Python_13 接口测试openpyxl和表操作
一、openpyxl
- 安装 pip install openpyxl 在Terminal中输入
- excel操作步骤
- 找到目标excel
- 打开
- 读取数据、编辑excel单元格
- 保存
- 关闭
- openpyxl 操作
- 创建wb对象(找到excel并打开它)
- 获取sheet对象
- 找到要操作的单元格
- 读数据、修改数据
- 保存,关闭
- 操作演示(和3对应的步骤)
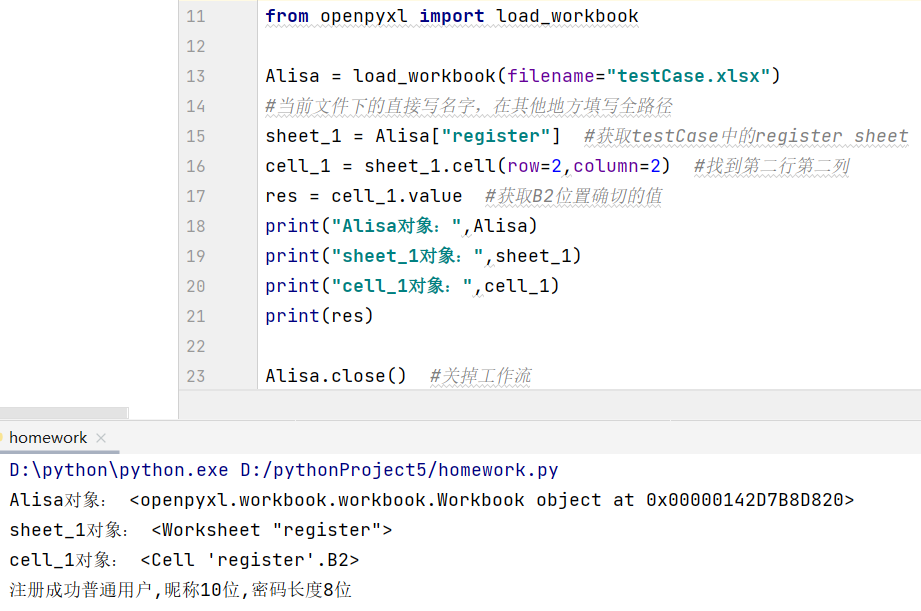
from openpyxl import load_workbook 导入load_workbook类
- 实例化对象名 = load_workbook(filename="文件地址") 带文件名及其后缀
该步骤是创建文件流,初始化load_workbook类之后赋值给实例化对象
如测试文件在该项目文件夹中则直接填写文件名,如果文件不在该项目文件夹中则填写全部的链接
- 有关sheet的新对象名1 = 实例化对象名["测试用例中sheet名"] 获取sheet对象
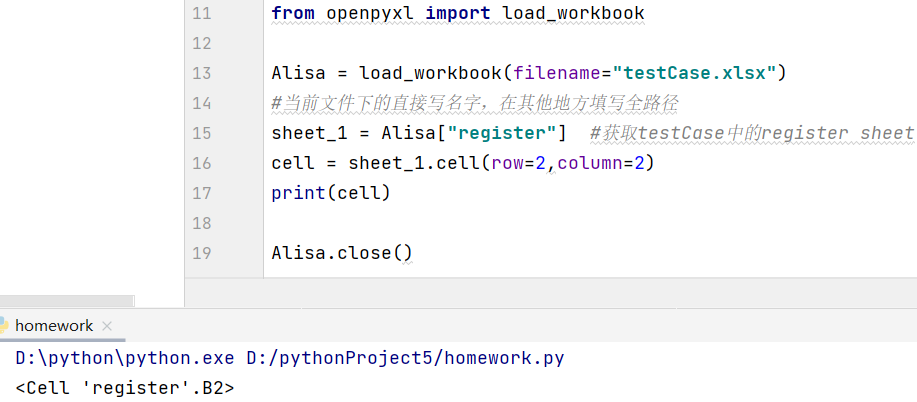
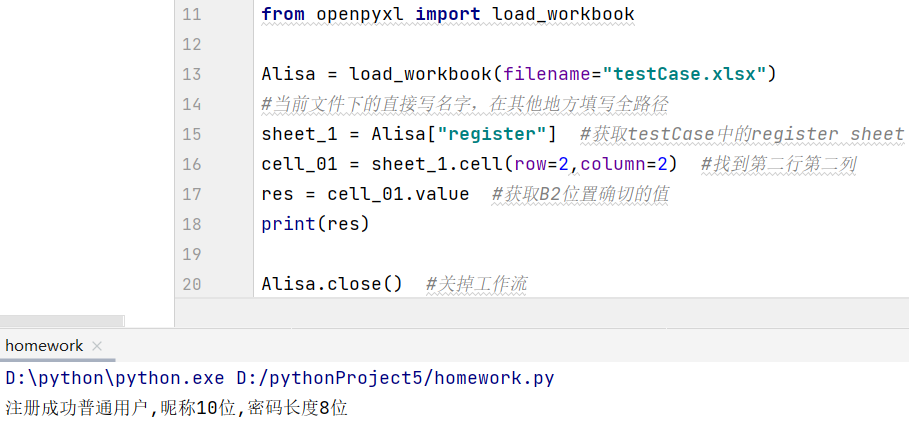
- 新对象名2 = 有关sheet的新对象名1.cell(row=想获取的单元格的行, column=想获取的单元格的列)
找到要操作的单元格
新对象名2的值如下图所示,图中起名cell
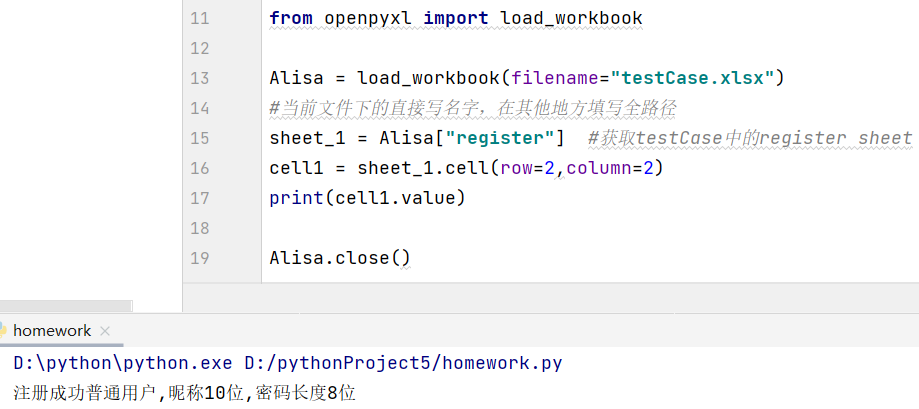
- 接受结果名 = 新对象名2.value print(接受结果名) ,也可直接print(新对象名2.value)
用于获取测试文件中对应位置的确切取值
- 实例化对象名.close() 关掉创建的文件流,不关掉会占用IO,打开多了可能会崩
- 注意: 操作的都是对象(存储的位置),只有读数据时为值
- load_workbook 参数说明
- filename:excel 文件名称(带路径)
- read_only=False: 可读可写,默认False表示可读可写,Ture表示只读
- keep_vba=KEEP_VBA: 保留vba代码
- data_only=False: 默认是False:有计算公式的单元格直接读出来的是公式
True:有公式的单元格读出来是计算后的结果
- keep_links=True: 保留外部链接
- 获取sheet对象
- 有关sheet的新对象名1 = 实例化对象名["测试用例中sheet名"]
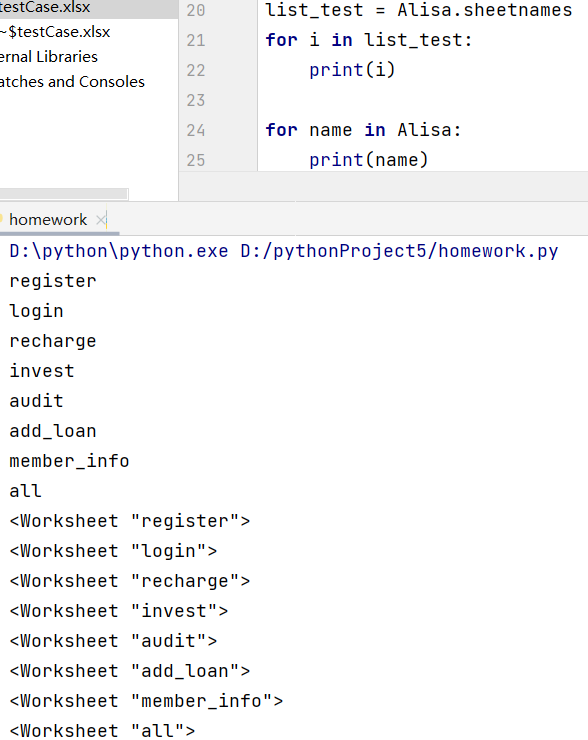
- 新接收结果名2 = 实例化对象名.sheetnames 返回一个sheet名称的list
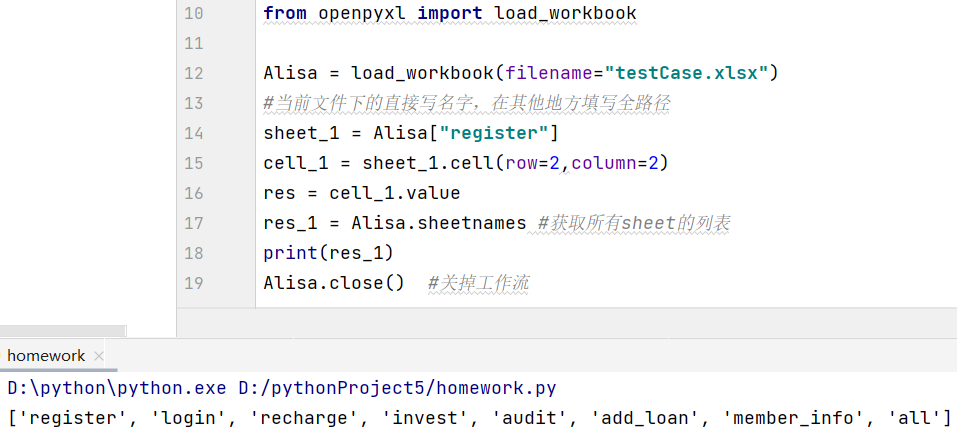
- for name in 实例化对象名 print(name) 遍历sheet对象 和for循环不同的是遍历结果为对象而不是值
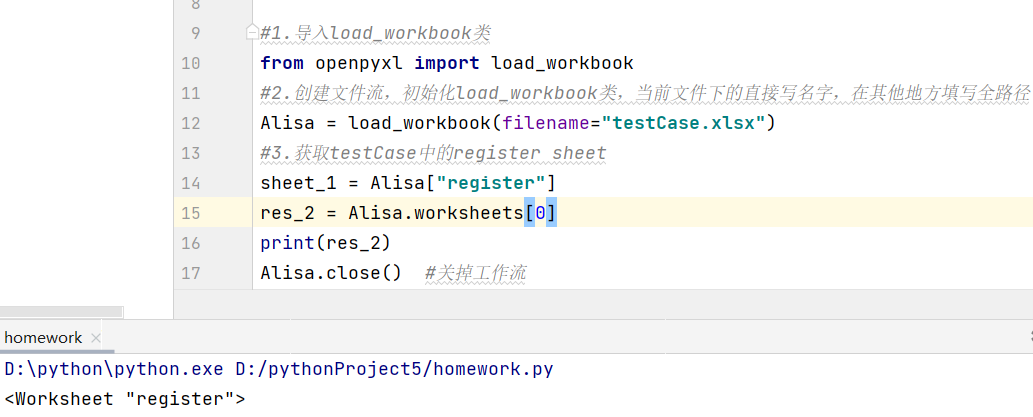
- 结果接收值 = 实例化对象名.worksheets[1] 通过索引值拿到sheet对象
- 找到要操作的单元格
- 接收值的结果 = 有关sheet的新对象名1["excel中的行列值如B2"]
- 新对象名2 = 有关sheet的新对象名1.cell(row=想获取的单元格的行, column=想获取的单元格的列)
5. 行操作
接收值 = 有关sheet的新对
将测试文件中的整行一行一行的遍历,获取所有行的对象,需要list强制类型转换
获取值就要通过双重for 循环获取
行对象接收值 =有关sheet的新对象名1.rows
for i in list(行对象接收值):
for k in i:
print(k.value)
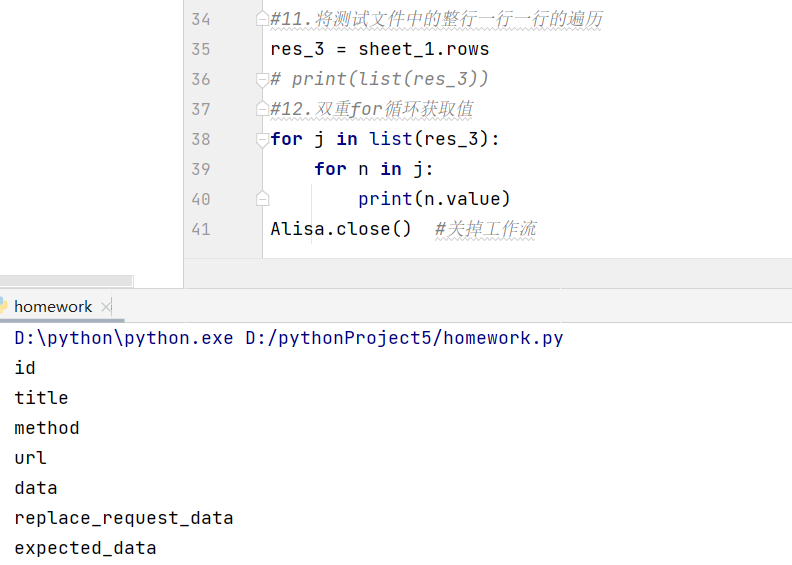
- 接收值 = 有关sheet的新对象名1.max_row 获取最大行,统计测试文档中一共有多少行数据
这一行写了东西全行都会显示,默认有值,但是值是None,如不需要,要进行统一删除
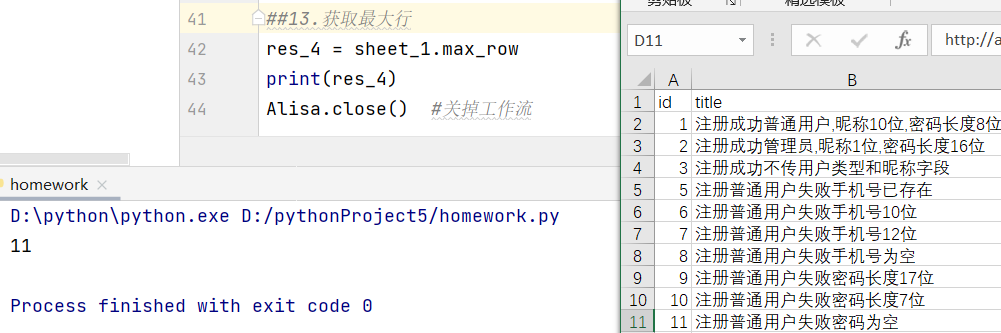
- 行切片 用于取范围里的值,从行到列确定区域,二维的,推荐使用II
- 接收值 = 有关sheet的新对象名1.iter_rows(min_row=1,max_row=5,min_col=1,max_col=5,values_only=True)
print(list(接收值))
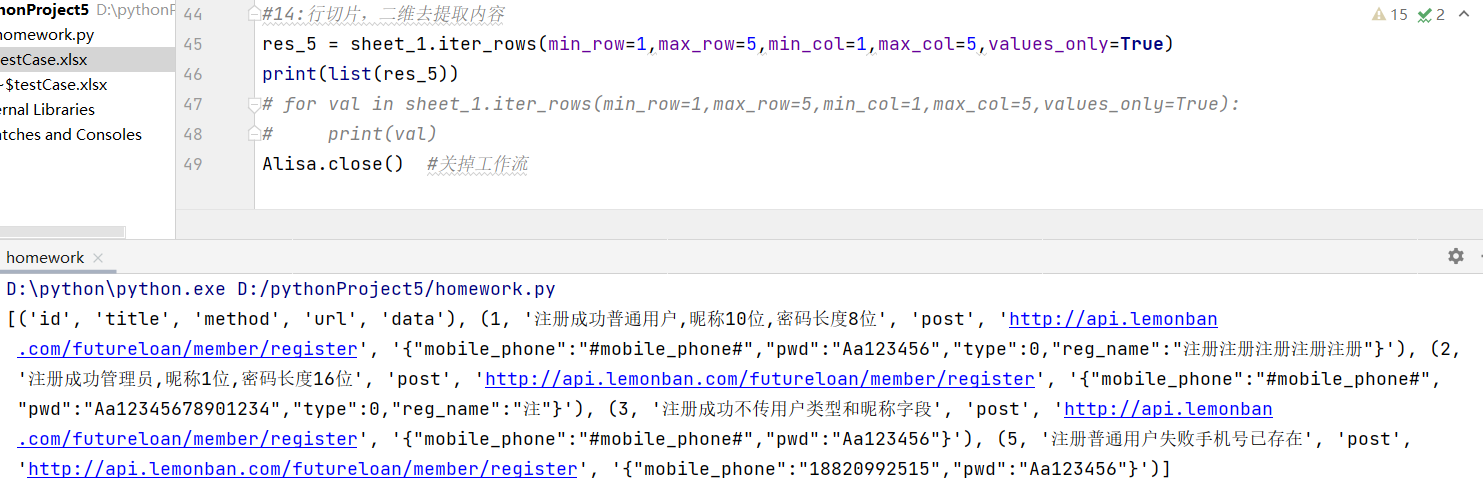
- for val in 有关sheet的新对象名1.iter_rows(min_row=1,max_row=5,min_col=1,max_col=5,values_only=True):
print(val)
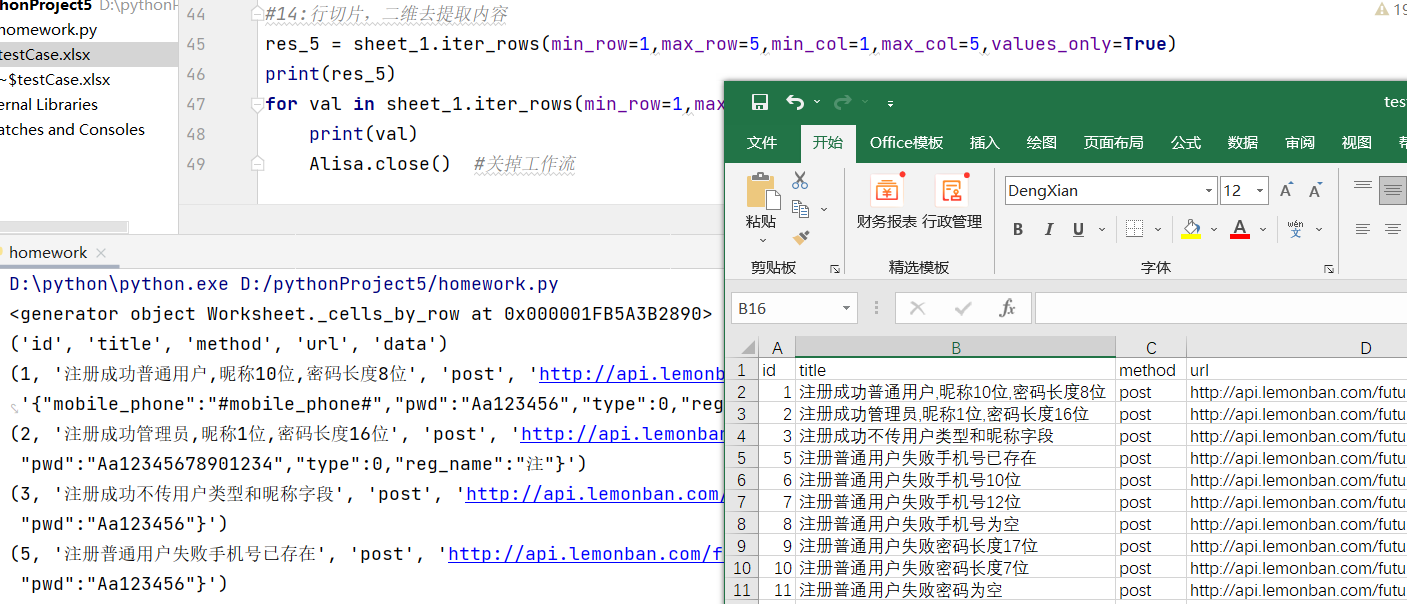
- 统一解释
min_row=对应数值如1 起始行的索引(不写默认为1)
max_row=对应数值如5 结束行索引不写的话默认是最大值,索引从1开始
min_col=对应数值如1 起始列的索引(不写默认为1)
max_col=对应数值如5 结束列的索引(不写的话默认是最大值),索引从1开始
values_only=False 返回单元格的对象
values_only=True 返回单元格的值
- 列操作 (和行操作类似)
- 接收值 = 有关sheet的新对象名1.columns 获取所有列对象,一列一列的遍历
如果要获取值还是要用双重for循环的value方法去取值
列对象接收值 =有关sheet的新对象名1.columns
for i in list(列对象接收值):
for k in i:
print(k.value)
- 接收值 = 有关sheet的新对象名1.max_column 获取最大列
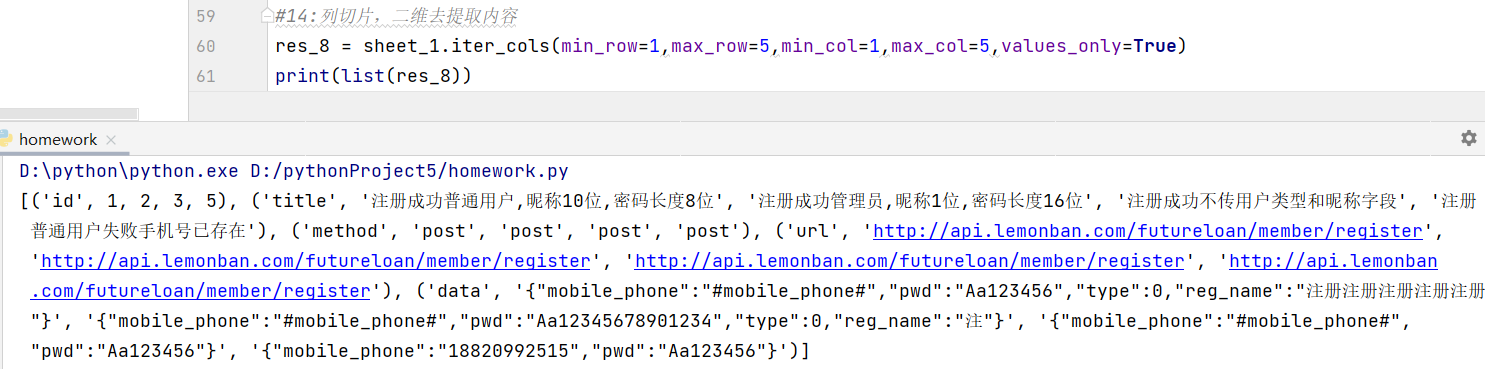
- 列切片 同行切片
- 接收值 = 有关sheet的新对象名1.iter_cols(min_row=1,max_row=5,min_col=1,max_col=5,values_only=True)
print(list(接收值))
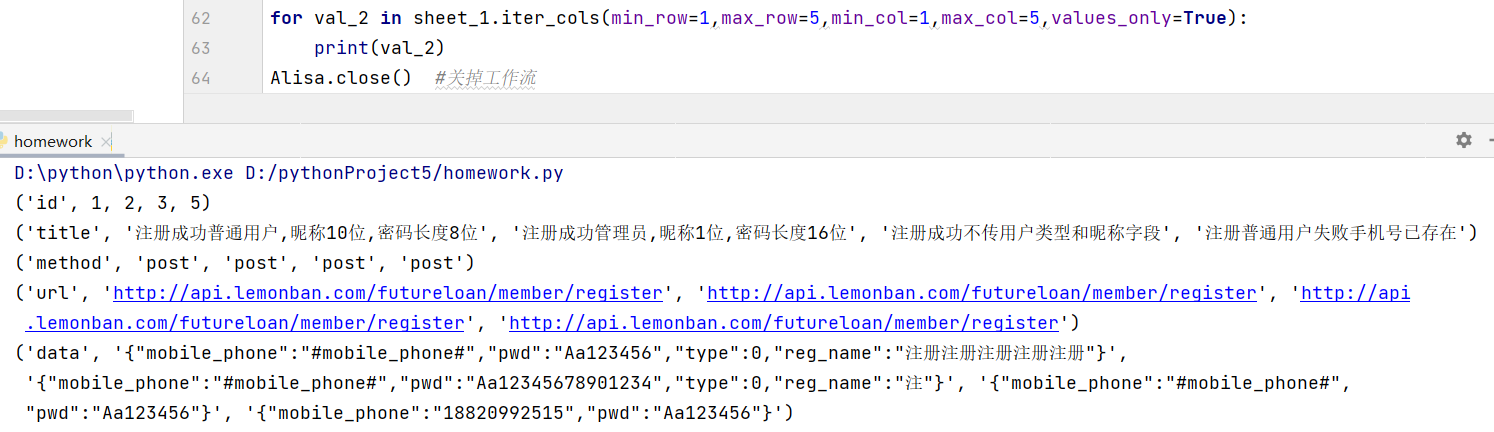
- for val in 有关sheet的新对象名1.iter_cols(min_row=1,max_row=5,min_col=1,max_col=5,values_only=True):
print(val)
二、写表操作和保存
- 有关sheet的新对象名1["excel中的位置如A1"]="要赋的值" 通过给单元格赋值,更改内容
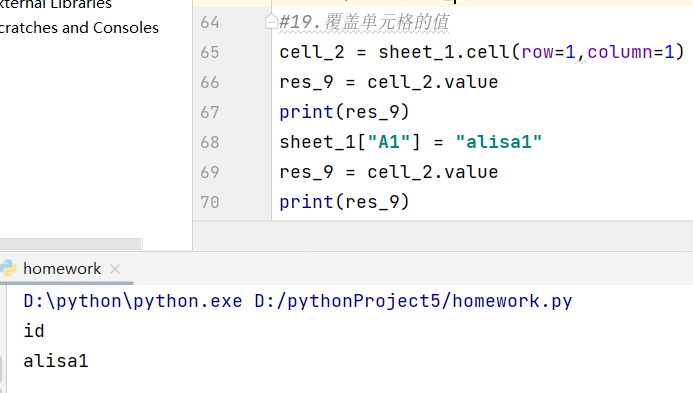
- 有关sheet的新对象名1(row=行值,column=列值).value="要赋的值" 给A1单元格赋值
有关sheet的新对象名1.cell(row=行值,column=列值,value="要赋的值") 给A1单元格传值
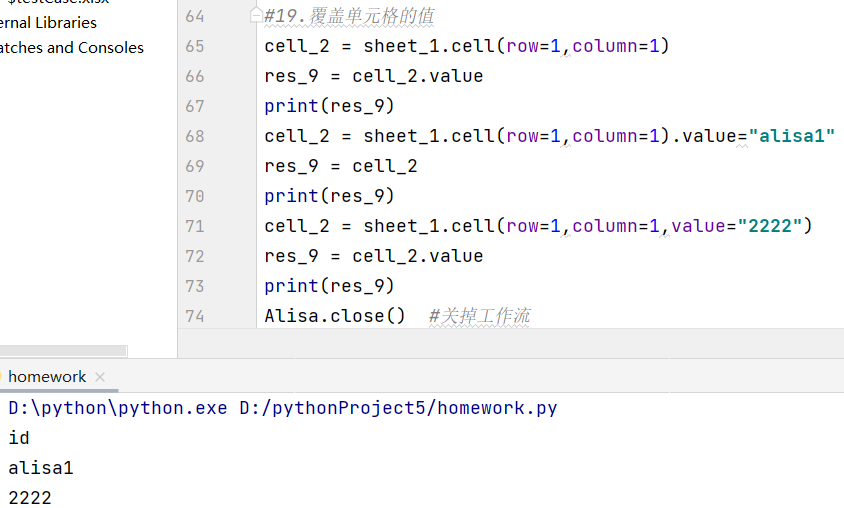
- 实例化对象名.save("文件名.后缀") 保存
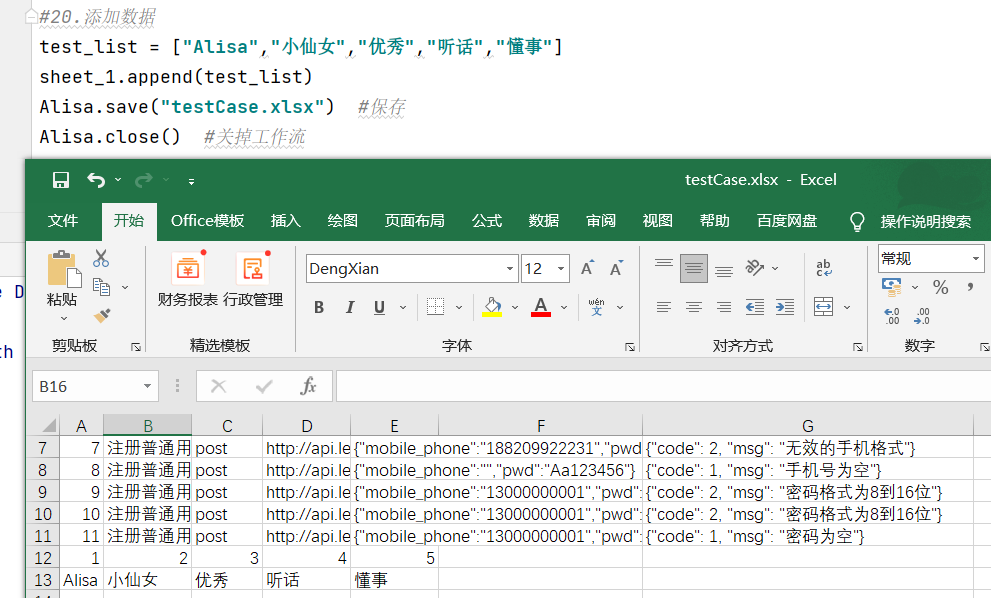
- 有关sheet的新对象名1.append(想要添加的列表名) 添加数据 在表格最下面去写,按行写入,每一个元素站一个单元格
想要添加的列表名=[参数1,参数2,参数3,参数4,参数5]
Python_13 接口测试openpyxl和表操作的更多相关文章
- Python openpyxl、pandas操作Excel方法简介与具体实例
本篇重点讲解windows系统下 Python3.5中第三方excel操作库-openpyxl: 其实Python第三方库有很多可以操作Excel,如:xlrd,xlwt,xlwings甚至注明的数据 ...
- Mysql常用表操作 | 单表查询
160905 常用表操作 1. mysql -u root -p 回车 输入密码 2. 显示数据库列表 show databases 3. 进入某数据库 use database data ...
- Sql Server系列:数据表操作
表是用来存储数据和操作数据的逻辑结构,用来组织和存储数据,关系数据库中的所有数据都表现为表的形式,数据表由行和列组成.SQL Server中的数据表分为临时表和永久表,临时表存储在tempdb系统数据 ...
- 学习MySQL之单表操作(二)
##单表操作 ##创建表 CREATE TABLE t_employee( empno ), ename ), job ), MGR ), Hiredate DATE DEFAULT '0000-00 ...
- python——Django(ORM连表操作)
千呼万唤始出来~~~当当当,终于系统讲了django的ORM操作啦!!!这里记录的是django操作数据库表一对多.多对多的表创建及操作.对于操作,我们只记录连表相关的内容,介绍增加数据和查找数据,因 ...
- mysql数据表操作&库操作
首先登陆mysql:mysql -uroot -proot -P3306 -h127.0.0.1 查看所有的库:show databases; 进入一个库:use database; 显示所在的库:s ...
- SQL server基础知识(表操作、数据约束、多表链接查询)
SQL server基础知识 一.基础知识 (1).存储结构:数据库->表->数据 (2).管理数据库 增加:create database 数据库名称 删除:drop database ...
- Python之Django--ORM连表操作
一对多 class UserType(models.Model): caption = models.CharField(max_length=32) class UserInfo(models.Mo ...
- spark使用Hive表操作
spark Hive表操作 之前很长一段时间是通过hiveServer操作Hive表的,一旦hiveServer宕掉就无法进行操作. 比如说一个修改表分区的操作 一.使用HiveServer的方式 v ...
- [SAP ABAP开发技术总结]内表操作
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
随机推荐
- LoadRunner压力测试(web)
1.打开Virtual User Generator->新建脚本->选择创建新脚本类型,web-HTTP,HTML->创建 2.录制脚本 3.停止脚本录制 4.创建controlle ...
- 9.22 2020 实验 3:Mininet 实验——测量路径的损耗率
一.实验目的 在实验 2 的基础上进一步熟悉 Mininet 自定义拓扑脚本,以及与损耗率相关的设定:初步了解 Mininet 安装时自带的 POX 控制器脚本编写,测试路径损耗率. 二.实验任务 ...
- CentOS查看已安装的服务与卸载服务。。
1:使用rpm查看, rmp -qa | grep servername rpm -qa 查看以安装的所有服务,grep过滤我们需要看的服务. 2:使用yum查看<此命令恕在下未能完全理解,可能 ...
- C#清空控件的值
/// 清除容器里面某些控件的值 /// </summary> /// <param name="parContainer">容器类控件</param ...
- NXOpen遍历工作部件表达式
//用户代码#include <uf_defs.h>#include <NXOpen/NXException.hxx>#include <NXOpen/Session.h ...
- 2.面向对象基础-03Java数组
一.数组的创建和初始化 (一)创建数组: import java.util.*; import java.io.*; public class Main { public static void ma ...
- python数据结构转字符串_python2中字符不显示问题_python2_递归
# encoding:utf-8 def get_str(data): """将python数据转化为肉眼可见的字符串 :param data: str.dict.lis ...
- 基于Mindspore2.0的GPT2预训练模型迁移教程
摘要: 这篇文章主要目的是为了让大家能够清楚如何用MindSpore2.0来进行模型的迁移. 本文分享自华为云社区<MindNLP-基于Mindspore2.0的GPT2预训练模型迁移教程> ...
- Blazor项目在VisualStudio调试时配置运行基础目录
最近在使用 Blazor 开发管理后台时遇到了如下的问题,我这里后台整体采用了 AntDesignBlazor 组件库,在上线之后发现ReuseTabs组件在使用过程中,如果默认 / 没有指定为项目的 ...
- SpringBoot笔记--Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured.报错的解决
问题描述 写了SpringBoot代码之后,运行不出来结果,报出这样的一个错误:Failed to configure a DataSource: 'url' attribute is not spe ...