用更云原生的方式做诊断|大规模 K8s 集群诊断利器深度解析
背景
通常而言,集群的稳定性决定了一个平台的服务质量以及对外口碑,当一个平台管理了相当规模数量的 Kubernetes 集群之后,在稳定性这件事上也许会“稍显被动”。
我们可能经常会遇到这样的场景:客户一个电话,火急火燎地说业务出现问题了,你们平台快帮忙查询一下是不是哪里出了问题呀?技术同学连忙放下手头工作,上去一通操作加安抚客户……看似专业且厉害,急用户之所急,细想之后实则无章无法,一地鸡毛。
通常我们依赖监控系统来提前发现问题,但是监控数据作为一个正向链路,很难覆盖到所有场景,经常会有因为集群配置的不一致性或者一些更底层资源的异常,即使监控数据完全正常,但是整个系统依然会有一些功能不可用。对此,我们做了一套巡检系统,针对系统中一些薄弱点以及一致性做诊断,但是这套系统的扩展性不是很好,对集群跟巡检项的管理也相对粗暴了一点。
最后我们决定做一个更加云原生的诊断工具,使用 operator 实现集群跟诊断项的管理,抽象出集群跟诊断项的资源概念,以此来解决大规模 Kubernetes 集群的诊断问题,通过在中心下发诊断项到其他集群,并统一收集其他集群的诊断结果,实现任何时刻都可以从中心获取到其他所有集群的运行状态,做到对大规模 Kubernetes 集群的有效管理以及诊断。
Talk is cheap, show me the demo:
Kubeprober
项目介绍
项目地址: https://github.com/erda-project/kubeprober
官网地址: https://k.erda.cloud
Kubeprober 是一个针对大规模 Kubernetes 集群设计的诊断工具,用于在 Kubernetes 集群中执行诊断项以证明集群的各项功能是否正常,Kubeprober 有如下特点:
支持大规模集群
支持多集群管理,支持在管理端配置集群跟诊断项的关系以及统一查看所有集群的诊断结果;云原生
核心逻辑采用 operator 来实现,提供完整的 Kubernetes API 兼容性;可扩展
支持用户自定义巡检项。
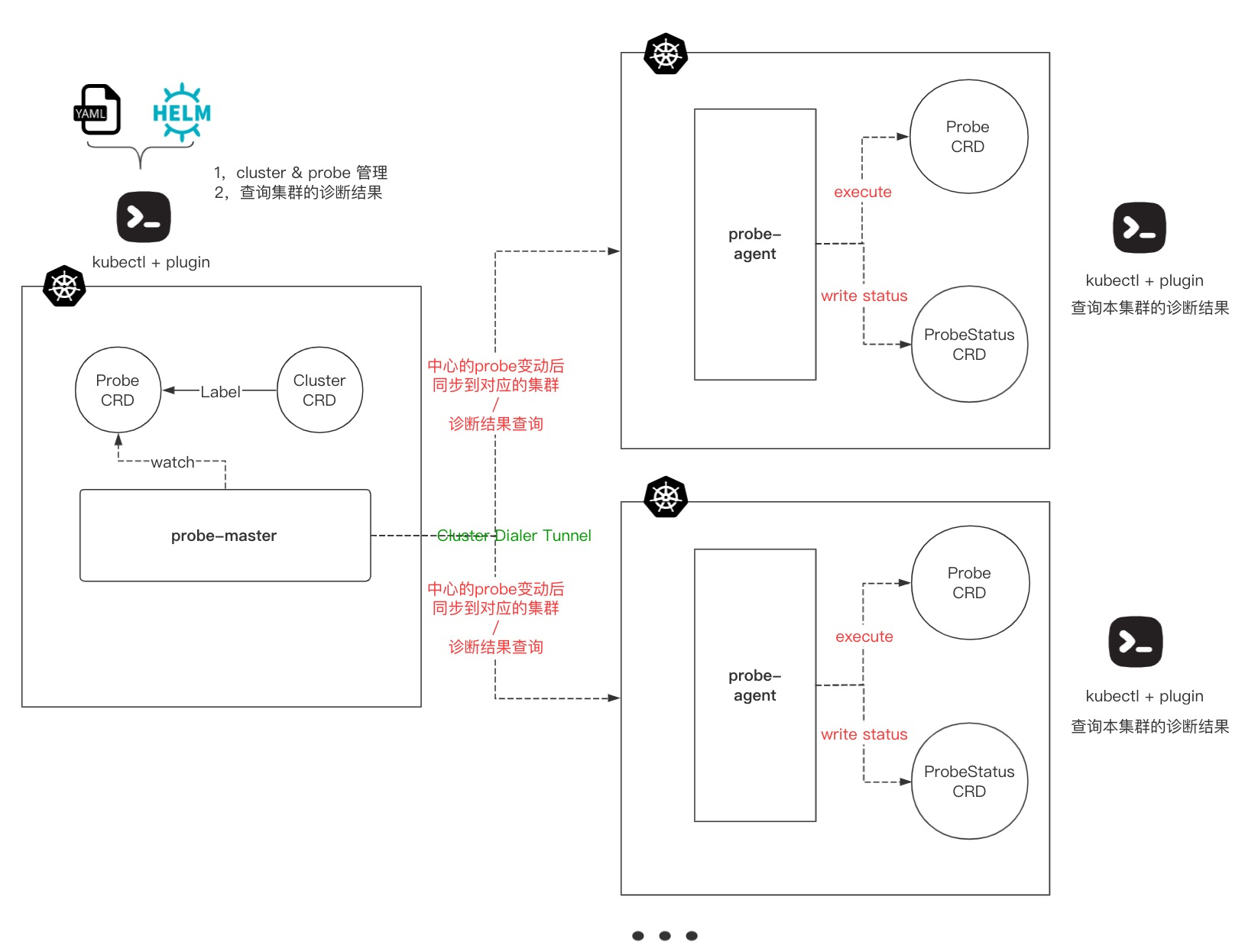
其核心架构如下:
区别于监控系统,Kubeprober 从巡检的角度来验证集群的各项功能是否正常,监控作为正向链路,无法覆盖系统中的所有场景,即使系统中各个环境的监控数据都正常,也无法保证系统是 100% 可用的,因此我们就需要一个工具从反向来证明系统的可用性,根本上做到先于用户发现集群中不可用的点,比如:
- 集群中的所有节点是否均可以被调度,有没有特殊的污点存在等;
- pod 是否可以正常的创建,销毁,验证从 Kubernetes,Kubelet 到 Docker 的整条链路;
- 创建一个 service,并测试连通性,验证 kube-proxy 的链路是否正常;
- 解析一个内部或者外部的域名,验证 CoreDNS 是否正常工作;
- 访问一个 ingress 域名,验证集群中的 ingress 组件是否正常工作;
- 创建并删除一个 namespace,验证相关的 webhook 是否正常工作;
- 对 Etcd 执行 put/get/delete 等操作,用于验证 Etcd 是否正常运行;
- 通过 mysql-client 的操作来验证 MySQL 是否正常运行;
- 模拟用户对业务系统进行登录,操作,验证业务的主流程是否正常;
- 检查各个环境的证书是否过期;
- 云资源的到期检查;
- ……
组件介绍
Kubeprober 整体采用 Operator 来实现核心逻辑,集群之间的管理使用 remotedialer 来维持被纳管集群跟管理集群之间的心跳链接,被纳管集群通过 RBAC 赋予 probe-agent 最小所需权限并且通过心跳链接实时上报被纳管集群元信息以及访问 apiserver 的 token,实现在管理集群可以对被管理集群的相关资源进行操作的功能。
probe-master
运行在管理集群上的 operator 维护着两个 CRD:一个是 Cluster,用于管理被纳管的集群;另一个是 Probe,用于管理内置的以及用户自己编写的诊断项。probe-master 通过 watch 这两个 CRD,将最新的诊断配置推送到被纳管的集群,同时 probe-master 提供接口用于查看被纳管集群的诊断结果。
probe-agent
运行在被纳管集群上的 operator,这个 operator 维护两个 CRD:一个是跟 probe-master 完全一致的 Probe,probe-agent 按照 probe 的定义去执行该集群的诊断项;另一个是 ProbeStatus,用于记录每个 Probe 的诊断结果,用户可以在被纳管的集群中通过 kubectl get probestatus 来查看本集群的诊断结果。
什么是 Probe
Kubeprobe 中运行的诊断计划我们称之为 Probe,一个 Probe 为一个诊断项的集合,我们建议将统一场景下的诊断项作为一个 Probe 来运行,probe-agent 组件会 watch probe 资源,执行 Probe 中定义的诊断项,并且将结果写在 ProbeStatus 的资源中。
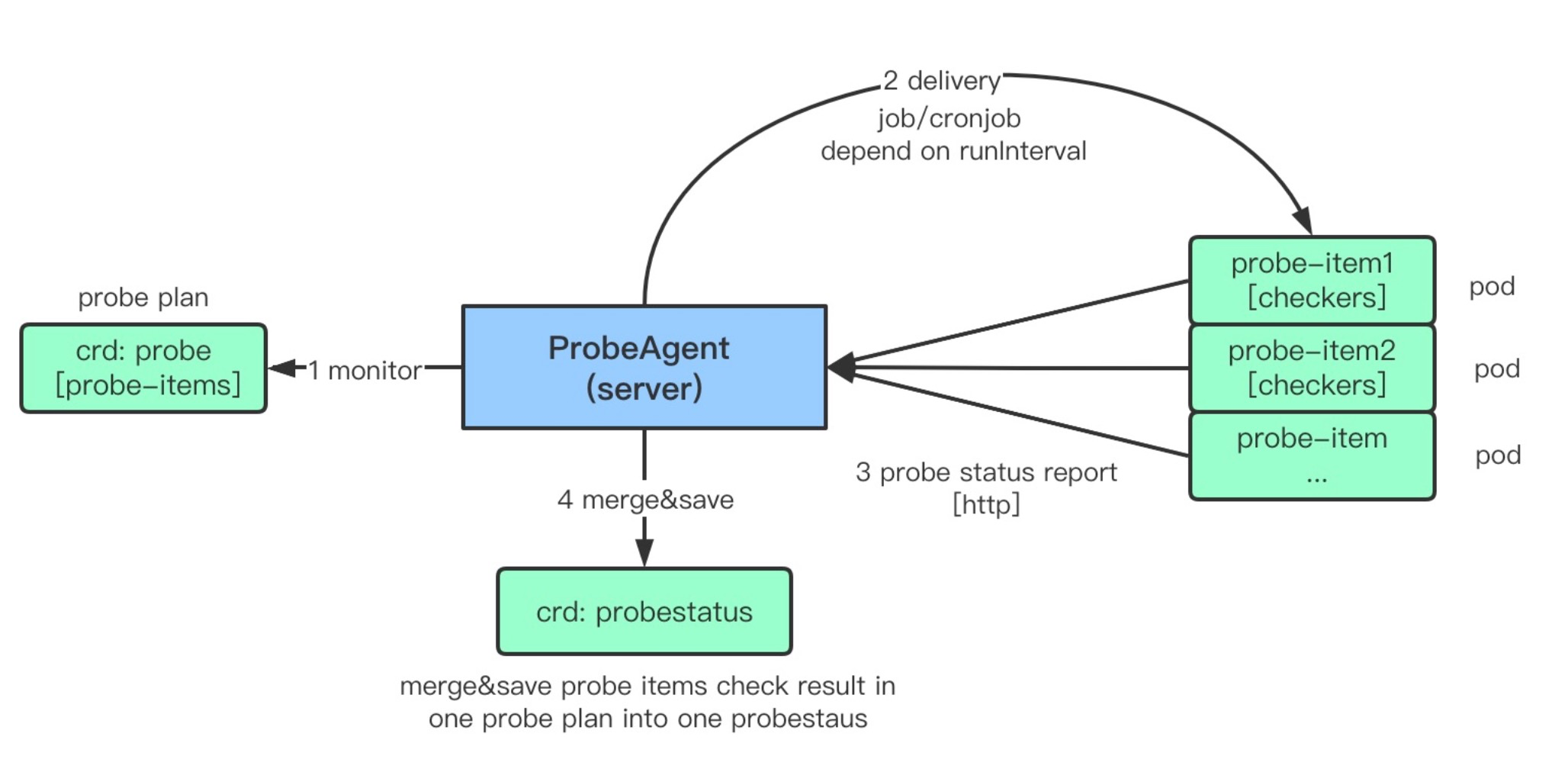
我们期望有一个输出可以清晰地看到当前集群的运行状态,因此我们建议所有的 Probe 都尽可能属于应用、中间件、Kubernetes 以及基础设置这四大场景,这样我们可以在展示状态的时候,清晰且自上而下地查看究竟是系统中哪个层面引起的问题。
目前的 Probe 还比较少,我们还在继续完善,也希望跟大家一起共建。欢迎广大爱好者一起来共建:
自定义 Probe

对比其他诊断工具
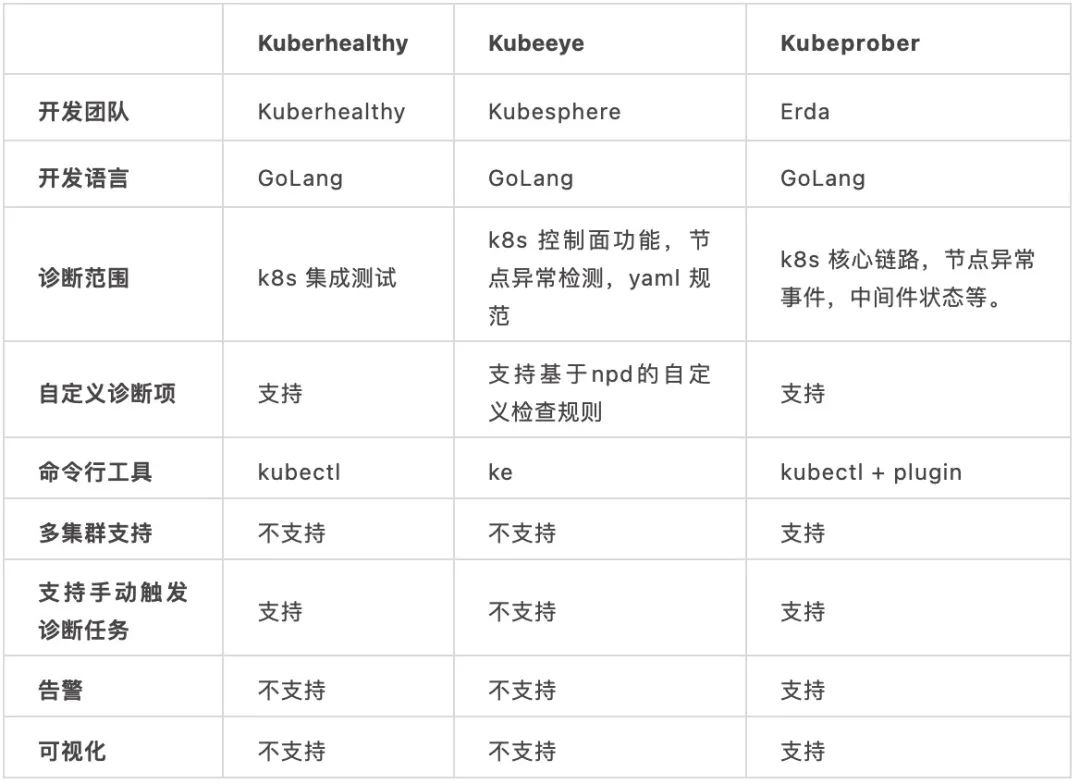
目前社区已经有 Kuberhealthy 以及 Kubeeye 来做 Kubernetes 集群诊断这件事情。
Kuberheathy 提供一套比较清晰的框架可以让你轻松编写自己的诊断项,将诊断项 CRD 化,可以轻松地使用Kubernetes 的方式来对单个 Kubernetes 进行体检。
Kubeeye 同样是针对单个集群,主要通过调用 Kubernetes 的 event api 以及 Node-Problem-Detector 来检测集群控制平面以及各种节点问题,同时也支持自定义诊断项。
其实,Kubeprober 做的也是诊断 Kubernetes 集群这件事情,提供框架来编写自己的诊断项。除此之外,Kubeprober 主要解决了大规模 Kubernetes 集群的诊断问题,通过中心化的思路,将集群跟诊断项抽象成 CRD,可以实现在中心 Kubernetes 集群管理其他 Kubernetes 诊断项配置,诊断结果收集,未来也会解决大规模 Kubernetes 集群的运维问题。
如何使用
Kubeprober 主要解决大规模 Kubernetes 集群的诊断问题,通常我们选择其中一个集群作为 master 集群,部署probe-master,其他集群作为被纳管集群,部署 probe-agent,详细的使用说明可参考官方文档。
可视化
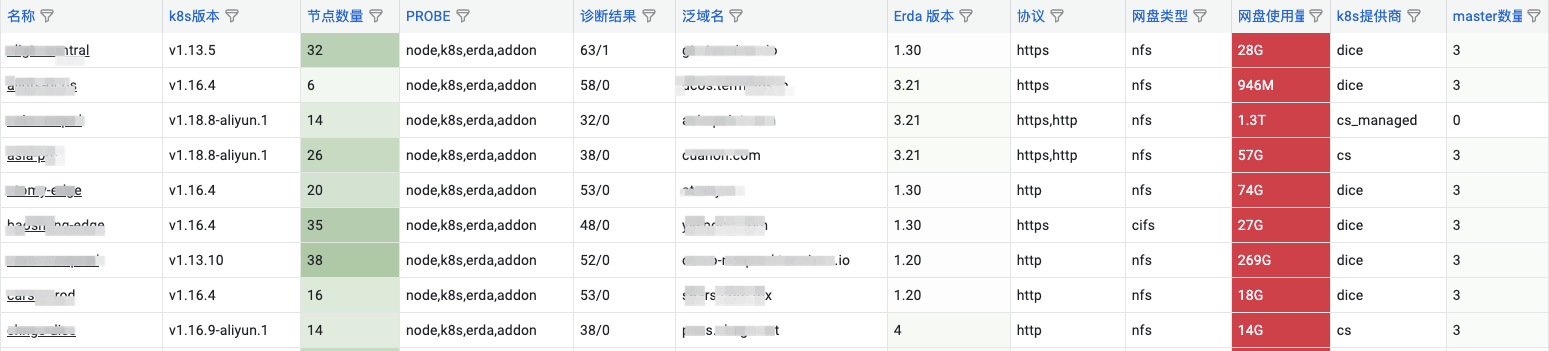
Kubeprober 在多集群中根据 probe 的策略执行诊断项,会产生大量的诊断事件。由此,对这些诊断项进行可视化的展示就显得尤为重要,此时如果有一个全局的 dashboard 对大规模集群的海量诊断项进行统一查看分析,将会更有利于我们掌握这些集群的运行状态。
Kubeprober 支持将诊断项事件写入 influxdb,通过 grafana 配置图表来统一展示诊断结果,比如:我们将 ERROR 事件统一展示出来作为最高优先级进行关注。
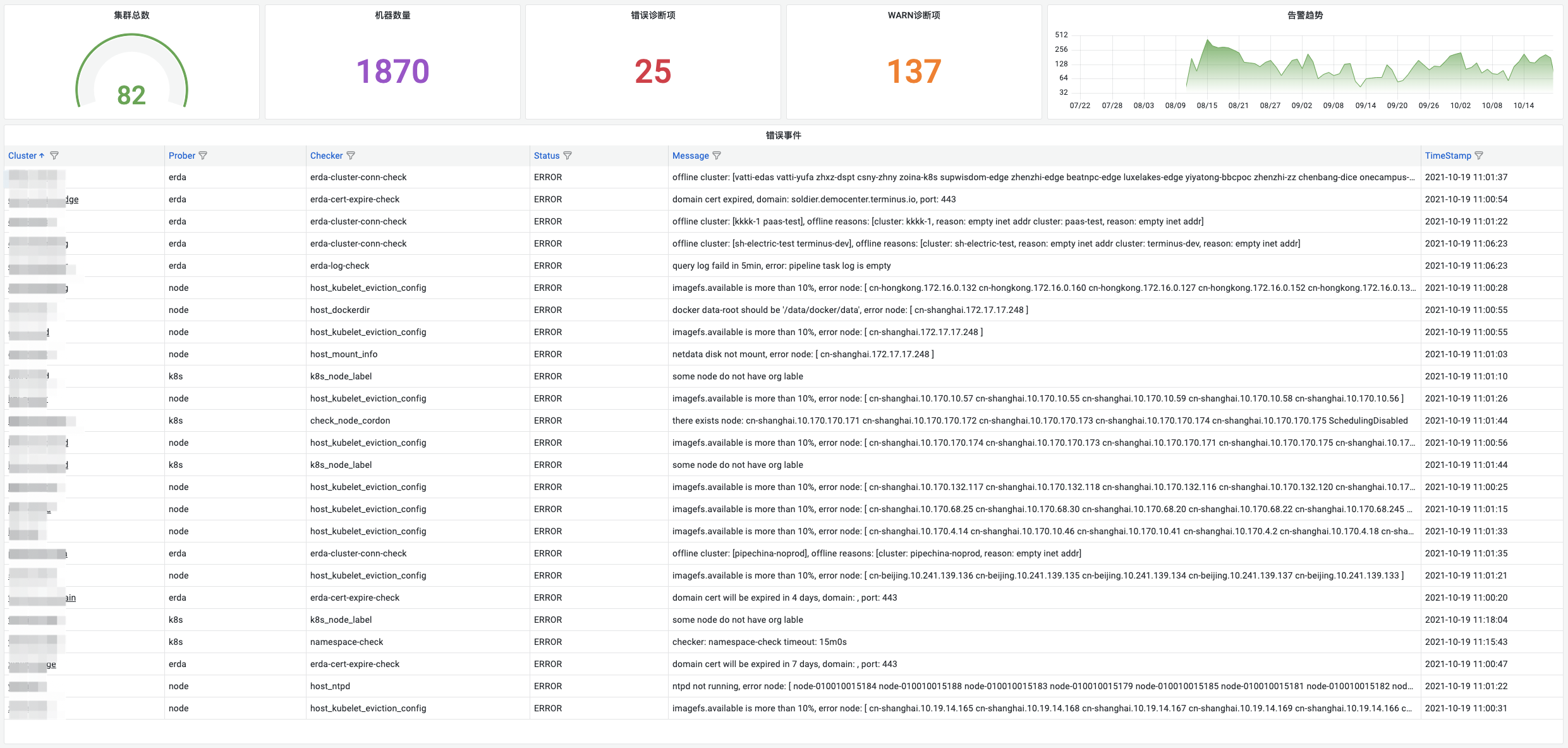
同时,我们也可以通过扩展 probe-agent 上报的集群信息,展示一张详尽的集群列表:
结语
随着数字化的逐渐发展,企业的 IT 架构也变得越来越复杂,如何在复杂环境中保证业务连续性及稳定性?相信这是每一个 IT 从业者都会面临的问题,如果大家对稳定性的话题或者是对 Kuberprober 项目感兴趣,欢迎联系我们一起深入探讨,同时也欢迎广大开源爱好者一起参与,共同打造一个大规模的 Kubernetes 集群的管理神器。Contributing to Kubeprober
我们致力于决社区用户在实际生产环境中反馈的问题和需求,
如果您有任何疑问或建议,
欢迎关注【尔达Erda】公众号给我们留言,
加入 Erda 用户群参与交流或在 Github 上与我们讨论!
用更云原生的方式做诊断|大规模 K8s 集群诊断利器深度解析的更多相关文章
- 企业运维实践-还不会部署高可用的kubernetes集群?使用kubeadm方式安装高可用k8s集群v1.23.7
关注「WeiyiGeek」公众号 设为「特别关注」每天带你玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 文章目录: 0x00 前言简述 ...
- 面对大规模 K8s 集群,这款诊断利器必须要“粉一波”!
作者|段超 来源|尔达 Erda 公众号 背景 我们是一家做商业软件的公司,从一开始我们就把软件交付流程做的非常标准且简单,所有的软件都是基于我们的企业数字化平台 Erda(现已开源)来交付,底层基于 ...
- K8s 集群节点在线率达到 99.9% 以上,扩容效率提升 50%,我们做了这 3 个深度改造
点击下载<不一样的 双11 技术:阿里巴巴经济体云原生实践> 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击上方图片即可下载! 作者 | 张振(守辰) ...
- 腾讯云 K8S 集群实战 Service Mesh—Linkerd2 & Traefik2 部署 emojivoto 应用
Linkerd 是 Kubernetes 的服务网格. 它通过为您提供运行时调试(runtime debugging).可观察性(observability).可靠性(reliability)和安全性 ...
- 阿里云重磅发布RDS for SQL Server AlwaysOn集群版
2018年双十一刚过,阿里云数据库发布RDS for SQL Server AlwaysOn集群版,这是业界除微软云SQL Database外,首家云计算公司基于SQL Server最新AlwaysO ...
- 超详细,多图文介绍redis集群方式并搭建redis伪集群
超详细,多图文介绍redis集群方式并搭建redis伪集群 超多图文,对新手友好度极好.敲命令的过程中,难免会敲错,但为了截好一张合适的图,一旦出现一点问题,为了好的演示效果,就要从头开始敲.且看且珍 ...
- Kubernetes实战总结 - 阿里云ECS自建K8S集群
一.概述 详情参考阿里云说明:https://help.aliyun.com/document_detail/98886.html?spm=a2c4g.11186623.6.1078.323b1c9b ...
- 轻量化安装 TKEStack:让已有 K8s 集群拥有企业级容器云平台的能力
关于我们 更多关于云原生的案例和知识,可关注同名[腾讯云原生]公众号~ 福利: ①公众号后台回复[手册],可获得<腾讯云原生路线图手册>&<腾讯云原生最佳实践>~ ②公 ...
- 国内k8s集群部署的几种方式
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/lusyoe/article/details/80217291前言总所周知,由于某种原因,通过官方的方 ...
随机推荐
- Lambda8 表达式
Lambda 表达式 Lambda 表达式是 JDK8 的一个新特性,可以取代大部分的匿名内部类,写出更优雅的 Java 代码,尤其在集合的遍历和其他集合操作中,可以极大地优化代码结构. JDK 也提 ...
- 纯CSS实现扁平化风格开关按钮
开关样式预览图 前言 最近在基于bootstrap框架开发一个网站,在填写表单一项需要用户填写是否选择某一选项,本来想引用bootstrap框架自带的一个按钮插件,结果在引用js的时候总是出错,就找了 ...
- zhilizhili-ui 荡平ie8910 还我前端清净地
zhilizhili-ui 给大家带来一个目前最新版本的ie8方案 特色 flexbox部分功能 vw vh calc部分功能 angular1.4 todo avalon是因为无法和polyfill ...
- maven项目中各文件都没有报错,但是项目名称有红叉
项目报错可以看到Problems(可以在Window--Show View--other--输入Problems找到) 一.可能原因 1.项目中各文件没有报错,但是项目名称中 ...
- YACS-2022.4-银组
https://www.iai.sh.cn/contest 2022.04 银组,理论上 \(100+100+30+100\). T1 上锁的抽屉 题目描述 有一个抽屉柜里竖排了 \(n\) 只抽屉. ...
- I/O 引脚
我们以网卡举例 引脚,芯片,pcb板之间的关系非常紧密 1.引脚,又叫管脚,英文叫Pin. 就是从集成电路(芯片)内部电路引出与外围电路的接线,所有的引脚就构成了这块芯片的接口.引线末端的一段,通过软 ...
- RFC 标准文档
RFC 标准文档 什么是 RFC ? RFC(Request For Comments)意即"请求评论",包含了关于Internet的几乎所有重要的文字资料.如果你想成为网络方面的 ...
- 三、DOS命令
常用的DOS命令 #盘符切换 D: #查看当前目录下的所有文件 dir #切换目录 cd+空格+/d+空格+路径 #返回上一级 cd+空格+.. #清理屏幕 cls #退出终端 exit #查看电脑 ...
- AcWing 158. 项链 (最小表示法)
项链 题源:https://www.acwing.com/problem/content/160/ 题目 原理:最小表示法 找字典序最小的字符串 循环移位,破环成链 (把原串复制一倍) memcpy ...
- 2021.12.02 P4001 [ICPC-Beijing 2006]狼抓兔子(最小割)
2021.12.02 P4001 [ICPC-Beijing 2006]狼抓兔子(最小割) https://www.luogu.com.cn/problem/P4001 题意: 把图分成两部分需要的最 ...