【CCL】连通区域提取
根据朋友给的一份原理写的 感觉还挺清楚
#include "cv.h"
#include "highgui.h"
#include <stdio.h>
using namespace cv; #define MAXWIDTH 352
#define MAXHEIGHT 288 typedef struct PTNode{
int data;
int parent;
}PTNode; void GetCCL(Mat &imgsrc, Mat &imgdst)
{ PTNode nodes[MAXWIDTH * MAXHEIGHT]; //线性树 数据的位置 与 数据本身 相同 即 nodes[x].data = x
memset(nodes, , MAXWIDTH * MAXHEIGHT * sizeof(PTNode));
int nodenum = ;
int row, col;
nodes[].data = ;
nodes[].parent = -;
for(row = ; row < imgsrc.rows; row++)
{
for(col = ; col < imgsrc.cols; col++)
{
if(imgsrc.at<uchar>(row, col) == ) //像素为0的认为是背景 全黑色
{
imgdst.at<uchar>(row, col) = ;
}
else //前景
{
if(row != && col != ) //不是边界
{
if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row, col - )) // 判断 先左 后上
{
imgdst.at<uchar>(row, col) = imgdst.at<uchar>(row, col - ); //如果和左边相同 标号和左边相同
if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row - , col) && imgdst.at<uchar>(row, col) != imgdst.at<uchar>(row - , col)) //同时与左边 上边相连 且两个序号不同
{
imgdst.at<uchar>(row, col) = (imgdst.at<uchar>(row, col) > imgdst.at<uchar>(row - , col)) ? imgdst.at<uchar>(row - , col) : imgdst.at<uchar>(row, col); //取小的编号 PTNode nodetmp1, nodetmp2;
nodetmp1 = nodes[imgdst.at<uchar>(row, col - )];
nodetmp2 = nodes[imgdst.at<uchar>(row - , col)];
while(nodetmp1.parent != -)
{
nodetmp1 = nodes[nodetmp1.parent];
}
while(nodetmp2.parent != -)
{
nodetmp2 = nodes[nodetmp2.parent];
}
if(nodetmp2.data > nodetmp1.data) //小的序号做parent 大序号做child
{
nodes[nodetmp2.data].parent = nodetmp1.data; //这里一定要对nodes中的值修改, 直接写nodetmp2.parent = nodetmp1.data 是不行的因为nodetmp2只是一个局部变量 nodes[]里的值根本没有修改
}
else if(nodetmp2.data < nodetmp1.data)
{
nodes[nodetmp1.data].parent = nodetmp2.data;
} }
}
else if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row - , col)) //仅与上面相同 序号等于上面
{
imgdst.at<uchar>(row, col) = imgdst.at<uchar>(row - , col);
}
else //与两个方向的序号都不同 新建一个序号 序号与位置相同
{
nodenum++;
imgdst.at<uchar>(row, col) = nodenum;
nodes[imgdst.at<uchar>(row, col)].parent = -;
nodes[imgdst.at<uchar>(row, col)].data = imgdst.at<uchar>(row, col);
}
}
else if(row == && col != ) //横向边界
{
if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row, col - ))
{
imgdst.at<uchar>(row, col) = imgdst.at<uchar>(row, col - );
}
else
{
nodenum++;
imgdst.at<uchar>(row, col) = nodenum;
nodes[imgdst.at<uchar>(row, col)].parent = -;
nodes[imgdst.at<uchar>(row, col)].data = imgdst.at<uchar>(row, col);
}
}
else if(col == && row != ) //竖向边界
{
if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row - , col))
{
imgdst.at<uchar>(row, col) = imgdst.at<uchar>(row - , col);
}
else
{
nodenum++;
imgdst.at<uchar>(row, col) = nodenum;
nodes[imgdst.at<uchar>(row, col)].parent = -;
nodes[imgdst.at<uchar>(row, col)].data = imgdst.at<uchar>(row, col);
}
}
else //开始的(0 ,0)点 直接新建
{
nodenum++;
imgdst.at<uchar>(row, col) = nodenum;
nodes[imgdst.at<uchar>(row, col)].parent = -;
nodes[imgdst.at<uchar>(row, col)].data = imgdst.at<uchar>(row, col);
}
} }
} //FILE * out = fopen("D:\\dst.txt", "w");
//for(row = 0; row < imgsrc.rows; row++)
//{
// for(col = 0; col < imgsrc.cols; col++)
// {
// fprintf(out, "%d ", imgdst.at<uchar>(row, col));
// }
// fprintf(out, "\n");
//}
//把森林中每一个颗树都标成统一的颜色
for(row = ; row < imgsrc.rows; row++)
{
for(col = ; col < imgsrc.cols; col++)
{
PTNode nodetmp = nodes[imgdst.at<uchar>(row, col)];
while(nodetmp.parent != -)
{
nodetmp = nodes[nodetmp.parent];
}
imgdst.at<uchar>(row, col) = nodetmp.data * % ; //随意设个颜色显示
}
} } void main()
{
IplImage* img = cvLoadImage("D:\\Users\\CCL\\1.jpg", );
IplImage* imgdst = cvCreateImage(cvGetSize(img), , );
cvThreshold(img,img,,,);
cvShowImage("ori", img);
Mat src(img), dst(imgdst);
GetCCL(src, dst);
cvShowImage("ccl", imgdst);
cvWaitKey();
}
效果:
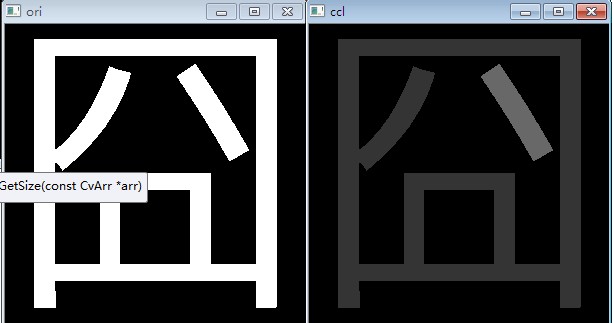
但是下面的图片出了问题:
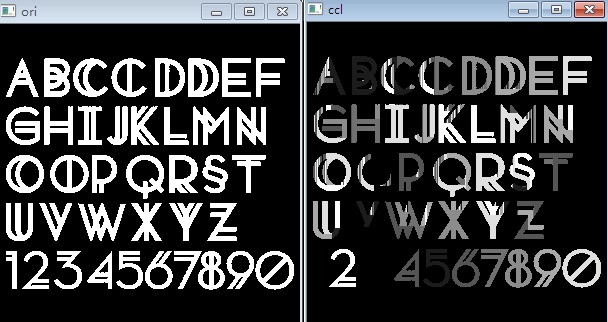
字母检测的很凌乱
但是单独把一个字母拿出来 放大再检测就ok

找到上面多字母问题的原因了。问题出在下面一句:
imgdst.at<uchar>(row, col) = nodenum;
这里nodenum是可能超过255的 但是在传给imgdst时被强制转换成了uchar型,导致后面的结果出错。
用tmp.create(imgsrc.rows, imgsrc.cols, CV_32F);来修改错误。
修改后的代码如下:
#include "cv.h"
#include "highgui.h"
#include <stdio.h>
using namespace cv; #define MAXWIDTH 352
#define MAXHEIGHT 288 typedef struct PTNode{
int data;
int parent;
}PTNode; void GetCCL(Mat &imgsrc, Mat &imgdst)
{
Mat tmp;
tmp.create(imgsrc.rows, imgsrc.cols, CV_32F);
PTNode nodes[MAXWIDTH * MAXHEIGHT]; //线性树 数据的位置 与 数据本身 相同 即 nodes[x].data = x
memset(nodes, , MAXWIDTH * MAXHEIGHT * sizeof(PTNode));
int nodenum = ;
int row, col;
nodes[].data = ;
nodes[].parent = -;
for(row = ; row < imgsrc.rows; row++)
{
for(col = ; col < imgsrc.cols; col++)
{
if(imgsrc.at<uchar>(row, col) == ) //像素为0的认为是背景 全黑色
{
tmp.at<int>(row, col) = ;
}
else //前景
{
if(row != && col != ) //不是边界
{
if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row, col - )) // 判断 先左 后上
{
tmp.at<int>(row, col) = tmp.at<int>(row, col - ); //如果和左边相同 标号和左边相同
if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row - , col) && tmp.at<int>(row, col) != tmp.at<int>(row - , col)) //同时与左边 上边相连 且两个序号不同
{
tmp.at<int>(row, col) = (tmp.at<int>(row, col) > tmp.at<int>(row - , col)) ? tmp.at<int>(row - , col) : tmp.at<int>(row, col); //取小的编号 PTNode nodetmp1, nodetmp2;
nodetmp1 = nodes[tmp.at<int>(row, col - )];
nodetmp2 = nodes[tmp.at<int>(row - , col)];
while(nodetmp1.parent != -)
{
nodetmp1 = nodes[nodetmp1.parent];
}
while(nodetmp2.parent != -)
{
nodetmp2 = nodes[nodetmp2.parent];
}
if(nodetmp2.data > nodetmp1.data) //小的序号做parent 大序号做child
{
nodes[nodetmp2.data].parent = nodetmp1.data; //这里一定要对nodes中的值修改, 直接写nodetmp2.parent = nodetmp1.data 是不行的因为nodetmp2只是一个局部变量 nodes[]里的值根本没有修改
}
else if(nodetmp2.data < nodetmp1.data)
{
nodes[nodetmp1.data].parent = nodetmp2.data;
} }
}
else if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row - , col)) //仅与上面相同 序号等于上面
{
tmp.at<int>(row, col) = tmp.at<int>(row - , col);
}
else //与两个方向的序号都不同 新建一个序号 序号与位置相同
{
nodenum++;
tmp.at<int>(row, col) = nodenum;
nodes[tmp.at<int>(row, col)].parent = -;
nodes[tmp.at<int>(row, col)].data = tmp.at<int>(row, col);
}
}
else if(row == && col != ) //横向边界
{
if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row, col - ))
{
tmp.at<int>(row, col) = tmp.at<int>(row, col - );
}
else
{
nodenum++;
tmp.at<int>(row, col) = nodenum; //这里有问题, nodenum可能会大于255 但是传给tmp.at<int>(row, col) 时被转换为uchar型
nodes[tmp.at<int>(row, col)].parent = -;
nodes[tmp.at<int>(row, col)].data = tmp.at<int>(row, col);
}
}
else if(col == && row != ) //竖向边界
{
if(imgsrc.at<uchar>(row, col) == imgsrc.at<uchar>(row - , col))
{
tmp.at<int>(row, col) = tmp.at<int>(row - , col);
}
else
{
nodenum++;
tmp.at<int>(row, col) = nodenum;
nodes[tmp.at<int>(row, col)].parent = -;
nodes[tmp.at<int>(row, col)].data = tmp.at<int>(row, col);
}
}
else //开始的(0 ,0)点 直接新建
{
nodenum++;
tmp.at<int>(row, col) = nodenum;
nodes[tmp.at<int>(row, col)].parent = -;
nodes[tmp.at<int>(row, col)].data = tmp.at<int>(row, col);
}
} }
} //FILE * out = fopen("D:\\dst.txt", "w");
//for(row = 0; row < imgsrc.rows; row++)
//{
// for(col = 0; col < imgsrc.cols; col++)
// {
// fprintf(out, "%d ", tmp.at<int>(row, col));
// }
// fprintf(out, "\n");
//}
//把森林中每一个颗树都标成统一的颜色
for(row = ; row < imgsrc.rows; row++)
{
for(col = ; col < imgsrc.cols; col++)
{
PTNode nodetmp = nodes[tmp.at<int>(row, col)];
while(nodetmp.parent != -)
{
nodetmp = nodes[nodetmp.parent];
}
imgdst.at<uchar>(row, col) = nodetmp.data * % ; //随意设个颜色显示
}
} } void main()
{
IplImage* img = cvLoadImage("D:\\Users\\2.jpg", );
IplImage* imgdst = cvCreateImage(cvGetSize(img), , );
cvThreshold(img,img,,,);
cvNot(img, img);
cvShowImage("ori", img);
Mat src(img), dst(imgdst);
GetCCL(src, dst);
cvShowImage("ccl", imgdst);
cvWaitKey();
}
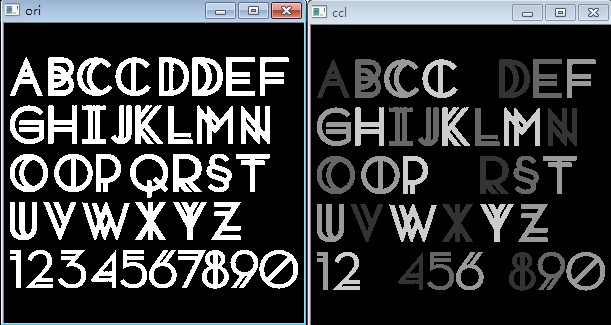
修正后结果就好了。有几个字母看起来像是丢了,其实是因为我随机选颜色,可能导致用黑色填充。
【CCL】连通区域提取的更多相关文章
- Opencv2系列学习笔记10(提取连通区域轮廓)
连通区域指的是二值图像中相连像素组成的形状.而内.外轮廓的概念及opencv1中如何提取二值图像的轮廓见我的这篇博客:http://blog.csdn.net/lu597203933/article/ ...
- Opencv2系列学习笔记10(提取连通区域轮廓) 另一个
http://blog.csdn.net/lu597203933/article/details/17362457 连通区域指的是二值图像中相连像素组成的形状.而内.外轮廓的概念及opencv1中如何 ...
- [LeetCode] Number of Connected Components in an Undirected Graph 无向图中的连通区域的个数
Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair of nodes), ...
- 使用OpenCV查找二值图中最大连通区域
http://blog.csdn.net/shaoxiaohu1/article/details/40272875 使用OpenCV查找二值图中最大连通区域 标签: OpenCVfindCoutour ...
- OpenCV:二值图像连通区域分析与标记算法实现
http://blog.csdn.net/cooelf/article/details/26581539?utm_source=tuicool&utm_medium=referral Open ...
- ARCGIS API for Python进行城市区域提取
ArcGIS API for Python主要用于Web端的扩展和开发,提供简单易用.功能强大的Python库,以及大数据分析能力,可轻松实现实时数据.栅格数据.空间数据等多源数据的接入和GIS分析 ...
- 《图像处理实例》 之 目标旋转矫正(基于区域提取、DFT变换)
目标:1.把矩形旋转正. 2.把文字旋转校正. ...
- matlab函数_连通区域
1. matlab函数bwareaopen──删除小面积对象格式:BW2 = bwareaopen(BW,P,conn)作用:删除二值图像BW中面积小于P的对象,默认情况下使用8邻域.算法:(1)De ...
- 【转】matlab函数_连通区域
转载自einyboy的博文Matlab的regionprops详解 1. matlab函数bwareaopen──删除小面积对象格式:BW2 = bwareaopen(BW,P,conn)作用:删除二 ...
随机推荐
- NLPIR_Init文本分词-总是初始化失败,false,Init ICTCLAS failed!
前段时间用这个分词用的好好的,突然间就总是初始化失败了: 网上搜了很多,但是不是我想要的答案,最终去了官网看了下:官网链接 发现哇,版本更新了啊,下载页面链接 麻利的下载好了最新的文档,一看压缩包名字 ...
- iOS创建子工程
实际开发中,我们可能会同时开发好几个端,比如楼主目前开发的家教平台,需要老师端,家长端,助教端三个端.有很多工具方法,或者封装的自定义控件都是可以复用的.我们就可以把公用的代码抽取出去,新建一个工程, ...
- 欧几里得证明$\sqrt{2}$是无理数
选自<费马大定理:一个困惑了世间智者358年的谜>,有少许改动. 原译者:薛密 \(\sqrt{2}\)是无理数,即不能写成一个分数.欧几里得以反证法证明此结论.第一步是假定相反的事实是真 ...
- PHP团队 编码规范 & 代码样式风格规范
一.基本约定 1.源文件 (1).纯PHP代码源文件只使用 <?php 标签,省略关闭标签 ?> : (2).源文件中PHP代码的编码格式必须是无BOM的UTF-8格式: (3).使用 U ...
- scanf函数与输入缓冲区
本文链接:http://www.cnblogs.com/xxNote/p/4008668.html 今天看书的时候遇到scanf函数与缓冲区的问题,产生了一些猜想即:应该有一个指针来记录缓冲区中读取到 ...
- Code First04---关于上下文DbContext
这章主要讲怎么配置DbContext的子类访问的数据库的位置. 我相信大家最经常使用的数据库位置的配置方式就是配置文件了,也就是通过App.Config 或Web.Config来配置要访问的数据库. ...
- javaweb 解决将ajax返回的内容用document.write写入,FireFox一直加载的问题
在document.write方法后加上document.close就解决了, 想知道原理的小伙伴可以继续看 浏览器在解析html时会打开一个流,这是用document.write中写入,是加入当解析 ...
- Android开源项目(二)
第二部分 工具库 主要包括那些不错的开发库,包括依赖注入框架.图片缓存.网络相关.数据库ORM建模.Android公共库.Android 高版本向低版本兼容.多媒体相关及其他. 一.依赖注入DI 通过 ...
- iOS开发——多线程篇——快速生成沙盒目录的路径,多图片下载的原理、SDWebImage框架的简单介绍
一.快速生成沙盒目录的路径 沙盒目录的各个文件夹功能 - Documents - 需要保存由"应用程序本身"产生的文件或者数据,例如:游戏进度.涂鸦软件的绘图 - 目录中的文件会被 ...
- python文件头的#-*- coding: utf-8 -*- 的作用
这一句其实是告诉编辑器,我的代码使用的格式是utf-8,如果没有这句编辑器就会自动去识别代码的文件格式,如果发现文件格式不是utf-8,就有可能去将编码格式转换为utf-8,比如本来是gbk的,编辑器 ...