对一些常用RDD算子的总结
虽然目前逐渐sql化,但是掌握 RDD 常用算子是做好 Spark 应用开发的基础,而数据转换类算子则是基础中的基础,因此学习这些算子还是很有必要的。
这篇博客主要参考Spark官方文档中RDD编程一章,建议直接看官方写的文档进行学习,毕竟这是大佬们写的文章 https://spark.apache.org/docs/latest/rdd-programming-guide.html#overview
一、最常用的RDD算子
作为大数据领域的hello world, word count是入门级的程序,也是极其重要的基本功,下面给出scala版本的wc。
scala版本的wordCount
val config:SparkConf=new SparkConf().setMaster("local[*]").setAppName("test")
val sc = new SparkContext(config)
val data:RDD[String]=sc.textFile("your path")
val wordRDD:RDD[String]=data.flatMap(line=>line.split(" "))
val cleanWordRDD:RDD[String]=wordRDD.filter(word=>!word.equals(" "))
val kvWordRDD:RDD[(String,Int)]=cleanWordRDD.map(word=>(word,1))
val wordCounts:RDD[(String,Int)]=kvWordRDD.reduceByKey((x,y)=>(x+y))
wordCounts.collect()
上面使用了map,flatMap,filter,reduceByKey这四个transerformation算子和一个collect这个action算子(区别transerformation和action可以观察它的返回值,一般transerformation返回值还是RDD,action就是一个最终结果),这四个transerformation就是最常用的 RDD算子(我最常用)
首先是filter ,如果常用python做数据分析的同学注意一下,filter是筛选出结果而不是过滤掉不要的元素,也就是它有一个返回RDD而不是在原本RDD上过滤值,主要注意这点,filter里面可以是一个有名函数或者是一个匿名函数,但是最重要的是要返回一个boolean值
接下来重点介绍下map和flatMap以及mapPartition的区别,map算子是以元素为粒度进行数据转换,比如wc中wordRDD.map(word=>(word,1)),这就是对每一个word,转换为Pair形式,赋予一个权重,在工作过程中,如果遇到某一个element很重要,那么可以写程序对这个element赋予更多的权重,flatMap 的过程我的理解是,元素---->集合----->元素的一个过程,如下图所示
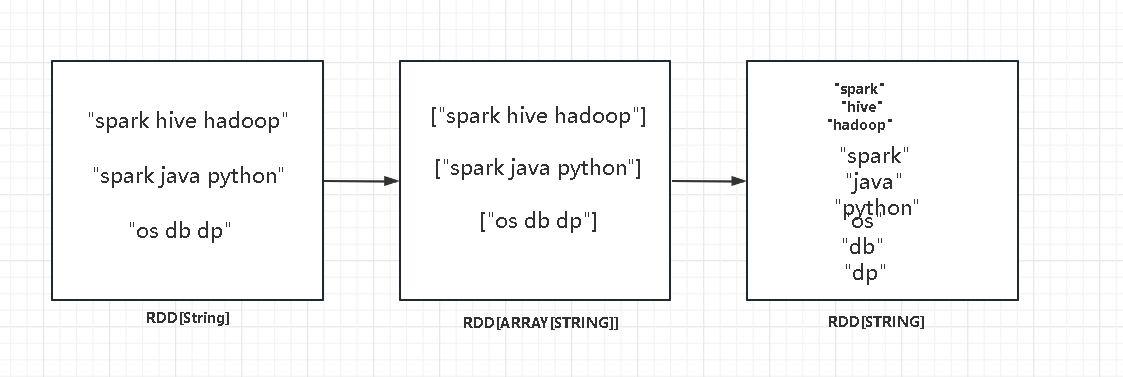
而最后的mapPartition 就是粗粒度的map,以数据分区为粒度,这个函数一般使用在有共同作用因子的场景,比如如对密码加盐,那么可以以数据分区为粒度实例化加密算子,然后使用map在对每个element作用了,这样做的好处就是高效利用内存
二、数据聚合算子
常见的有groupByKey,reduceByKey,aggregateByKey,这样算子一般用在聚合操作
groupByKey(),默认并发度是分区数量,不过也可以指定参数,这个算子的作用是数据收集,而不进行处理,仅仅是收集而非聚合,因此,这个算子在shuffle阶段会很耗性能,因为有大量数据走了shuffle
reduceByKey(f),聚合算子,顾名思义,按照key值分组聚合,reduceByKey算子依旧有shuffle阶段,但是它在map端也有进行聚合操作,所以,在工业环境中,这样会减少很多数据量,这也是该算子比groupByKey算子优秀的地方,不过该算子的缺点就是map端的reduce端的聚合操作必须一致,只能满足一些需求
aggregateByKey,它能使用两个聚合函数,分别作用在map端和reduce端,比如这样一个场景,先求和再求最大值,这样可以定义一个聚合函数F1为sum函数,第二个聚合函数为F2为max函数,其余的跟groupByKey类似
三、常见的ACTION算子
上面那些算子都是TRANSERFORMATION算子,而对数据收集成结果则需要使用ACTION算子,常见的action算子有collect,take,first,foreach,他们的算子使用很简单,不会的同学可以看下官网,不过这里要注意的是collect算子,它走的是全量收集,都收集到driver端,这样不仅会带来很大的网络开销同时driver端有可能发生OOM风险,对于这种情况,我可以查到的解决方法有使用saveAsTextFile来持久化到磁盘,避免与driver交互导致风险
四、持久化算子
spark的持久化以及持久化级别,我们另开文章进行总结。
https://www.cnblogs.com/spark-cc/p/17031953.html
对一些常用RDD算子的总结的更多相关文章
- sparkRDD:第3节 RDD常用的算子操作
4. RDD编程API 4.1 RDD的算子分类 Transformation(转换):根据数据集创建一个新的数据集,计算后返回一个新RDD:例如:一个rdd进行map操作后生了一个新的rd ...
- Spark—RDD编程常用转换算子代码实例
Spark-RDD编程常用转换算子代码实例 Spark rdd 常用 Transformation 实例: 1.def map[U: ClassTag](f: T => U): RDD[U] ...
- RDD算子
RDD算子 #常用Transformation(即转换,延迟加载) #通过并行化scala集合创建RDD val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8 ...
- 大数据入门第二十二天——spark(二)RDD算子(1)
一.RDD概述 1.什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 常用Actoin算子 与 内存管理 、共享变量、内存机制
一.常用Actoin算子 (reduce .collect .count .take .saveAsTextFile . countByKey .foreach ) collect:从集群中将所有的计 ...
- 常用Transformation算子
map 产生的键值对是tupple, split分隔出来的是数组 一.常用Transformation算子 (map .flatMap .filter .groupByKey .reduc ...
- RDD 算子补充
一.RDD算子补充 1.mapPartitions mapPartitions的输入函数作用于每个分区, 也就是把每个分区中的内容作为整体来处理. (map是把每一行) mapPa ...
- 08、Spark常用RDD变换
08.Spark常用RDD变换 8.1 概述 Spark RDD内部提供了很多变换操作,可以使用对数据的各种处理.同时,针对KV类型的操作,对应的方法封装在PairRDDFunctions trait ...
- RDD算子、RDD依赖关系
RDD:弹性分布式数据集, 是分布式内存的一个抽象概念 RDD:1.一个分区的集合, 2.是计算每个分区的函数 , 3.RDD之间有依赖关系 4.一个对于key-value的RDD的Partit ...
- spark教程(四)-SparkContext 和 RDD 算子
SparkContext SparkContext 是在 spark 库中定义的一个类,作为 spark 库的入口点: 它表示连接到 spark,在进行 spark 操作之前必须先创建一个 Spark ...
随机推荐
- Keil 2032 license 解决方法(keygen)
https://pan.baidu.com/s/1nH_KrsHoLEJlJQKhfIoXHA
- PHP Redis - 事务
Redis 事务可以一次执行多个命令, 并有两个重要的保证: ① 事务是一个单独的隔离操作:事务中的所有命令都会序列化.按顺序地执行.事务在执行的过程中,不会被其他客户端发送来的命令请求所打断. ② ...
- uniapp+uView搜索列表变颜色
首先看一下页面效果: <template> <view class="page"> <b-nav-bar title="公司多维图" ...
- 消息队列 RocketMQ4.x介绍和新概念讲解
消息队列 RocketMQ4.x介绍和新概念讲解 Apache RocketMQ作为阿里开源的一款高性能.高吞吐量的分布式消息中间件 RocketMQ4.x特点 支持Broker和Consumer端消 ...
- Verilog 变量声明与数据类型二
Verilog 变量声明与数据类型二 上节介绍了wire,reg数据类型及其用法,并对变量定义中的向量的定义及使用做了说明.本节主要介绍其它几种类型.常用的有如下几种:整数integer,实数 rea ...
- 2、HTTP的消息格式
概念 HTTP协议 Hyper Text Transfer Protocol 超文本传输协议 传输协议 传输协议定义了客户端和服务器端通信时,发送数据的格式. 特点 基于TCP/IP的高级协议 默认端 ...
- Spring Boot基础依赖
<properties> <java.version>1.8</java.version></properties><parent> < ...
- localtime函数
localtime函数: 将时间数值变换成本地时间,考虑到本地时区和夏令时标志; 原型: struct tm *localtime(const time_t * calptr); 头文件 <ti ...
- 记 第一次linux下简易部署 django uwsgi nginx
1.首先确定django项目是跑起来的 2.装nginx uwsgi ,网上教程一大堆 3.uwsgi的配置了 我是通过ini启动的 随意找个顺手的文件夹创建uwsgi.ini文件 我是在/home ...
- 「进阶」缓解眼睛疲劳,防蓝光保护视力,关爱健康!- CareUEyes
软件官网地址:https://care-eyes.com/ 显示 对于显示页面来说 8 个模式下面都有对应的介绍说明,不再介绍.笔者建议软件调节之前,先退出软件,用系统自带的亮度调节,进入电源选项中进 ...