A geometric interpretation of the covariance matrix
A geometric interpretation of the covariance matrix
Contents [hide]
Introduction
In this article, we provide an intuitive, geometric interpretation of the covariance matrix, by exploring the relation between linear transformations and the resulting data covariance. Most textbooks explain the shape of data based on the concept of covariance matrices. Instead, we take a backwards approach and explain the concept of covariance matrices based on the shape of data.
In a previous article, we discussed the concept of variance, and provided a derivation and proof of the well known formula to estimate the sample variance. Figure 1 was used in this article to show that the standard deviation, as the square root of the variance, provides a measure of how much the data is spread across the feature space.
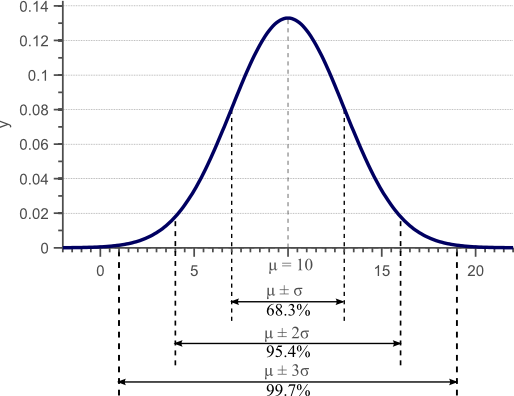
Figure 1. Gaussian density function. For normally distributed data, 68% of the samples fall within the interval defined by the mean plus and minus the standard deviation.
We showed that an unbiased estimator of the sample variance can be obtained by:
(1) 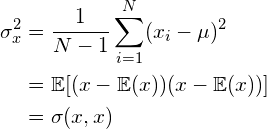
However, variance can only be used to explain the spread of the data in the directions parallel to the axes of the feature space. Consider the 2D feature space shown by figure 2:
Figure 2. The diagnoal spread of the data is captured by the covariance.
For this data, we could calculate the variance 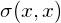 in the x-direction and the variance
in the x-direction and the variance 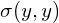 in the y-direction. However, the horizontal spread and the vertical spread of the data does not explain the clear diagonal correlation. Figure 2 clearly shows that on average, if the x-value of a data point increases, then also the y-value increases, resulting in a positive correlation. This correlation can be captured by extending the notion of variance to what is called the ‘covariance’ of the data:
in the y-direction. However, the horizontal spread and the vertical spread of the data does not explain the clear diagonal correlation. Figure 2 clearly shows that on average, if the x-value of a data point increases, then also the y-value increases, resulting in a positive correlation. This correlation can be captured by extending the notion of variance to what is called the ‘covariance’ of the data:
(2) 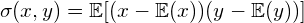
For 2D data, we thus obtain , , 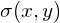 and
and 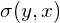 . These four values can be summarized in a matrix, called the covariance matrix:
. These four values can be summarized in a matrix, called the covariance matrix:
(3) 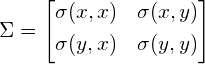
If x is positively correlated with y, y is also positively correlated with x. In other words, we can state that 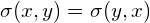 . Therefore, the covariance matrix is always a symmetric matrix with the variances on its diagonal and the covariances off-diagonal. Two-dimensional normally distributed data is explained completely by its mean and its
. Therefore, the covariance matrix is always a symmetric matrix with the variances on its diagonal and the covariances off-diagonal. Two-dimensional normally distributed data is explained completely by its mean and its 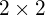 covariance matrix. Similarly, a
covariance matrix. Similarly, a 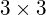 covariance matrix is used to capture the spread of three-dimensional data, and a
covariance matrix is used to capture the spread of three-dimensional data, and a 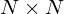 covariance matrix captures the spread of N-dimensional data.
covariance matrix captures the spread of N-dimensional data.
Figure 3 illustrates how the overall shape of the data defines the covariance matrix:
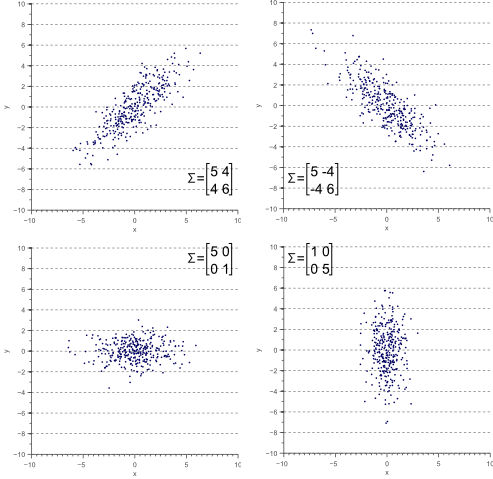
Figure 3. The covariance matrix defines the shape of the data. Diagonal spread is captured by the covariance, while axis-aligned spread is captured by the variance.
Eigendecomposition of a covariance matrix
In the next section, we will discuss how the covariance matrix can be interpreted as a linear operator that transforms white data into the data we observed. However, before diving into the technical details, it is important to gain an intuitive understanding of how eigenvectors and eigenvalues uniquely define the covariance matrix, and therefore the shape of our data.
As we saw in figure 3, the covariance matrix defines both the spread (variance), and the orientation (covariance) of our data. So, if we would like to represent the covariance matrix with a vector and its magnitude, we should simply try to find the vector that points into the direction of the largest spread of the data, and whose magnitude equals the spread (variance) in this direction.
If we define this vector as  , then the projection of our data
, then the projection of our data  onto this vector is obtained as
onto this vector is obtained as  , and the variance of the projected data is
, and the variance of the projected data is 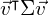 . Since we are looking for the vector that points into the direction of the largest variance, we should choose its components such that the covariance matrix of the projected data is as large as possible. Maximizing any function of the form with respect to , where is a normalized unit vector, can be formulated as a so called Rayleigh Quotient. The maximum of such a Rayleigh Quotient is obtained by setting equal to the largest eigenvector of matrix
. Since we are looking for the vector that points into the direction of the largest variance, we should choose its components such that the covariance matrix of the projected data is as large as possible. Maximizing any function of the form with respect to , where is a normalized unit vector, can be formulated as a so called Rayleigh Quotient. The maximum of such a Rayleigh Quotient is obtained by setting equal to the largest eigenvector of matrix 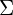 .
.
In other words, the largest eigenvector of the covariance matrix always points into the direction of the largest variance of the data, and the magnitude of this vector equals the corresponding eigenvalue. The second largest eigenvector is always orthogonal to the largest eigenvector, and points into the direction of the second largest spread of the data.
Now let’s have a look at some examples. In an earlier article we saw that a linear transformation matrix 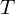 is completely defined by itseigenvectors and eigenvalues. Applied to the covariance matrix, this means that:
is completely defined by itseigenvectors and eigenvalues. Applied to the covariance matrix, this means that:
(4) 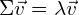
where is an eigenvector of , and 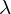 is the corresponding eigenvalue.
is the corresponding eigenvalue.
If the covariance matrix of our data is a diagonal matrix, such that the covariances are zero, then this means that the variances must be equal to the eigenvalues . This is illustrated by figure 4, where the eigenvectors are shown in green and magenta, and where the eigenvalues clearly equal the variance components of the covariance matrix.
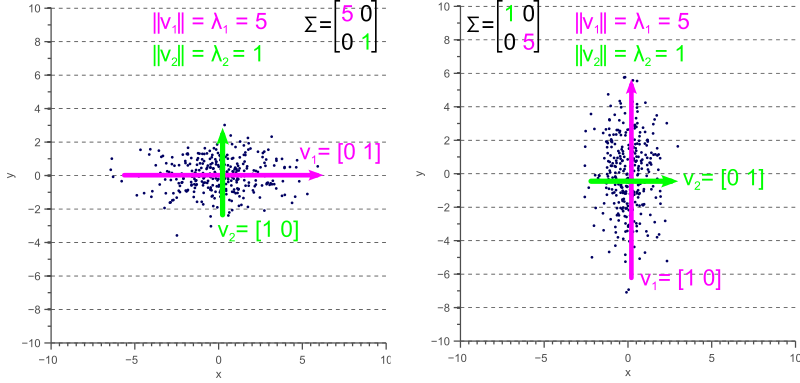
Figure 4. Eigenvectors of a covariance matrix
However, if the covariance matrix is not diagonal, such that the covariances are not zero, then the situation is a little more complicated. The eigenvalues still represent the variance magnitude in the direction of the largest spread of the data, and the variance components of the covariance matrix still represent the variance magnitude in the direction of the x-axis and y-axis. But since the data is not axis aligned, these values are not the same anymore as shown by figure 5.
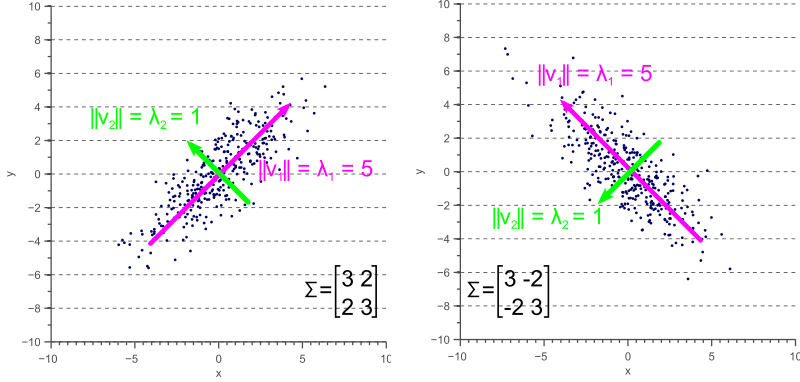
Figure 5. Eigenvalues versus variance
By comparing figure 5 with figure 4, it becomes clear that the eigenvalues represent the variance of the data along the eigenvector directions, whereas the variance components of the covariance matrix represent the spread along the axes. If there are no covariances, then both values are equal.
Covariance matrix as a linear transformation
Now let’s forget about covariance matrices for a moment. Each of the examples in figure 3 can simply be considered to be a linearly transformed instance of figure 6:
Figure 6. Data with unit covariance matrix is called white data.
Let the data shown by figure 6 be , then each of the examples shown by figure 3 can be obtained by linearly transforming :
(5) 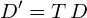
where is a transformation matrix consisting of a rotation matrix 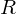 and a scaling matrix
and a scaling matrix 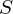 :
:
(6) 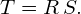
These matrices are defined as:
(7) 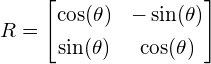
where 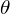 is the rotation angle, and:
is the rotation angle, and:
(8) 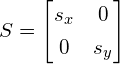
where 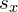 and
and 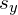 are the scaling factors in the x direction and the y direction respectively.
are the scaling factors in the x direction and the y direction respectively.
In the following paragraphs, we will discuss the relation between the covariance matrix , and the linear transformation matrix 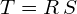 .
.
Let’s start with unscaled (scale equals 1) and unrotated data. In statistics this is often refered to as ‘white data’ because its samples are drawn from a standard normal distribution and therefore correspond to white (uncorrelated) noise:
Figure 7. White data is data with a unit covariance matrix.
The covariance matrix of this ‘white’ data equals the identity matrix, such that the variances and standard deviations equal 1 and the covariance equals zero:
(9) 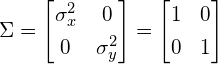
Now let’s scale the data in the x-direction with a factor 4:
(10) 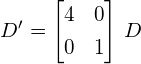
The data 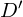 now looks as follows:
now looks as follows:
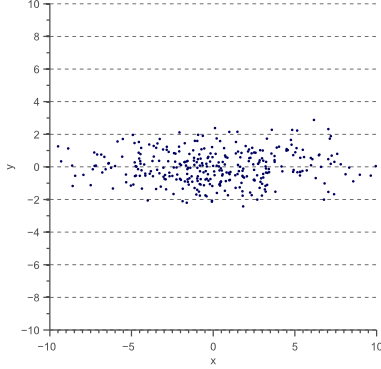
Figure 8. Variance in the x-direction results in a horizontal scaling.
The covariance matrix 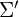 of is now:
of is now:
(11) 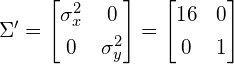
Thus, the covariance matrix of the resulting data is related to the linear transformation that is applied to the original data as follows: 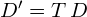 , where
, where
(12) 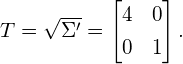
However, although equation (12) holds when the data is scaled in the x and y direction, the question rises if it also holds when a rotation is applied. To investigate the relation between the linear transformation matrix and the covariance matrix in the general case, we will therefore try to decompose the covariance matrix into the product of rotation and scaling matrices.
As we saw earlier, we can represent the covariance matrix by its eigenvectors and eigenvalues:
(13)
where is an eigenvector of , and is the corresponding eigenvalue.
Equation (13) holds for each eigenvector-eigenvalue pair of matrix . In the 2D case, we obtain two eigenvectors and two eigenvalues. The system of two equations defined by equation (13) can be represented efficiently using matrix notation:
(14) 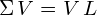
where 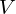 is the matrix whose columns are the eigenvectors of and
is the matrix whose columns are the eigenvectors of and 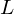 is the diagonal matrix whose non-zero elements are the corresponding eigenvalues.
is the diagonal matrix whose non-zero elements are the corresponding eigenvalues.
This means that we can represent the covariance matrix as a function of its eigenvectors and eigenvalues:
(15) 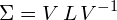
Equation (15) is called the eigendecomposition of the covariance matrix and can be obtained using a Singular Value Decompositionalgorithm. Whereas the eigenvectors represent the directions of the largest variance of the data, the eigenvalues represent the magnitude of this variance in those directions. In other words, represents a rotation matrix, while 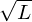 represents a scaling matrix. The covariance matrix can thus be decomposed further as:
represents a scaling matrix. The covariance matrix can thus be decomposed further as:
(16) 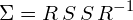
where 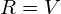 is a rotation matrix and
is a rotation matrix and 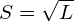 is a scaling matrix.
is a scaling matrix.
In equation (6) we defined a linear transformation 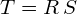 . Since is a diagonal scaling matrix,
. Since is a diagonal scaling matrix,  . Furthermore, since is an orthogonal matrix,
. Furthermore, since is an orthogonal matrix, 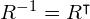 . Therefore,
. Therefore, 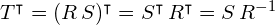 . The covariance matrix can thus be written as:
. The covariance matrix can thus be written as:
(17) 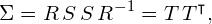
In other words, if we apply the linear transformation defined by to the original white data shown by figure 7, we obtain the rotated and scaled data with covariance matrix 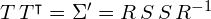 . This is illustrated by figure 10:
. This is illustrated by figure 10:
Figure 10. The covariance matrix represents a linear transformation of the original data.
The colored arrows in figure 10 represent the eigenvectors. The largest eigenvector, i.e. the eigenvector with the largest corresponding eigenvalue, always points in the direction of the largest variance of the data and thereby defines its orientation. Subsequent eigenvectors are always orthogonal to the largest eigenvector due to the orthogonality of rotation matrices.
Conclusion
In this article we showed that the covariance matrix of observed data is directly related to a linear transformation of white, uncorrelated data. This linear transformation is completely defined by the eigenvectors and eigenvalues of the data. While the eigenvectors represent the rotation matrix, the eigenvalues correspond to the square of the scaling factor in each dimension.
If you’re new to this blog, don’t forget to subscribe, or follow me on twitter!
A geometric interpretation of the covariance matrix的更多相关文章
- What is an eigenvector of a covariance matrix?
What is an eigenvector of a covariance matrix? One of the most intuitive explanations of eigenvector ...
- 方差variance, 协方差covariance, 协方差矩阵covariance matrix
https://www.jianshu.com/p/e1c8270477bc?utm_campaign=maleskine&utm_content=note&utm_medium=se ...
- 方差variance, 协方差covariance, 协方差矩阵covariance matrix | scatter matrix | weighted covariance | Eigenvalues and eigenvectors
covariance, co本能的想到双变量,用于描述两个变量之间的关系. correlation,相关性,covariance标准化后就是correlation. covariance的定义: 期望 ...
- covariance matrix 和数据分布情况估计
how to get data covariance matrix: http://stattrek.com/matrix-algebra/covariance-matrix.aspx meaning ...
- 图Lasso求逆协方差矩阵(Graphical Lasso for inverse covariance matrix)
图Lasso求逆协方差矩阵(Graphical Lasso for inverse covariance matrix) 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/ka ...
- 随机变量的方差variance & 随机向量的协方差矩阵covariance matrix
1.样本矩阵 如果是一个随机变量,那么它的样本值可以用一个向量表示.相对的,如果针对一个随机向量,那么就需要利用矩阵表示,因为向量中的每一个变量的采样值,都可以利用一个向量表示. 然后,一个矩阵可以利 ...
- A Beginner’s Guide to Eigenvectors, PCA, Covariance and Entropy
A Beginner’s Guide to Eigenvectors, PCA, Covariance and Entropy Content: Linear Transformations Prin ...
- Ill-conditioned covariance create
http://www.mathworks.com/matlabcentral/answers/100210-why-do-i-receive-an-error-while-trying-to-gene ...
- 协方差(Covariance)
统计学上用方差和标准差来度量数据的离散程度 ,但是方差和标准差是用来描述一维数据的(或者说是多维数据的一个维度),现实生活中我们常常会碰到多维数据,因此人们发明了协方差(covariance),用来度 ...
随机推荐
- 和阿文一起学H5--如何把H5压缩到最小
三种压缩图片的方法: 1.PS 但是PS每次只能压缩一张,下面介绍第二个神器 2.TinyPng压缩 https://tinypng.com/ 3.IloveIMG压缩 http://www.ilov ...
- .net转java了
公司技术部门 要求.net全体转向java 本来要看看.net core的 看来是没必要了 现在国内互联网公司.net是越来越少 不知道为何会这样 不过java的生态圈 确实是很强大 也很丰富 ...
- WCF学习笔记 -- 如何用C#开发一个WebService
假设所有工程的命名空间是demo. 新建一个C#的ClassLibrary(类库)工程. 在工程引用中加入System.ServiceModel引用. 定义接口,你可以删除自动生成的代码,或者直接修改 ...
- js画了一个椭圆
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Page 的生命周期学习小结(翻译兼笔记)
初始化(Initialization) 页面被请求时,第一个被执行的总是下面接着执行的是 接着是 然后是 恢复和加载(Restore and Load) 接下来的 ViewState 被取回后,接着 ...
- Amoeba相关产品及其介绍
Amoeba for MySQL Amoeba for MySQL致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当query 路由功能,专注 分布式数据库 ...
- 暑假集训(5)第二弹———湫湫系列故事——减肥记I(hdu4508)
问题描述:舔了舔嘴上的油渍,你陷在身后柔软的靠椅上.在德源大赛中获得优胜的你,迫不及待地赶到“吃到饱”饭店吃到饱.当你 正准备离开时,服务员叫住了你,“先生,您还没有吃完你所点的酒菜.”指着你桌上的一 ...
- Adobe Illustrator CS6 绿色简体中文版下载地址
一.Adobe Illustrator CS6 简体中文精简绿色优化版:1.由官方简体中文正式版制作而成,只需要执行一次快速安装即可使用.已经注册,非tryout版,支持x64位系统.2.精简了Ext ...
- zabbix短信网关调用问题总结
在写调用短信网关的shell脚本的时候,发现了一个百思不得其解的问题,用浏览器访问短信接口地址是可以成功接收到短信的.但在shell 里面调用就报错了!!!在反复测试当中发现,在shell 中对特殊字 ...
- Hibernate的单向OneToMany、单向ManyToOne
单向OneToMany 一个用户有多张照片,User----->Images是一对多关系,在数据库中Images维护一个外键useid 1.在映射关系的主控方Image这边,我们什么都不做.(为 ...