.8795 -0.4054 0.4519
- -1.6155 -1.5665 1.0535 -1.2047
- -0.1513 -2.5051 1.3157 0.7718
- 0.9958 0.5665 -1.4859 -0.7775
- 1.7515 -0.6546 -1.5004 0.6144
- 2.2162 3.1381 1.6879 0.1305
- 5.9867 -0.4650 -0.2514 -0.0689
- pcaData2 =
- -5.7947 0.6071
- -3.3886 0.8795
- -1.6155 -1.5665
- -0.1513 -2.5051
- 0.9958 0.5665
- 1.7515 -0.6546
- 2.2162 3.1381
- 5.9867 -0.4650
SCORE2 =
-5.7947 0.6071 -0.4140 0.0823
-3.3886 0.8795 -0.4054 0.4519
-1.6155 -1.5665 1.0535 -1.2047
-0.1513 -2.5051 1.3157 0.7718
0.9958 0.5665 -1.4859 -0.7775
1.7515 -0.6546 -1.5004 0.6144
2.2162 3.1381 1.6879 0.1305
5.9867 -0.4650 -0.2514 -0.0689
pcaData2 =
-5.7947 0.6071
-3.3886 0.8795
-1.6155 -1.5665
-0.1513 -2.5051
0.9958 0.5665
1.7515 -0.6546
2.2162 3.1381
5.9867 -0.4650
对比方法一和方法可知,主成份分量SCORE和SCORE2的绝对值是一样的(符号只是相反方向投影而已,不影响分析结果),其中pcaData是从SCORE提取前2列的数据,这pcaData就是PCA从4维降到2维空间的数据表示形式,pcaData可以理解为:通过PCA降维,每个样本可以用2个特征来表示原来4个特征了。
(3)方法三:使用快速PCA方法
fastPCA函数用来对样本矩阵A进行快速主成分分析和降维(降至k维),其输出pcaA为维后的k维样本特征向量组成的矩阵,每行一个样本,列数k为降维后的样本特征维数,相当于princomp函数中的输出SCORE, 而输出V为主成分分量,相当于princomp函数中的输出COEFF。
- %% 使用快速PCA算法实现的方法
- [pcaData3 COEFF3] = fastPCA(X, k )
%% 使用快速PCA算法实现的方法
[pcaData3 COEFF3] = fastPCA(X, k )其中fastPCA函数的代码实现如下:
- function [pcaA V] = fastPCA( A, k )
- % 快速PCA
- % 输入:A --- 样本矩阵,每行为一个样本
- % k --- 降维至 k 维
- % 输出:pcaA --- 降维后的 k 维样本特征向量组成的矩阵,每行一个样本,列数 k 为降维后的样本特征维数
- % V --- 主成分向量
- [r c] = size(A);
- % 样本均值
- meanVec = mean(A);
- % 计算协方差矩阵的转置 covMatT
- Z = (A-repmat(meanVec, r, 1));
- covMatT = Z * Z';
- % 计算 covMatT 的前 k 个本征值和本征向量
- [V D] = eigs(covMatT, k);
- % 得到协方差矩阵 (covMatT)' 的本征向量
- V = Z' * V;
- % 本征向量归一化为单位本征向量
- for i=1:k
- V(:,i)=V(:,i)/norm(V(:,i));
- end
- % 线性变换(投影)降维至 k 维
- pcaA = Z * V;
- % 保存变换矩阵 V 和变换原点 meanVec
function [pcaA V] = fastPCA( A, k )
% 快速PCA
% 输入:A --- 样本矩阵,每行为一个样本
% k --- 降维至 k 维
% 输出:pcaA --- 降维后的 k 维样本特征向量组成的矩阵,每行一个样本,列数 k 为降维后的样本特征维数
% V --- 主成分向量
[r c] = size(A);
% 样本均值
meanVec = mean(A);
% 计算协方差矩阵的转置 covMatT
Z = (A-repmat(meanVec, r, 1));
covMatT = Z * Z';
% 计算 covMatT 的前 k 个本征值和本征向量
[V D] = eigs(covMatT, k);
% 得到协方差矩阵 (covMatT)' 的本征向量
V = Z' * V;
% 本征向量归一化为单位本征向量
for i=1:k
V(:,i)=V(:,i)/norm(V(:,i));
end
% 线性变换(投影)降维至 k 维
pcaA = Z * V;
% 保存变换矩阵 V 和变换原点 meanVec
运行结果为:
- pcaData3 =
- -5.7947 -0.6071
- -3.3886 -0.8795
- -1.6155 1.5665
- -0.1513 2.5051
- 0.9958 -0.5665
- 1.7515 0.6546
- 2.2162 -3.1381
- 5.9867 0.4650
- COEFF3 =
- 0.7084 -0.2826
- 0.5157 -0.2114
- 0.0894 0.7882
- 0.4735 0.5041
[机器学习] PCA主成分分析原理分析和Matlab实现方法的更多相关文章
- 【建模应用】PCA主成分分析原理详解
原文载于此:http://blog.csdn.net/zhongkelee/article/details/44064401 一.PCA简介 1. 相关背景 上完陈恩红老师的<机器学习与知识发现 ...
- PCA(主成分分析)原理,步骤详解以及应用
主成分分析(PCA, Principal Component Analysis) 一个非监督的机器学习算法 主要用于数据的降维处理 通过降维,可以发现更便于人类理解的特征 其他应用:数据可视化,去噪等 ...
- 机器学习之PCA主成分分析
前言 以下内容是个人学习之后的感悟,转载请注明出处~ 简介 在用统计分析方法研究多变量的课题时,变量个数太多就会增加课题的复杂性.人们自然希望变量个数较少而得到的 信息较多.在很 ...
- 机器学习 - 算法 - PCA 主成分分析
PCA 主成分分析 原理概述 用途 - 降维中最常用的手段 目标 - 提取最有价值的信息( 基于方差 ) 问题 - 降维后的数据的意义 ? 所需数学基础概念 向量的表示 基变换 协方差矩阵 协方差 优 ...
- 主成分分析(PCA)原理及R语言实现
原理: 主成分分析 - stanford 主成分分析法 - 智库 主成分分析(Principal Component Analysis)原理 主成分分析及R语言案例 - 文库 主成分分析法的原理应用及 ...
- 主成分分析(PCA)原理及R语言实现 | dimension reduction降维
如果你的职业定位是数据分析师/计算生物学家,那么不懂PCA.t-SNE的原理就说不过去了吧.跑通软件没什么了不起的,网上那么多教程,copy一下就会.关键是要懂其数学原理,理解算法的假设,适合解决什么 ...
- PCA原理分析
动机 在机器学习领域中,我们常常会遇到维数很高的数据,有些数据的特征维度高达上百万维,很显然这样的数据是无法直接计算的,而且维度这么高,其中包含的信息一定有冗余,这时就需要进行降维,总的来说,我们降维 ...
- opencv——PCA(主要成分分析)数学原理推导
引言: 最近一直在学习主成分分析(PCA),所以想把最近学的一点知识整理一下,如果有不对的还请大家帮忙指正,共同学习. 首先我们知道当数据维度太大时,我们通常需要进行降维处理,降维处理的方式有很多种, ...
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
- PCA主成分分析 ICA独立成分分析 LDA线性判别分析 SVD性质
机器学习(8) -- 降维 核心思想:将数据沿方差最大方向投影,数据更易于区分 简而言之:PCA算法其表现形式是降维,同时也是一种特征融合算法. 对于正交属性空间(对2维空间即为直角坐标系)中的样本点 ...
随机推荐
- oneplus8手机蓝牙连接tws耳机无法双击退出语音助手
通过蓝牙协议栈我们知道,蓝牙耳机可以通过发送AT指令唤醒或者退出语音助手 唤醒语音助手: AT+BVRA=1 退出语音助手: AT+BVRA=0 但是实际操作中发现双击可以唤醒但再次双击却无法退出语音 ...
- .Net CLR异常简析
楔子 前面一篇研究了下C++异常的,这篇来看下,CLR的异常内存模型,实际上都是一个模型,承继自windows异常处理机制.不同的是,有VC编译器(vcruntime.dll)接管的部分,被CLR里面 ...
- super关键字的使用
1.super理解为:父类的 2.super可以用来调用:属性.方法.构造器 3.super的使用:调用属性和方法 3.1 我们可以在子类的方法或构造器中.通过使用"super.属性&quo ...
- go-zero docker-compose 搭建课件服务(七):prometheus+grafana服务监控
0.转载 go-zero docker-compose 搭建课件服务(七):prometheus+grafana服务监控 0.1源码地址 https://github.com/liuyuede123/ ...
- settings.py 配置汇总
数据库配置: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', # 数据库引擎 'NAME': ' ', #数据库名称 ...
- Spring Retry 重试
重试的使用场景比较多,比如调用远程服务时,由于网络或者服务端响应慢导致调用超时,此时可以多重试几次.用定时任务也可以实现重试的效果,但比较麻烦,用Spring Retry的话一个注解搞定所有.话不多说 ...
- 三十五、kubernetes NameSpace介绍
Kubernetes NameSpace 介绍 Kubernetes使用命名空间的概念帮助解决集群中在管理对象时的复杂性问题.命名空间允许将对象分组到一起,便于将它们作为一个单元进行筛选和控制.无论是 ...
- pycharm系列---django
manage debug Python Console基本配置 DJANGO_SETTINGS_MODULE=mini_project.settings import sys import djang ...
- MQTT GUI 客户端 可视化管理工具推荐
一款好用的 MQTT 客户端工具可以极大地提高开发者使用MQTT的效率.MQTT 客户端工具常用于建立与 MQTT 服务器的连接,进行主题订阅.消息收发等操作. 今天,在此推荐一款优秀的MQTT GU ...
- flex布局中,元素等间距设置,包括第一个元素的左边,最后一个元素的右边,也等间距
项目中很多地方会用到等间距排放的场景,使用flex 布局可以很方便的实现 .fu{ display: flex; ustify-content: space-between; } 通过上面代码,可以实 ...