(转载)HashMap工作原理
HashMap是近些年来java面试中常问到的知识点,很多人(包括我在内)都知道HashMap的用法,也知道HashMap与HashTable之间的区别,但是却不知其所以然,于是乎,本人开始查阅相关资料,解读HashMap的实现源代码,打算一探究竟。
一、HashMap的基本了解
基本定义:根据源代码的描述可知,HashMap是基于哈希表的Map接口的实现,其包含了Map接口的所有映射操作,并且允许使用null键和null值。
与HashTable的区别:HashMap可以近似地看成是HashTable,但是它是非线程安全的,并且允许使用null键和null值,而这些都与HashTable恰巧相反。
注:HashMap可以使用ConcurrentHashMap代替,ConcurrentHashMap是一个线程安全,更加快速的HashMap.
存储结构:HashMap的存储结构其实就是哈希表的存储结构(由数组与链表结合组成,称为链表的数组)。如下图所示:
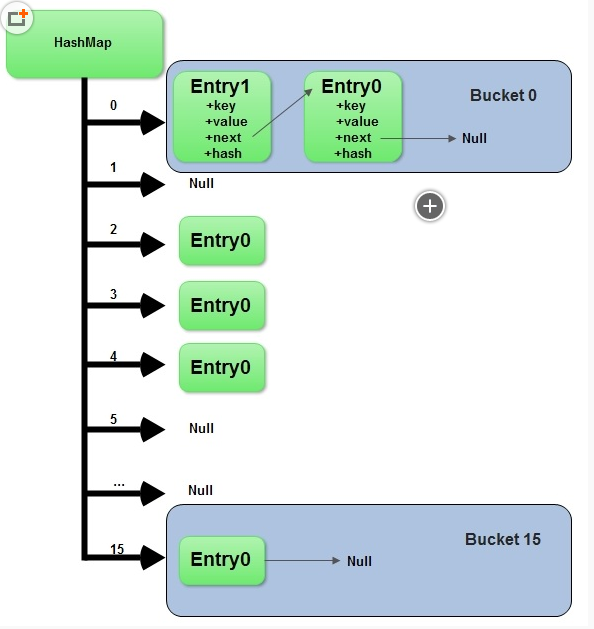
如上图所示,HashMap中元素存储的形式是键-值对(key-value对,即Entry对),所有具有相同hashcode值的键(key)所对应的entry对会被链接起来组成一条链表,而数组的作用则是存储链表中第一个结点的地址值。
二、影响HashMap性能的因素
在HashMap中,还存在着两个概念,桶(buckets)和加载因子(load factor)。
桶(buckets):上图中的标有0、1、2、3、….、11所对应的数组空间就是一个个桶。
加载因子(load factor):是哈希表在其容量自动增加之前可以达到多满的一种尺度,默认值是0.75。
根据源代码中所述,影响HashMap性能有两个因素:哈希表中的初始化容量(桶的数量)和加载因子。当哈希表中条目数超过了当前容量与加载因子的乘积时,哈希表将会作出自我调整,将容量扩充为原来的两倍,并且重新将原有的元素重新映射到表中,这一过程成为rehash。看到这里,相必大家会发现rehash操作是会造成时间与空间的开销的,因此为什么初始化容量与加载因子会影响HashMap的性能也就可以理解了。
代码示例1.添加键-值对的java源代码:
|
1
2
3
4
5
6
|
void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; //找到元素要插入的桶 table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) //threshold的值为当前容量*加载因子(0.75) resize(2 * table.length); //将HashMap的容量扩充为当前容量的两倍 } |
代码示例2.扩充HashMap实例容量源代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; //重新定义新容量的Entry对 transfer(newTable); //rehash操作,将旧表中的元素重新映射到新表中 table = newTable; threshold = (int)(newCapacity * loadFactor);//新的临界值为新的容量*加载因子 } |
三、put/get方法实现原理
put操作:HashMap在进行put操作的时候,会首先调用Key值中的hashCode()方法,用于获取对应的bucket的下标值以便存放数据。具体操作可以参照如下的java源代码:
代码示例3.put方法的java源代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table .length ); for (Entry<K,V> e = table[i]; e != null; e = e. next) { Object k; if (e. hash == hash && ((k = e. key) == key || key.equals(k))) { V oldValue = e. value; e. value = value; e.recordAccess( this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } |
正如上述代码所示,HashMap通过key值的hashcode获得了对应的bucket存储空间的下标,然后进入bucket空间,通过遍历链表比较新插入Key值在链表中是否已存在,如果存在则用新的键-值对替换掉旧值,否则插入新的键-值对。看到这里,相信大家会发现,hashCode值相同的两个值可能是不同的两个对象,而当put进去的是另一个hashCode值相等的对象时,会发生冲突,而在HashMap中解决这种冲突的方法就是将hashCode值相同的key值所对应的key-value对串联成一条链表,请见上面的HashMap数据结构图。
get操作:HashMap在进行get操作的时候,与put方法类似,会首先调用Key值中的hashCode()方法,用于获取对应的bucket的下标值,找到bucket的位置后,再通过key.equals()方法找到对应的键-值对,从而获得对应的value值。java源代码如下:
代码示例4.get方法的java源代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[ indexFor(hash, table.length)]; e != null; e = e. next) { Object k; if (e. hash == hash && ((k = e. key) == key || key.equals(k))) return e. value; } return null;} |
总结:HashMap是基于hashing原理对key-value对进行存储与获取,当使用put()方法添加key-value对时,它会首先检查hashCode的值,并以此获得对应的bucket位置进行存储,当发生冲突时(hashcode值相同的两个不同key),新的key-value对会以结点的形式添加到链表的末尾。而使用get()方法时,同样地会根据key的hashCode值找到相应的bucket位置,再通过key.equals()方法找到对应的key-value对,最终成功获取value值。
详情请参考:http://blog.csdn.net/caihaijiang/article/details/6280251
(转载)HashMap工作原理的更多相关文章
- Java HashMap工作原理及实现
Java HashMap工作原理及实现 2016/03/20 | 分类: 基础技术 | 0 条评论 | 标签: HASHMAP 分享到:3 原文出处: Yikun 1. 概述 从本文你可以学习到: 什 ...
- HashMap工作原理(转载)
转载自:http://www.importnew.com/7099.html HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用Hash ...
- Java HashMap工作原理及实现(转载)
https://yikun.github.io/2015/04/01/Java-HashMap工作原理及实现/
- HashMap工作原理的介绍!
HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间的区别,那么为何这道面试题如此 ...
- HashMap工作原理总结
看了不少关于HaskMap工作原理的博客,下面自己总结记录一下: 1.了解HashMap之前,需要知道Object类的两个方法:hashCode和equals: 默认实现方法: /** JNI,调用底 ...
- 【Java基础】HashMap工作原理
HashMap Hash table based implementation of the Map interface. This implementation provides all of th ...
- HashMap工作原理 和 HashTable
原文链接: Javarevisited 翻译: ImportNew.com - 唐小娟 译文链接: http://www.importnew.com/7099.html 你用过HashMap吗 譬如H ...
- [转载] zookeeper工作原理、安装配置、工具命令简介
转载自http://www.cnblogs.com/kunpengit/p/4045334.html 1 Zookeeper简介Zookeeper 是分布式服务框架,主要是用来解决分布式应用中经常遇到 ...
- [转载] MapReduce工作原理讲解
转载自http://www.aboutyun.com/thread-6723-1-1.html 有时候我们在用,但是却不知道为什么.就像苹果砸到我们头上,这或许已经是很自然的事情了,但是牛顿却发现了地 ...
随机推荐
- CentOS_6.5 64位系统,安装git服务器+客户端
================ git服务器安装 ==================== CentOS安装Git服务器 Centos 6.4 + Git 1.8.2.2 + gitosis## . ...
- 【Linux常用工具】02. 创建启动定时任务工具cron
一. cron 1. cron是一个守护程序,它提供定时器的功能,让用户在特定的时间得以执行默认的指令或程序.只要用户会编辑定时器的设置文件,就可以使用定时器的功能. 定时器文件格式: 2. cron ...
- 语义Web和本体开发相关技术
在技术实现方面,语义Web和本体理论的研究日趋成熟,已经有许多成熟的工具或程序接口,诸如Jena.OWL API等API是系统实现的关键技术.这里介绍系统的可行性分析以及系统开发设计的关键技术. 1 ...
- spark结合 Openfire服务器,发送聊天消息
1.下载OpenFire服务器,进行安装,参考http://www.cnblogs.com/hoojo/archive/2012/05/17/2506769.html 2.程序运行客户端:下载客户端代 ...
- Rstudio编辑界面美化设置
美化Rstudio的编辑界面有利于我们输入代码,合适的调整更是减少错误. 可以根据自己的喜好和习惯选择.
- Squid 日志详解
原文地址: http://www.php-oa.com/2008/01/17/squid-log-access-store.html access.log 日志 在squid中access访问日志最为 ...
- PROCESS_YIELD()宏和C语言的switch语句< contiki学习笔记之七>
写在前面: 按照main()函数的代码一行一行的分析,该是看到了 etimer_process 这个位置.但是etimer_process实现里的一个宏 PROCESS_YIELD()引出了很多故事 ...
- UVa 11234 Expressions (二叉树重建&由叶往根的层次遍历)
画图出来后结果很明显 xyPzwIM abcABdefgCDEF sample output wzyxIPM gfCecbDdAaEBF * + - x y z w F B E a A d D b c ...
- Ubuntu的力量何在?
= 怎样正确评价Ubuntu,这不是一个简单问题.Ubuntu的 力量何在?它的意义何在?这都是须要认真研究的. 实际上,Uuntu 14.04 LTS公布之后,并没有引起预期的热烈反响.这是什么原因 ...
- 【转】python的内存管理机制
http://developer.51cto.com/art/201007/213585.htm 内存管理,对于Python这样的动态语言,是至关重要的一部分,它在很大程度上甚至决定了Python的执 ...