scikit-learn一般实例之八:多标签分类
本例模拟一个多标签文档分类问题.数据集基于下面的处理随机生成:
- 选取标签的数目:泊松(n~Poisson,n_labels)
- n次,选取类别C:多项式(c~Multinomial,theta)
- 选取文档长度:泊松(k~Poisson,length)
- k次,选取一个单词:多项式(w~Multinomial,theta_c)
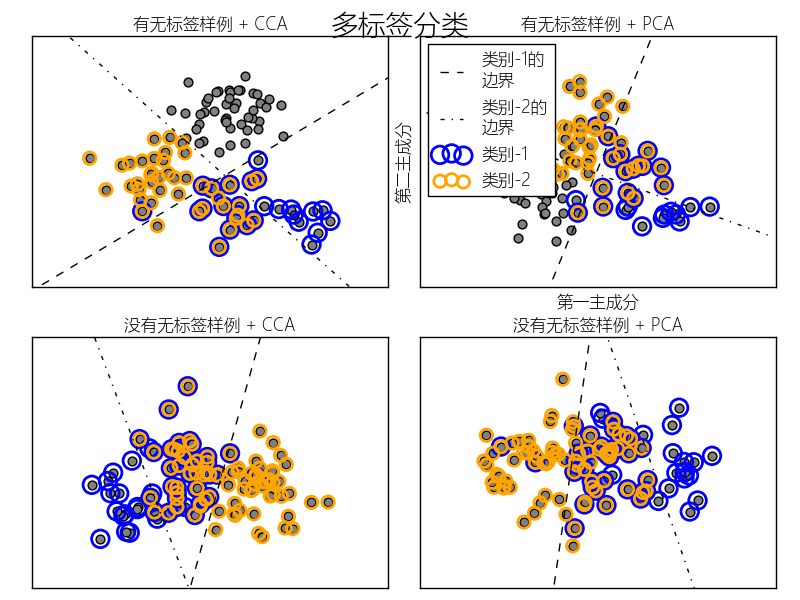
在上面的处理中,拒绝抽样用来确保n大于2,文档长度不为0.同样,我们拒绝已经被选取的类别.被同事分配给两个分类的文档会被两个圆环包围.
通过投影到由PCA和CCA选取进行可视化的前两个主成分进行分类.接着通过元分类器使用两个线性核的SVC来为每个分类学习一个判别模型.注意,PCA用于无监督降维,CCA用于有监督.
注:在下面的绘制中,"无标签样例"不是说我们不知道标签(就像半监督学习中的那样),而是这些样例根本没有标签~~~
# coding:utf-8
import numpy as np
from pylab import *
from sklearn.datasets import make_multilabel_classification
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import LabelBinarizer
from sklearn.decomposition import PCA
from sklearn.cross_decomposition import CCA
myfont = matplotlib.font_manager.FontProperties(fname="Microsoft-Yahei-UI-Light.ttc")
mpl.rcParams['axes.unicode_minus'] = False
def plot_hyperplane(clf, min_x, max_x, linestyle, label):
# 获得分割超平面
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(min_x - 5, max_x + 5) # 确保线足够长
yy = a * xx - (clf.intercept_[0]) / w[1]
plt.plot(xx, yy, linestyle, label=label)
def plot_subfigure(X, Y, subplot, title, transform):
if transform == "pca":
X = PCA(n_components=2).fit_transform(X)
elif transform == "cca":
X = CCA(n_components=2).fit(X, Y).transform(X)
else:
raise ValueError
min_x = np.min(X[:, 0])
max_x = np.max(X[:, 0])
min_y = np.min(X[:, 1])
max_y = np.max(X[:, 1])
classif = OneVsRestClassifier(SVC(kernel='linear'))
classif.fit(X, Y)
plt.subplot(2, 2, subplot)
plt.title(title,fontproperties=myfont)
zero_class = np.where(Y[:, 0])
one_class = np.where(Y[:, 1])
plt.scatter(X[:, 0], X[:, 1], s=40, c='gray')
plt.scatter(X[zero_class, 0], X[zero_class, 1], s=160, edgecolors='b',
facecolors='none', linewidths=2, label=u'类别-1')
plt.scatter(X[one_class, 0], X[one_class, 1], s=80, edgecolors='orange',
facecolors='none', linewidths=2, label=u'类别-2')
plot_hyperplane(classif.estimators_[0], min_x, max_x, 'k--',
u'类别-1的\n边界')
plot_hyperplane(classif.estimators_[1], min_x, max_x, 'k-.',
u'类别-2的\n边界')
plt.xticks(())
plt.yticks(())
plt.xlim(min_x - .5 * max_x, max_x + .5 * max_x)
plt.ylim(min_y - .5 * max_y, max_y + .5 * max_y)
if subplot == 2:
plt.xlabel(u'第一主成分',fontproperties=myfont)
plt.ylabel(u'第二主成分',fontproperties=myfont)
plt.legend(loc="upper left",prop=myfont)
plt.figure(figsize=(8, 6))
X, Y = make_multilabel_classification(n_classes=2, n_labels=1,
allow_unlabeled=True,
random_state=1)
plot_subfigure(X, Y, 1, u"有无标签样例 + CCA", "cca")
plot_subfigure(X, Y, 2, u"有无标签样例 + PCA", "pca")
X, Y = make_multilabel_classification(n_classes=2, n_labels=1,
allow_unlabeled=False,
random_state=1)
plot_subfigure(X, Y, 3, u"没有无标签样例 + CCA", "cca")
plot_subfigure(X, Y, 4, u"没有无标签样例 + PCA", "pca")
plt.subplots_adjust(.04, .02, .97, .94, .09, .2)
plt.suptitle(u"多标签分类", size=20,fontproperties=myfont)
plt.show()
scikit-learn一般实例之八:多标签分类的更多相关文章
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- CVPR2022 | 弱监督多标签分类中的损失问题
前言 本文提出了一种新的弱监督多标签分类(WSML)方法,该方法拒绝或纠正大损失样本,以防止模型记忆有噪声的标签.由于没有繁重和复杂的组件,提出的方法在几个部分标签设置(包括Pascal VOC 20 ...
- CSS.02 -- 样式表 及标签分类(块、行、行内块元素)、CSS三大特性、背景属性
样式表书写位置 内嵌式写法 <head> <style type="text/css"> 样式表写法 </style> </head&g ...
- html(常用标签,标签分类),页面模板, CSS(css的三种引入方式),三种引入方式优先级
HTML 标记语言为非编程语言负责完成页面的结构 组成: 标签:被<>包裹的由字母开头,可以结合合法字符( -|数字 ),能被浏览器解析的特殊符号,标签有头有尾 指令:被<>包 ...
- Python-HTML 最强标签分类
编程: 使用(展示)数据 存储数据 处理数据 前端 1. 前端是做什么的? 2. 我们为什么要学前端? 3. 前端都有哪些内容? 1. HTML 2. CSS 3. JavaScript 4.jQue ...
- 前端 HTML 标签分类
三种: 1.块级标签: 独占一行,可设置宽度,高度.如果设置了宽度和高度,则就是当前的宽高.如果宽度和高度没有设置,宽度是父盒子的宽度,高度根据内容填充. 2.行内标签:在一行内显示,不能设置宽度,高 ...
随机推荐
- Webpack 配置摘要
open-browser-webpack-plugin 自动打开浏览器 html-webpack-plugin 通过 JS 生成 HTML webpack.optimize.UglifyJsPlugi ...
- git亲测命令
一.Git新建本地分支与远程分支关联问题 git checkout -b branch_name origin/branch_name 或者 git branch --set-upstream bra ...
- SQL Server-聚焦在视图和UDF中使用SCHEMABINDING(二十六)
前言 上一节我们讨论了视图中的一些限制以及建议等,这节我们讲讲关于在UDF和视图中使用SCHEMABINDING的问题,简短的内容,深入的理解,Always to review the basics. ...
- Node.js:dgram模块实现UDP通信
1.什么是UDP? 这里简单介绍下,UDP,即用户数据报协议,一种面向无连接的传输层协议,提供不可靠的消息传送服务.UDP协议使用端口号为不同的应用保留其各自的数据传输通道,这一点非常重要.与TCP相 ...
- CRL快速开发框架系列教程十(导出对象结构)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- MyBatis源码分析(二)语句处理器
StatementHandler 语句处理器,主要负责语句的创建.参数的设置.语句的执行.不负责结果集的处理. Statement prepare(Connection connection, Int ...
- css3更改input单选和多选的样式
在项目开发中我们经常会遇到需要更改input单选和多选样式的情况,今天就给大家介绍一种简单改变input单选和多选样式的办法. 在这之前先简单介绍一下:before伪类 :before 选择器向选定的 ...
- 排序算法----基数排序(RadixSort(L))单链表智能版本
转载http://blog.csdn.net/Shayabean_/article/details/44885917博客 先说说基数排序的思想: 基数排序是非比较型的排序算法,其原理是将整数按位数切割 ...
- Android Weekly Notes Issue #231
Android Weekly Issue #231 November 13th, 2016 Android Weekly Issue #231 Android Weekly阅读笔记, Issue #2 ...
- IL指令详细表
名称 说明 Add 将两个值相加并将结果推送到计算堆栈上. Add.Ovf 将两个整数相加,执行溢出检查,并且将结果推送到计算堆栈上. Add.Ovf.Un 将两个无符号整数值相加,执行溢出检查,并且 ...