MMAP和DIRECT IO区别【转】
转自:http://www.cnblogs.com/zhaoyl/p/5901680.html
看完此文,题目不言自明。转自 http://blog.chinaunix.net/uid-27105712-id-3270102.html
在Linux 开发中,有几个关系到性能的东西,技术人员非常关注:进程,CPU,MEM,网络IO,磁盘IO。本篇文件打算详细全面,深入浅出。剖析文件IO的细节。从多个角度探索如何提高IO性能。本文尽量用通俗易懂的视角去阐述。不copy内核代码。
阐述之前,要先有个大视角,让我们站在万米高空,鸟瞰我们的文件IO,它们设计是分层的,分层有2个好处,一是架构清晰,二是解耦。让我们看一下下面这张图。
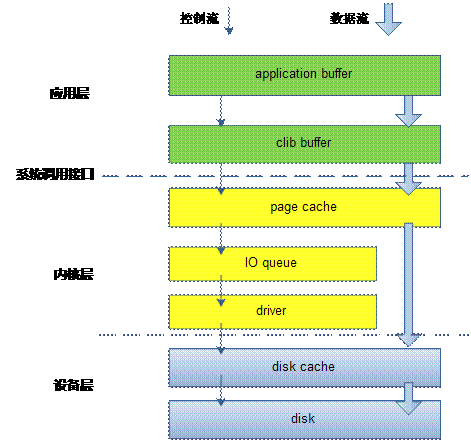
1. 穿越各层写文件方式
程序的最终目的是要把数据写到磁盘上, 但是系统从通用性和性能角度,尽量提供一个折中的方案来保证这些。让我们来看一个最常用的写文件典型example,也是路径最长的IO。
{
char *buf = malloc(MAX_BUF_SIZE);
strncpy(buf, src, , MAX_BUF_SIZE);
fwrite(buf, MAX_BUF_SIZE, 1, fp);
fclose(fp);
}
这里malloc的buf对于图层中的application buffer,即应用程序的buffer;调用fwrite后,把数据从application buffer 拷贝到了 CLib buffer,即C库标准IObuffer。fwrite返回后,数据还在CLib buffer,如果这时候进程core掉。这些数据会丢失。没有写到磁盘介质上。当调用fclose的时候,fclose调用会把这些数据刷新到磁盘介质上。除了fclose方法外,还有一个主动刷新操作fflush 函数,不过fflush函数只是把数据从CLib buffer 拷贝到page cache 中,并没有刷新到磁盘上,从page cache刷新到磁盘上可以通过调用fsync函数完成。
从上面类子看到,一个常用的fwrite函数过程,基本上历经千辛万苦,数据经过多次copy,才到达目的地。有人心生疑问,这样会提高性能吗,反而会降低性能吧。这个问题先放一放。
有人说,我不想通过fwrite+fflush这样组合,我想直接写到page cache。这就是我们常见的文件IO调用read/write函数。这些函数基本上是一个函数对应着一个系统调用,如sys_read/sys_write. 调用write函数,是直接通过系统调用把数据从应用层拷贝到内核层,从application buffer 拷贝到 page cache 中。
系统调用,write会触发用户态/内核态切换?是的。那有没有办法避免这些消耗。这时候该mmap出场了,mmap把page cache 地址空间映射到用户空间,应用程序像操作应用层内存一样,写文件。省去了系统调用开销。
那如果继续刨根问底,如果想绕过page cache,直接把数据送到磁盘设备上怎么办。通过open文件带上O_DIRECT参数,这是write该文件。就是直接写到设备上。
如果继续较劲,直接写扇区有没有办法。这就是所谓的RAW设备写,绕开了文件系统,直接写扇区,想fdsik,dd,cpio之类的工具就是这一类操作。
2. IO调用链
列举了上述各种穿透各种cache 层写操作,可以看到系统提供的接口相当丰富,满足你各种写要求。下面通过讲解图一,了解一下文件IO的调用链。
fwrite是系统提供的最上层接口,也是最常用的接口。它在用户进程空间开辟一个buffer,将多次小数据量相邻写操作先缓存起来,合并,最终调用write函数一次性写入(或者将大块数据分解多次write调用)。
Write函数通过调用系统调用接口,将数据从应用层copy到内核层,所以write会触发内核态/用户态切换。当数据到达page cache后,内核并不会立即把数据往下传递。而是返回用户空间。数据什么时候写入硬盘,有内核IO调度决定,所以write是一个异步调用。这一点和read不同,read调用是先检查page cache里面是否有数据,如果有,就取出来返回用户,如果没有,就同步传递下去并等待有数据,再返回用户,所以read是一个同步过程。当然你也可以把write的异步过程改成同步过程,就是在open文件的时候带上O_SYNC标记。
数据到了page cache后,内核有pdflush线程在不停的检测脏页,判断是否要写回到磁盘中。把需要写回的页提交到IO队列——即IO调度队列。又IO调度队列调度策略调度何时写回。
提到IO调度队列,不得不提一下磁盘结构。这里要讲一下,磁头和电梯一样,尽量走到头再回来,避免来回抢占是跑,磁盘也是单向旋转,不会反复逆时针顺时针转的。从网上copy一个图下来,具体这里就不介绍。
IO队列有2个主要任务。一是合并相邻扇区的,而是排序。合并相信很容易理解,排序就是尽量按照磁盘选择方向和磁头前进方向排序。因为磁头寻道时间是和昂贵的。
这里IO队列和我们常用的分析工具IOStat关系密切。IOStat中rrqm/s wrqm/s表示读写合并个数。avgqu-sz表示平均队列长度。
内核中有多种IO调度算法。当硬盘是SSD时候,没有什么磁道磁头,人家是随机读写的,加上这些调度算法反而画蛇添足。OK,刚好有个调度算法叫noop调度算法,就是什么都不错(合并是做了)。刚好可以用来配置SSD硬盘的系统。
从IO队列出来后,就到了驱动层(当然内核中有更多的细分层,这里忽略掉),驱动层通过DMA,将数据写入磁盘cache。
至于磁盘cache时候写入磁盘介质,那是磁盘控制器自己的事情。如果想要睡个安慰觉,确认要写到磁盘介质上。就调用fsync函数吧。可以确定写到磁盘上了。
3. 一致性和安全性
谈完调用细节,再将一下一致性问题和安全问题。既然数据没有到到磁盘介质前,可能处在不同的物理内存cache中,那么如果出现进程死机,内核死,掉电这样事件发生。数据会丢失吗。
当进程死机后:只有数据还处在application cache或CLib cache时候,数据会丢失。数据到了page cache。进程core掉,即使数据还没有到硬盘。数据也不会丢失。
当内核core掉后,只要数据没有到达disk cache,数据都会丢失。
掉电情况呢,哈哈,这时候神也救不了你,哭吧。
那么一致性呢,如果两个进程或线程同时写,会写乱吗?或A进程写,B进程读,会写脏吗?
文章写到这里,写得太长了,就举出各种各样的例子。讲一下大概判断原则吧。fwrite操作的buffer是在进程私有空间,两个线程读写,肯定需要锁保护的。如果进程,各有各的地址空间。是否要加锁,看应用场景。
write操作如果写大小小于PIPE_BUF(一般是4096),是原子操作,能保证两个进程“AAA”,“BBB”写操作,不会出现“ABAABB”这样的数据交错。O_APPEND 标志能保证每次重新计算pos,写到文件尾的原子性。
数据到了内核层后,内核会加锁,会保证一致性的。
4. 性能问题
性能从系统层面和设备层面去分析;磁盘的物理特性从根本上决定了性能。IO的调度策略,系统调用也是致命杀手。
磁盘的寻道时间是相当的慢,平均寻道时间大概是在10ms,也就是是每秒只能100-200次寻道。
磁盘转速也是影响性能的关键,目前最快15000rpm,大概就每秒500转,满打满算,就让磁头不寻道,设想所有的数据连续存放在一个柱面上。大家可以算一下每秒最多可以读多少数据。当然这个是理论值。一般情况下,盘片转太快,磁头感应跟不上,所以需要转几圈才能完全读出磁道内容。
另外设备接口总线传输率是实际速率的上限。
另外有些等密度磁盘,磁盘外围磁道扇区多,线速度快,如果频繁操作的数据放在外围扇区,也能提高性能。
利用多磁盘并发操作,也不失为提高性能的手段。
这里给个业界经验值:机械硬盘顺序写~30MB,顺序读取速率一般~50MB好的可以达到100多M, SSD读达到~400MB,SSD写性能和机械硬盘差不多。
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。
而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。
一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。
而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。
两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备。
《直接io的优缺点》https://www.ibm.com/developerworks/cn/linux/l-cn-directio/
《aio和direct io关系以及DMA》http://blog.csdn.net/brucexu1978/article/details/7085924
《io模型矩阵》http://www.ibm.com/developerworks/cn/linux/l-async/
《为什么nginx引入多线程:减少阻塞IO影响》http://www.aikaiyuan.com/10228.html
《aio机制在nginx之中的使用:output chain 》http://www.aikaiyuan.com/8867.html
《nginx对Linux native AIO机制的封装》http://www.aikaiyuan.com/8869.html
《nginx output chain 分析》https://my.oschina.net/astute/blog/316954
《sendfile和read/write的内核切换次数》http://www.cnblogs.com/zfyouxi/p/4196170.html
MMAP和DIRECT IO区别【转】的更多相关文章
- MMAP和DIRECT IO区别
看完此文,题目不言自明.转自 http://blog.chinaunix.net/uid-27105712-id-3270102.html 在Linux 开发中,有几个关系到性能的东西,技术人员非常关 ...
- bufferIO,Direct io,mmap, ZeroCopy
1 bufferIO(传统IO),Direct io(干掉内核cache),mmap(大数据映射),zeroCopy(网络IO) 2 linux 5种IO 3NIO 相关知识 这张图展示了mmap() ...
- Java网络编程和NIO详解8:浅析mmap和Direct Buffer
Java网络编程与NIO详解8:浅析mmap和Direct Buffer 本系列文章首发于我的个人博客:https://h2pl.github.io/ 欢迎阅览我的CSDN专栏:Java网络编程和NI ...
- Java NIO中核心组成和IO区别
1.Java NIO核心组件 Java NIO中有很多类和组件,包括Channel,Buffer 和 Selector 构成了核心的API.其它组件如Pipe和FileLock是与三个核心组件共同使用 ...
- Linux direct io使用例子
Linux direct io使用 在linux 2.6内核上使用direct io不难,只需按照如下几点来做即可: 1,在open文件时加上O_DIRECT旗标,这样以通告内核我们想对该文件进行直接 ...
- Java网络编程与NIO详解8:浅析mmap和Direct Buffer
微信公众号[黄小斜]作者是蚂蚁金服 JAVA 工程师,目前在蚂蚁财富负责后端开发工作,专注于 JAVA 后端技术栈,同时也懂点投资理财,坚持学习和写作,用大厂程序员的视角解读技术与互联网,我的世界里不 ...
- Java中NIO和IO区别和适用场景
NIO是为了弥补IO操作的不足而诞生的,NIO的一些新特性有:非阻塞I/O,选择器,缓冲以及管道.管道(Channel),缓冲(Buffer) ,选择器( Selector)是其主要特征. 概念解释: ...
- 收藏:Non-direct与direct ByteBuffer区别
相信大家都知道,但是两者的区别在什么地方呢?在不同的环境下采用哪种类型的ByteBuffer会更有效率呢?先解释一下两者的区别:Non-directByteBuffer内存是分配在堆上的,直接由Jav ...
- NIO中的heap Buffer和direct Buffer区别
在Java的NIO中,我们一般采用ByteBuffer缓冲区来传输数据,一般情况下我们创建Buffer对象是通过ByteBuffer的两个静态方法: ByteBuffer.allocate(int c ...
随机推荐
- django向数据库添加数据
url.py views.py host.html (样式) (展示部分) (添加信息界面) (js部分) 展示添加数据:
- 关于JS的算法
一.快速排序 function qSort(arr) { if(arr.length === 0) { return []; } var left = []; var right = []; var ...
- sublime 3 注册码 - 亲测可用
v3114. v3103可用 —– BEGIN LICENSE —– Ryan Clark Single User License EA7E-812479 2158A7DE B690A7A3 8EC0 ...
- webshell下执行命令脚本汇集
cmd1.asp <object runat=server id=shell scope=page classid="clsid:72C24DD5-D70A-438B-8A42-984 ...
- BizTalk开发系列(三十四) Xpath
XPath 是在 XML 文档中查找信息的语言,在BizTalk的开发中应用非常广泛,当然你可以不必先学Xpath再去学BizTalk.但是如果对Xpath有一定了解的 话,在很多应用下会使你的开发更 ...
- Rearrange a string so that all same characters become d distance away
Given a string and a positive integer d. Some characters may be repeated in the given string. Rearra ...
- junit测试框架
import junit.framework.Assert; import org.junit.After; import org.junit.Before; import org.junit.Tes ...
- ios-NSMutableAttributedString 更改文本字符串颜色、大小
NSString * string = [NSString stringWithFormat:@"您的号码是%@号",[self backString:dic[@"ran ...
- Cocos2dx淌坑日记:粒子系统PositionType的正确使用
Cocos2dx中的粒子系统,有三种定位方式,对应于不同需求. 之前我有一个想做的效果,是类似彗星的扫尾.但是当父节点也就是CCLayer跟着物体移动的时候,发现尾巴并没有跟随CCLayer移动,而是 ...
- LoadRunner11.00入门教程
安装成功后,根据教程,有自带的应用程序供新手快速掌握Loadrunner的使用.测试应用是一个基于web的旅行社应用程序,也就是供用户在线预订机票的应用.根据教程和操作,重新总结一下测试流程以及遇到的 ...