【Flume】概述及组成、入门案例、进阶(事务、拓扑结构)、不同拓扑案例、自定义、数据流监控Ganglia
一、概述
1、定义
日志采集、聚合、传输的系统,基于流式结构
即:读取本地磁盘数据,写入HDFS或kafka
2、架构
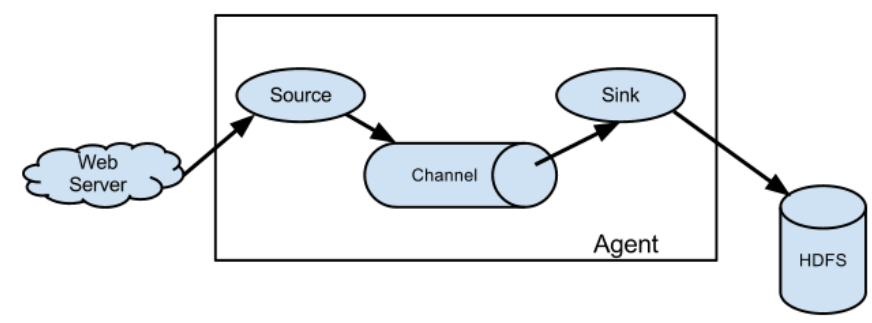
Agent:JVM进程,以事件形式将数据送到目的地。
Agent由三部分组成:Source、Channel、Sink
Source:接受各类日志格式的数据,如avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy
Sink:轮询Channel事件并移除,从而写入存储系统/另一个Flume Agent;
目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
Channel:位于Source和Sink之间的缓冲区,允许二者不同速率,且线程安全,能同时处理多个写入和读出操作
自带两种Channel:Memory Channel(不关心数据是否丢失)和File Channel(不会丢失数据)
数据进行缓存,可以存放在Memory或File中
Event:数据传输的基本单位,由Header和Body两部分组成

公司采用的Source类型为:
(1)监控后台日志:exec
(2)监控后台产生日志的端口:netcat
Exec spooldir
二、Flume入门
1、安装部署
下载、上传、改名
2、入门案例
2.1使用Flume监听一个端口,收集该端口数据,并打印到控制台
安装netcat
检查端口是否被占用:sudo netstat -tunlp | grep 44444
创建job文件夹并编写配置文件vim flume-netcat-logger.conf【配置source和sink的】
开启flume监听端口&执行配置文件: bin/flume-ng agent --conf conf/ --name a1【事件名】 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO【日志级别,日志级别包括:log、info、warn、error】,console
向本机的44444端口发送内容:nc localhost 44444
2.2实时监控Hive日志,并上传到HDFS中
配置环境变量,依赖Hadoop的jar包
创建配置文件:vim flume-file-hdfs.conf

运行flume:bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf
开启Hadoop和Hive并操作Hive产生日志:sbin/start-dfs.sh sbin/start-yarn.sh
bin/hive
在hdfs上查看文件
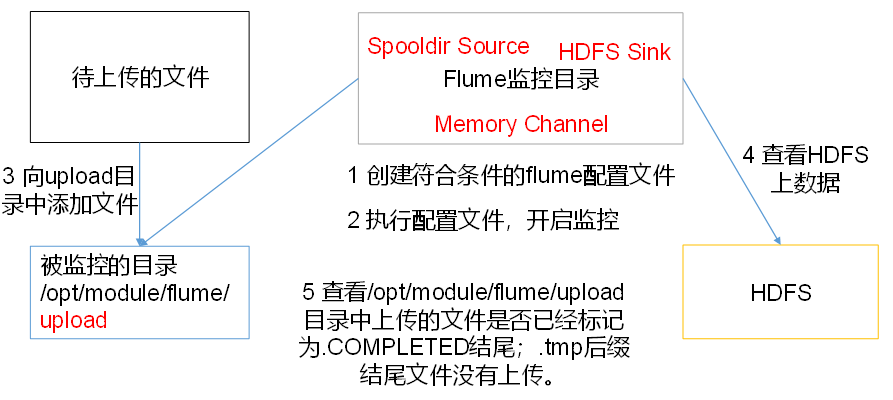
2.3使用Flume监听整个目录的文件,并上传至HDFS
2.4实时监控目录下的多个追加文件
Exec source适用于监控一个实时追加的文件,不能实现断点续传;
Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;
Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传。
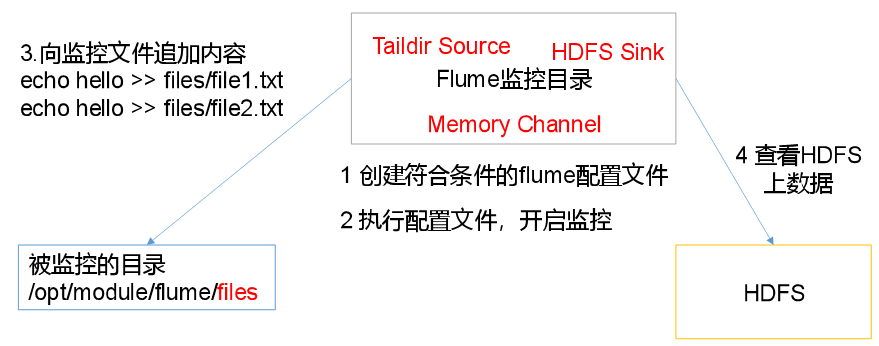
aildir Source维护了一个json格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传
Linux中储存文件元数据的区域就叫做inode,每个inode都有一个号码,操作系统用inode号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。
{"inode":2496272,"pos":12,"file":"/opt/module/flume/files/file1.txt"}
{"inode":2496275,"pos":12,"file":"/opt/module/flume/files/file2.txt"}
三、Flume进阶
1、事务
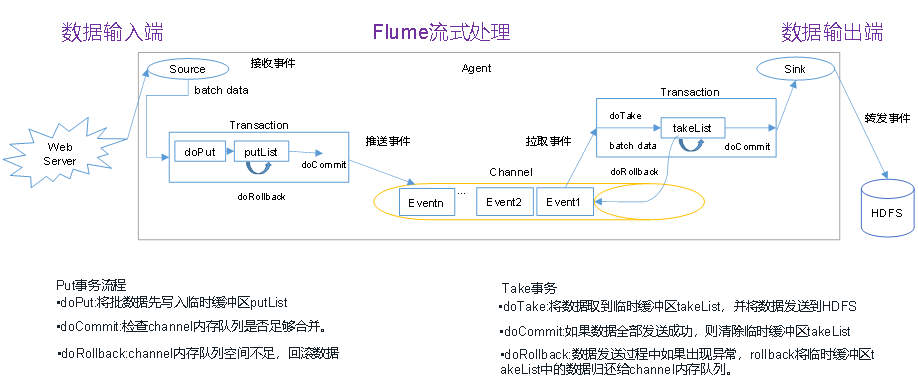
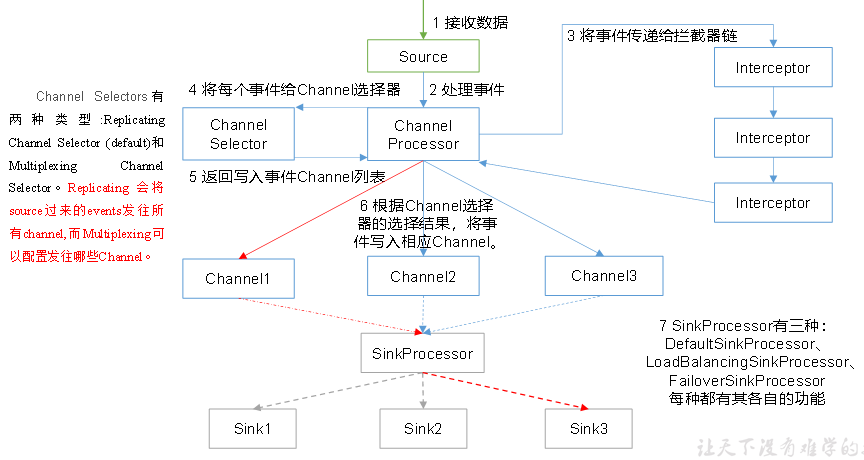
ChannelSelector选出Event将要被发往哪个Channel,两种类型,分别是Replicating(复制)和Multiplexing(多路复用)。
SinkProcessor共有三种类型,分别是DefaultSinkProcessor(单个sink)、(Sink Group)LoadBalancingSinkProcessor【负载均衡】和FailoverSinkProcessor【错误恢复】
2、Flume拓扑结构
简单串联
复制和多路复用
负载均衡和故障转移(将多个sink逻辑上分到一个sink组)
聚合方式:多对多。每台服务器部署一个flume采集日志,传送到一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase等,进行日志分析
3、开发案例
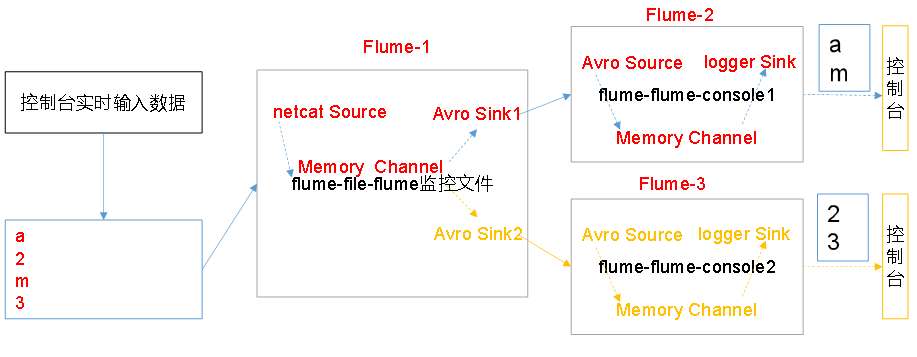
3.1复制和多路复用
文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3负责输出到Local FileSystem。
配置1个接收日志文件的source和两个channel、两个sink,分别输送给flume-flume-hdfs和flume-flume-dir。
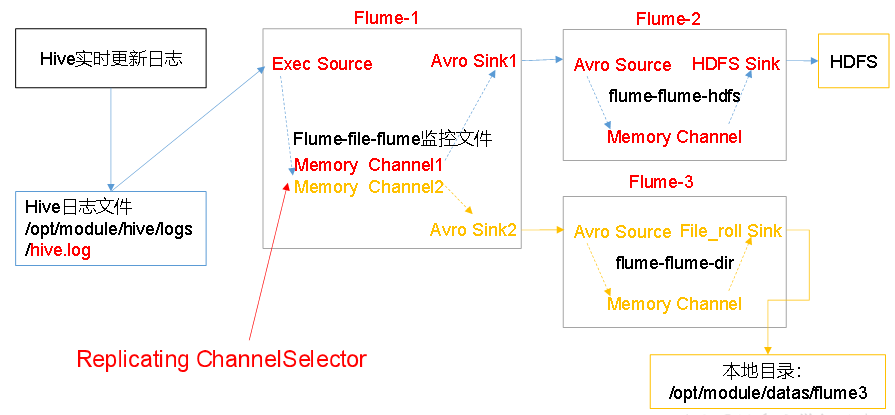
需要配置三個配置文件
3.2負載均衡和故障處理
sink组中的sink分别对接Flume2和Flume3,采用FailoverSinkProcessor,实现故障转移
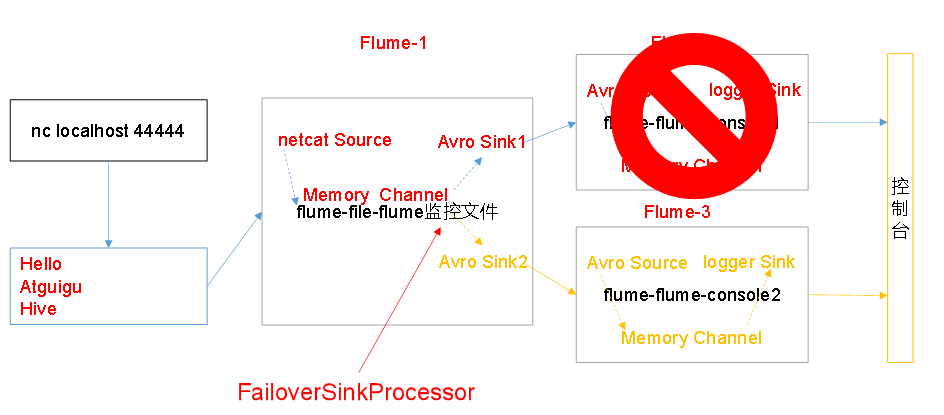
Flume2 kill,观察Flume3的控制台打印情况
注:使用jps -ml查看Flume进程
3.3聚合
Flume-1与Flume-2(分别监控日志文件和数据流)将数据发送给hadoop104上的Flume-3,Flume-3将最终数据打印到控制台。
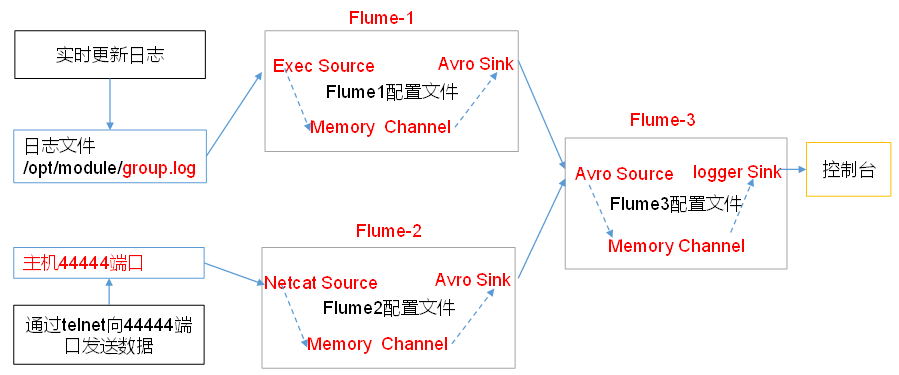
分发flume:xsync flume
接收flume1与flume2发送过来的数据流【在1和2内配置】
4、自定义Interceptor:按照日志类型的不同,将不同种类的日志发往不同的分析系统
以数字(单个)和字母(单个)模拟不同类型的日志
@Override
public Event intercept(Event event) { byte[] body = event.getBody();
if (body[0] < 'z' && body[0] > 'a') {
event.getHeaders().put("type", "letter");
} else if (body[0] > '0' && body[0] < '9') {
event.getHeaders().put("type", "number");
}
return event; }
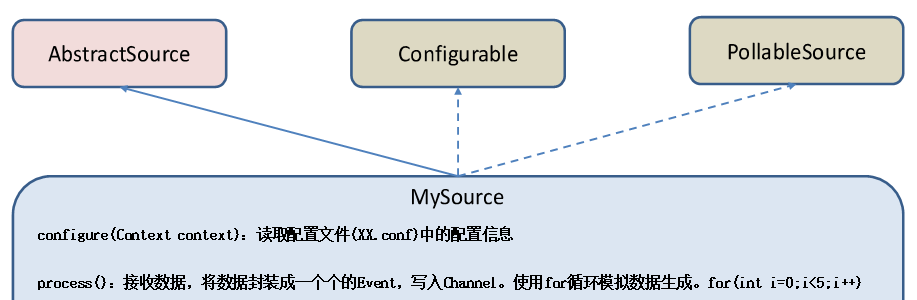
5、自定义Source:给每条数据添加前缀
导入依赖flume-ng-core
@Override
public Status process() throws EventDeliveryException { try {
//创建事件头信息
HashMap<String, String> hearderMap = new HashMap<>();
//创建事件
SimpleEvent event = new SimpleEvent();
//循环封装事件
for (int i = 0; i < 5; i++) {
//给事件设置头信息
event.setHeaders(hearderMap);
//给事件设置内容
event.setBody((field + i).getBytes());
//将事件写入channel
getChannelProcessor().processEvent(event);
Thread.sleep(delay);
}
} catch (Exception e) {
e.printStackTrace();
return Status.BACKOFF;
}
return Status.READY;
}
并在配置文件中配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = com.atguigu.MySource
6、自定义sink:并在Sink端给每条数据添加前缀和后缀,输出到控制台
@Override
public Status process() throws EventDeliveryException { //声明返回值状态信息
Status status; //获取当前Sink绑定的Channel
Channel ch = getChannel(); //获取事务
Transaction txn = ch.getTransaction(); //声明事件
Event event; //开启事务
txn.begin(); //读取Channel中的事件,直到读取到事件结束循环
while (true) {
event = ch.take();
if (event != null) {
break;
}
}
try {
//处理事件(打印)
LOG.info(prefix + new String(event.getBody()) + suffix); //事务提交
txn.commit();
status = Status.READY;
} catch (Exception e) { //遇到异常,事务回滚
txn.rollback();
status = Status.BACKOFF;
} finally { //关闭事务
txn.close();
}
return status;
}
7、Flume数据流监控
Ganglia的安装与部署
操作Flume测试监控,启动Flume任务:
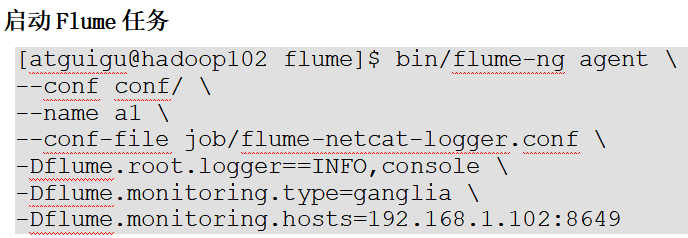
nc localhost 44444发送数据并观察截图
四、问答题
Flume采集数据会丢失吗?
不丢失,但会重复
根据Flume的架构原理,Flume是不可能丢失数据的,其内部有完善的事务机制,Source到Channel是事务性的,Channel到Sink是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是Channel采用memoryChannel,agent宕机导致数据丢失,或者Channel存储数据已满,导致Source不再写入,未写入的数据丢失。
Flume不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由Sink发出,但是没有接收到响应,Sink会再次发送数据,此时可能会导致数据的重复。
【Flume】概述及组成、入门案例、进阶(事务、拓扑结构)、不同拓扑案例、自定义、数据流监控Ganglia的更多相关文章
- webpack4入门到进阶案例实战课程
愿景:"让编程不在难学,让技术与生活更加有趣" 更多教程请访问xdclass.net 第一章 webpack4前言 第一集 webpack4入门到进阶案例实战课程介绍 简介:讲述w ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- Docker入门与进阶(上)
Docker入门与进阶(上) 作者 刘畅 时间 2020-10-17 目录 1 Docker核心概述与安装 1 1.1 为什么要用容器 1 1.2 docker是什么 1 1.3 docker设计目标 ...
- SQL Server 扩展事件(Extented Events)从入门到进阶(4)——扩展事件引擎——基本概念
本文属于 SQL Server 扩展事件(Extented Events)从入门到进阶 系列 在第一二节中,我们创建了一些简单的.类似典型SQL Trace的扩展事件会话.在此过程中,介绍了很多扩展事 ...
- Python语言学习之Python入门到进阶
人们常说Python语言简单,编写简单程序时好像也确实如此.但实际上Python绝不简单,它也是一种很复杂的语言,其功能特征非常丰富,能支持多种编程风格,在几乎所有方面都能深度定制.要想用好Pytho ...
- 《AngularJS入门与进阶》图书简介
一.图书封面 二.图书CIP信息 图书在版编目(CIP)数据 AngularJS入门与进阶 / 江荣波著. – 北京 : 清华大学出版社, 2017 ISBN 978-7-302-46074-9 Ⅰ. ...
- 服务端工程师入门与进阶 Java 版
前言 欢迎加入我们.这是一份针对实习生/毕业生的服务端开发入门与进阶指南.遇到问题及时问你的 mentor 或者直接问我. 建议: 尽量用google查找技术资料. 有问题在stackoverflow ...
- 《SEO教程:搜索引擎优化入门与进阶(第3版)》
<SEO教程:搜索引擎优化入门与进阶(第3版)> 基本信息 作者: 吴泽欣 丛书名: 图灵原创 出版社:人民邮电出版社 ISBN:9787115357014 上架时间:2014-7-1 出 ...
- Weex入门与进阶指南
Weex入门与进阶指南 标签: WeexiOSNative 2016-07-08 18:22 59586人阅读 评论(8) 收藏 举报 本文章已收录于: iOS知识库 分类: iOS(87) 职 ...
- mysql入门与进阶
MySQL入门与进阶 需求:对一张表中的数据进行增删改查操作(CURD) C:create 创建 U:update 修改 R:read 读|检索 查询 D:delete 删除涉及技术:数据库 1.数据 ...
随机推荐
- 4.Ceph 基础篇 - 对象存储使用
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247485256&idx=1&sn=39e07215 ...
- 1.通俗易懂理解Kubernetes核心组件及原理
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483736&idx=1&sn=0cbc3d6a ...
- DevOps图示
- 离线安装chrome浏览器的postman插件
最近开始研究webapi相关的东西,看到chrome浏览器的有个postman插件挺好用的,但是安装包下载下来以后会出现这种情况,这时候我们可以把crx后缀的改成zip格式的然后解压,然后选择开发者模 ...
- Goland Socket 服务
客户端发送消息 并接收服务端消息 package main import ( "fmt" "net" ) func main() { // conn, err ...
- 【高并发】ScheduledThreadPoolExecutor与Timer的区别和简单示例
JDK 1.5开始提供ScheduledThreadPoolExecutor类,ScheduledThreadPoolExecutor类继承ThreadPoolExecutor类重用线程池实现了任务的 ...
- 消息队列之RabbitMQ介绍与运用
RabbitMQ 说明 本章,我们主要从RabbitMQ简介.RabbitMQ安装.RabbitMQ常用命令.RabbitMQ架构模式.RabbitMQ使用.Quick.RabbitMQPlus的使用 ...
- vue3+element-plus+登录逻辑token+环境搭建
vue3+element-plus+登录逻辑token环境搭建 安装脚手架工具 1 npm i @vue/cli@4.5.13 -g 验证是否安装成功 1 vue -V # 输出 @vue/cli 4 ...
- Sublime Text 修改默认语言为Python
Sublime Text 3 修改默认语言为Python 步骤如下 英文:Tools - Developer - New Plugin 中文:工具 - 插件开发 - 新建插件 清空原来内容,用下面的代 ...
- Windows下pip换成清华源
1.在C:\Users\用户名\ 下创建 pip 文件夹2.在文件夹内创建pip.ini 文件, 添加如下内容: [global] timeout = 6000 index-url = https:/ ...