hadoop 2.6伪分布安装
hadoop 2.6的“伪”分式安装与“全”分式安装相比,大部分操作是相同的,主要区别在于不用配置slaves文件,而且其它xxx-core.xml里的参数很多也可以省略,下面是几个关键的配置:
(安装JDK、创建用户、设置SSH免密码 这些准备工作,大家可参考hadoop 2.6全分布安装 一文,以下所有配置文件,均在$HADOOP_HOME/etc/hadoop目录下)
另外,如果之前用 yum install hadoop安装过低版本的hadoop,请先卸载干净(即:yum remove hadoop)
一、修改hadoop-env.sh
主要是设置JAVA_HOME的路径,另外按官网说法还要添加一个HADOOP_PREFIX的导出变量,参考下面的内容:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.65.x86_64
export HADOOP_PREFIX=/home/hadoop/hadoop-2.6.0
二、修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.xx.xx.xxx:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.6.0/tmp</value>
</property>
</configuration>
上面的IP,大家换成自己的IP即可, 另外注意:临时目录如果不存在,请先手动mkdir创建一个
三、修改hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
注:如果只需要跑起来即可,只需要配置dfs.replication即可,另外二个节点,是为了方便eclipse里,hadoop-eclipse-plugin配置时,方便通过ipc.address连接,http.address则是为了方便通过浏览器查看datanode
四、修改mapred-site.xml
伪分布模式下,这个可以不用配置
五、修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
可以开始测试了:
1.先格式化
bin/hdfs namenode –format
2、启动dfs、yarn
sbin/start-dfs.sh
sbin/start-yarn.sh
然后用jps查看java进程,应该能看到以下几个进程:
25361 NodeManager
24931 DataNode
25258 ResourceManager
24797 NameNode
25098 SecondaryNameNode
还可以用以下命令查看hdfs的报告:
bin/hdfs dfsadmin -report 正常情况下可以看到以下内容
Configured Capacity: 48228589568 (44.92 GB)
Present Capacity: 36589916160 (34.08 GB)
DFS Remaining: 36589867008 (34.08 GB)
DFS Used: 49152 (48 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 127.0.0.1:50010 (localhost)
Hostname: dc191
Decommission Status : Normal
Configured Capacity: 48228589568 (44.92 GB)
DFS Used: 49152 (48 KB)
Non DFS Used: 11638673408 (10.84 GB)
DFS Remaining: 36589867008 (34.08 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.87%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue May 05 17:42:54 CST 2015
3、web管理界面查看
http://localhost:50070/
http://localhost:8088/
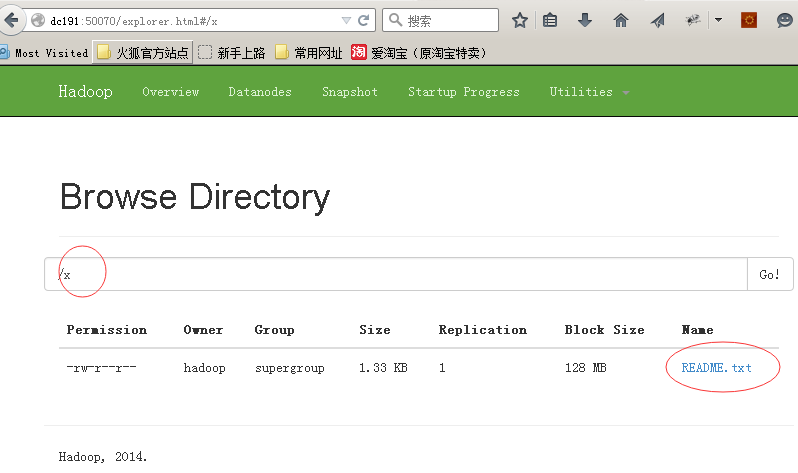
4、在hdfs中创建目录
bin/hdfs dfs -mkdir /x
这样就在hdfs中创建了一个目录x
5、向hdfs中放入文件
bin/hdfs dfs -put README.txt /x
上面的命令会把当前目录下的README.TXT放入hdfs的/x目录中,在web管理界面里也可以看到该文件
参考文档:Hadoop MapReduce Next Generation - Setting up a Single Node Cluster.
hadoop 2.6伪分布安装的更多相关文章
- Hadoop学习记录(1)|伪分布安装
本文转载自向着梦想奋斗博客 Hadoop是什么? 适合大数据的分布式存储于计算平台 不适用小规模数据 作者:Doug Cutting 受Google三篇论文的启发 Hadoop核心项目 HDFS(Ha ...
- 2015.07.12hadoop伪分布安装
hadoop伪分布安装 Hadoop2的伪分布安装步骤[使用root用户用户登陆]other进去超级用户拥有最高的权限 1.1(桥接模式)设置静态IP ,,修改配置文件,虚拟机IP192.168. ...
- CentOS 6.5 伪分布安装
CentOS 6.5 伪分布安装 软件准备 jdk-6u24-linux-i586.bin .hadoop-1.2.1.tar.gz.hadoop-eclipse-plugin-1.2.1.jar ...
- Spark新手入门——2.Hadoop集群(伪分布模式)安装
主要包括以下三部分,本文为第二部分: 一. Scala环境准备 查看 二. Hadoop集群(伪分布模式)安装 三. Spark集群(standalone模式)安装 查看 Hadoop集群(伪分布模式 ...
- 菩提树下的杨过.Net 的《hadoop 2.6全分布安装》补充版
对菩提树下的杨过.Net的这篇博客<hadoop 2.6全分布安装>,我真是佩服的五体投地,我第一次见过教程能写的这么言简意赅,但是又能比较准确表述每一步做法的,这篇博客主要就是在他的基础 ...
- hadoop伪分布安装
解压 将安装包hadoop-2.2.0.tar.gz存放到/home/haozhulin/install/目录下,并解压 #将hadoop解压到/home/haozhulin/install路径下,定 ...
- Hadoop伪分布安装详解(五)
目录: 1.修改主机名和用户名 2.配置静态IP地址 3.配置SSH无密码连接 4.安装JDK1.7 5.配置Hadoop 6.安装Mysql 7.安装Hive 8.安装Hbase 9.安装Sqoop ...
- hadoop: hbase1.0.1.1 伪分布安装
环境:hadoop 2.6.0 + hbase 1.0.1.1 + mac OS X yosemite 10.10.3 安装步骤: 一.下载解压 到官网 http://hbase.apache.org ...
- 【hadoop之翊】——基于CentOS的hadoop2.4.0伪分布安装配置
今天总算是把hadoop2.4的整个开发环境弄好了,包括 windows7上eclipse连接hadoop,eclipse的配置和測试弄得烦躁的一逗比了~ 先上一张成功的图片,hadoop的伪分布式安 ...
随机推荐
- DbUtils是Apache出品一款简化JDBC开发的工具类
DbUtils - DbUtils是Apache出品一款简化JDBC开发的工具类 - 使用DbUtils可以让我们JDBC的开发更加简单 - DbUtils的使用: ...
- git diff的用法
在git提交环节,存在三大部分:working tree(工作区), index file(暂存区:stage), commit(分支:master) working tree:就是你所工作在的目录, ...
- yii2 GridView 日期格式化并实现日期可搜索 案例
作者:白狼 出处:http://www.manks.top/article/yii2_gridview_dateformat_search 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且 ...
- 在ROS中使用Python3
Use Python3 in ROS. 以下内容在Ubuntu 16.04 x64和ROS kinetic中测试通过 事实上,只要在.py文件加上python3的shebang,rosrun的时候就会 ...
- ReactNative之坑爹的在线安装
编译一个github上ReactNative应用,根据说明只有3步: npm installreact-native run-androidenjoy 但几个步骤实在是一波三折充满着坎坷,一点都不en ...
- C++之STL一般总结
重新复习一下STL 什么是STL? STL(模板和标准模板库),实现与类型无关的算法和数据类型,需要将实现中的类型参数化,允许用户根据它的需要制定不同的类型. 一.一般介绍 STL(Standard ...
- Kali Linux 秘籍/Web渗透秘籍/无线渗透入门
Kali Linux 秘籍 原书:Kali Linux Cookbook 译者:飞龙 在线阅读 PDF格式 EPUB格式 MOBI格式 Github Git@OSC 目录: 第一章 安装和启动Kali ...
- Python字符串的编码与解码(encode与decode)
首先要搞清楚,字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unico ...
- 单片机实现60s定时器
单片机573+数码管+按钮 实现60秒的定时器 知识: IE寄存器 TCON寄存器 TMOD 寄存器 /***************** 2个定时中断,2个按钮中断 **************** ...
- 虚拟机centos6.5 --安装jdk
1.首先卸载默认安装的openjdk,如下 rpm -qa | grep java #查看当前是否已经安装了跟java有关的包 yum -y remove java #卸载 rpm -qa |grep ...