算法与设计模式系列1之Python实现常见算法
preface
常见的算法包括:
- 递归算法
- 二分法查找算法
- 冒泡算法
- 插入排序
- 快速排序
- 二叉树排序
下面就开始挨个挨个的说说原理,然后用Python去实现:
递归算法
一个函数(或者程序)直接或者间接调用自己,每调用一次后返回的值当作下一次执行的输入值,调用要有停止条件的(称为递归出口),不然不停的调用会造成栈溢出的。 递归算法运行效率,我们一般写程序的时候很少使用这样的算法。
算法的详解请看这里百度百科。
算法代码如下:
def test(a):
while a > 10: #递归终止条件(递归出口)
a-=6
print(a)
return test(a) #调用自己本身来递归
test(26)
# 运行结果-------------------------------
20
14
8
二分法查找算法
什么是二分法查找算法:二分法查找算法请看这里
好了,等你看完百度百科里面介绍二分法算法后,现在知道什么是二分法查找算法了吧!
话不多说,直接上代码(python结合递归算法实现二分法查找数据)。
代码如下:
data=list(a for a in range(10000)) #定义一个列表,一个从小到大或从大到小的有序数列
def find_num(num,data):
'''
利用二分法来查找某个数
:param num: 需要查找的数
:param data: 从哪里查找
:return:
'''
print(data)
if len(data)>=2: #判断列表长度是否大于等于2,因为如果此时的数据只有1个,那么就找不到这个数
mid=int(len(data)/2) #定义中间数,这步开始采用二分法,py3下需要int来转成整形。
if num > data[mid]: # 如果要找的数大于中间数,那么就继续在该数组右边区域查找
print("the %s is in right"%num)
find_num(num,data[mid:])
elif num < data[mid]: # 如果要找的数小于中间数,那么就继续在该数组右边区域查找
print("the %s is in left"%num)
find_num(num,data[:mid])
else:
print(" find it")
print(data[mid])
else:
print(data)
print("your find number is not exist!!")
find_num(5125,data)
运行结果-----------------------
the 11 is in left
the 11 is in left
the 11 is in left
the 11 is in right
the 11 is in right
the 11 is in right
find it
11
冒泡算法
什么是冒泡算法??
冒泡排序(Bubble Sort),是一种简单的排序算法。
原理:
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
说白了,冒泡算法其实就像在水里面的气泡一样,越轻的东西越是浮在水面。在数字的世界里面也一样,数字越大的数,那么就排在数组里面最下面,数字越小的数字,就排在数组的最前面。
代码例子如下:
#下面几步是通过random模块来产生随即数组。
import random
tmp=[]
for i in range(10):
tmp.append(random.randint(1,1000))
#tmp=[686,334,248,405,676,51,76,110,634,292]
print(tmp)
#算法开始
for a in range(len(tmp)): #遍历整个数组
for i in range(len(tmp[:-1])): #遍历数组的前N个数,N等于数组的长度减去1,也就是说数组最后一个数是不要遍历出来,为啥,因为他是最后一个数。
if tmp[i] > tmp[i+1]: #以下三步开始交换数字的顺序,比较相邻的两个数,如果第一个数大于第二个数
x=tmp[i+1] # 那么把第较小的数赋值个x变量
tmp[i+1]=tmp[i] #把较大的数 赋值给 较小的数,这样数值大的数就往前挪了一位
tmp[i]=x #把 x的值 赋值给 较大的数,这样数值较小的数就往后挪了一位,导致相邻的两个数互相调换了顺序。
print(tmp)
插入排序:
将列表分为2部分,左边为排序好的部分,右边为未排序的部分,循环整个列表,每次将一个待排序的记录,按其关键字大小插入到前 面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。
思想基本是这样的:
我们选取列表第2个数开始,把第一个数和第二个数对比,
1 如果第一个数比第二个数大,那么调换下。
2 如果第二个数比第一个数小,那么就不需要调换。
3 依次类推,同理可得。。。
代码如下:
生成随机数列表
import random
a=[]
for i in range(10):
a.append(random.randint(1,100))
print(a)
# 开始进入排序状态
#source = [95, 26, 36, 38, 15, 81, 28, 100, 31, 76]
source = a
for index in range(1,len(source)):
print('index -->',index)
current_val = source[index] # 记录下每次大循环走到列表的第几个值
position = index
#当前位置大于0说明开始循环到第二个数了,而且当前列表元素的前一位(该元素左边第一位)大于当前的元素
while position > 0 and source[position-1] > current_val:
# 把左边的值往右边移动一位
source[position] = source[position-1]
# 继续减小posttion的值从而让当前列表元素左移动到合适位置
position -=1
# 已经找到了左边排序好的列表里不小于current_val的元素
source[position] = current_val
print(source)
输出结果如下:
[15, 26, 28, 31, 36, 38, 76, 81, 95, 100]
快速排序
它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
我们这样一个列表说明:
数 54 32 12 23 109 88
下标 0 1 2 3 4 5
++交换原理++
在我们开始循环的时候,我们先定义k(作为参考数),一般情况下取第一个,这里就相当于取54了,54的下标为0,作为left_flag,还需要取本列表最后一个数的下标,即88的下标5,记为right_flag,拿到这三个数后,首先要明白,一般情况下,所有小于k的数都要在k的左边,大于k的数要在k的右边,在比较2个数的时候,只有右侧发现有数需要交换的时候,即k在左边,但是发现有个数比k小,在k的右边,那么需要交换,把k和这个数交换下,left_flag就需要开始加一了;如果是左侧发现有数需要交换的时候,即k在右边,但是发现有个数比k大,在k的左边,那么需要交换,把k和这个数交换下,right_flag就需要开始减一了。
first loop
数 12 23 32 54 109 88
下标 0 1 2 3 4 5
解释
此时在经过第一次循环排序后,我们发现54左侧没有比54的数大 了,那么就需要把54左侧的所有数,以递归的方式,再进行一次排序,这次排序涉及到的数就是 [23 32 12]
1 我们拿到以k为中间数,把k左侧的所有数拿过来,这里的就只有三个数[ 23 32 12],老规矩,我们以23为k,23的下标为left_flag,12的下标为right_flag,开始进入排序状态。
2 开始比较,我们发现23>12,所以,需要调换,此时列表成了[ 12 32 23 ],left_flag 加一,加一后下标就到了32这个数,32 >23 ,且32在23的左边,需要调换,一调换,发现right_flag减一后等于left_flag,且列表为有序列表了[12 23 32],完成了此次调换。
and so on ......同理可得,完成了排序。。。。。。。
好了,废话说了一堆,原理明白,直接上代码。
def quick_sort(array,start,end):
'''
使用快速排序方法去排序数组
:param array: 数据列表
:param start: 指明这个列表开始排序的起始位置
:param end: 指明这个列表开始排序的结束位置
:return:
'''
#print('befor',array)
# 首先判断要排序的列表左边的值是否大于右边的值
if start >= end:
#print('start - end',start,end)
return
k = array[start] # 取k作为关键数,当作用来平分2组数据中间值
left_flag = start
right_flag = end
# 判断左边的下标是否和右边下标有没有碰头
while left_flag < right_flag:
print(array)
# 当右边下标指定的数大于 关键数k的时候,right_flag 就持续减1
while left_flag < right_flag and array[right_flag] > k:
'''
这个循环的目的就在于判断k右边的数有没有比k大,找到比k的话,就开始交换,
交换的东仔在下面几行代码, right_flag -=1只是不断找比k小的数
'''
right_flag -=1
# 开始交换,把比k小的数(array[right_flag] 放到左边)
array[left_flag] = array[right_flag]
array[right_flag] = k
# 左边的下标开始向由移动
while left_flag < right_flag and array[left_flag] <= k:
# 原理同上,left_flag +=1只是不断找比k大的数
left_flag +=1
# 当上面的while 循环跳出后,代表左边的下标移动到的数比k大
# 开始交换,把比k大的数(array[right_flag] 放到右边)
array[right_flag] = array[left_flag]
array[left_flag] = k
quick_sort(array,start,left_flag-1) # 对左边的数据排序,递归算法
quick_sort(array,left_flag+1,end) # 对右边的数据排序,递归算法
return array
array = [55, 26, 36, 38, 15, 81, 28, 100, 31, 76]
print(array)
array=quick_sort(array,0,len(array)-1)
print(array)
二叉树排序
原理:
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)
二叉树是由n(n≥0)个结点组成的有限集合、每个结点最多有两个子树的有序树。它或者是空集,或者是由一个根和称为左、右子树的两个不相交的二叉树组成。
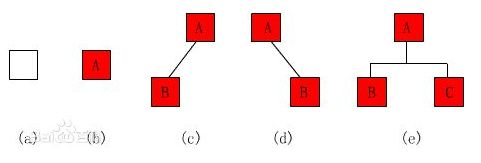
特殊二叉树:
每个节点都不比它左子树的任意元素小,而且不比它的右子树的任意元素大。换句话说:假设树中没有重复的元素,那么上述要求可以写成:每个节点比它左子树的任意节点大,而且比它右子树的任意节点小。(图片摘自互联网上的,省的自己画图了,偷下懒)
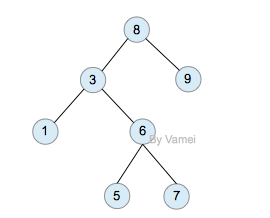
二叉搜索树,注意树中元素的大小
二叉搜索树可以方便的实现搜索算法。在搜索元素x的时候,我们可以将x和根节点比较:
- 如果x等于根节点,那么找到x,停止搜索 (终止条件)
- 如果x小于根节点,那么搜索左子树
- 如果x大于根节点,那么搜索右子树
二叉搜索树所需要进行的操作次数最多与树的深度相等。n个节点的二叉搜索树的深度最多为n,最少为log(n)。
特点:
- 二叉树是有序树,即使只有一个子树,也必须区分左、右子树;
- 二叉树的每个结点的度不能大于2,只能取0、1、2三者之一;
- 二叉树中所有结点的形态有5种:空结点、无左右子树的结点、只有左子树的结点、只有右子树的结点和具有左右子树的结点。
遍历二叉树:
遍历即将树的所有结点访问且仅访问一次。按照根节点位置的不同分为前序遍历,中序遍历,后序遍历。
- 前序遍历:根节点->左子树->右子树
- 中序遍历:左子树->根节点->右子树
- 后序遍历:左子树->右子树->根节点
例如:求下面树的三种遍历
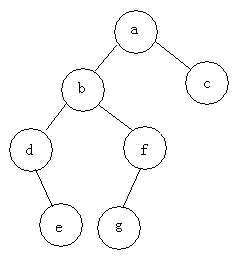
- 前序遍历:abdefgc
- 中序遍历:debgfac
- 后序遍历:edgfbca
类型:
- 完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
- 满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
- 平衡二叉树——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
算法与设计模式系列1之Python实现常见算法的更多相关文章
- Python之常见算法介绍
一.算法介绍 1. 算法是什么 算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求的输 ...
- Python实现常见算法[2]——快速排序
#!/usr/bin/python # module: quik_sort.py def PARTION(L,m,n): base = L[n] i = m-1 j = m while j<n: ...
- Python实现常见算法[1]——冒泡排序
#!/usr/bin/python def BUBBLE_SORT(L, x, y): j = y while j>x: i = x while i<j: if L[i] > L[i ...
- 手指静脉细化算法过程原理解析 以及python实现细化算法
原文作者:aircraft 原文地址:https://www.cnblogs.com/DOMLX/p/8672489.html 文中的一些图片以及思想很多都是参考https://www.cnblogs ...
- Python实现常见算法[3]——汉罗塔递归
#!/usr/bin/python # define three list var. z1 = [1,2,3,4,5,6,7,"1st zhu"] z2 = ["2st ...
- python数据结构与算法
最近忙着准备各种笔试的东西,主要看什么数据结构啊,算法啦,balahbalah啊,以前一直就没看过这些,就挑了本简单的<啊哈算法>入门,不过里面的数据结构和算法都是用C语言写的,而自己对p ...
- Python之路:常用算法与设计模式
选择排序 时间复杂度 二.计算方法 1.一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道.但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花 ...
- python实现常见的设计模式
Pyhton实现常用的23种设计模式[详解] 关注公众号[轻松学编程],回复[设计模式],获取本文源代码. 在文章末尾可以扫码关注公众号. 一.概念 软件工程中,设计模式是指软件设计问题的推荐方案. ...
- Python数据结构与算法设计总结篇
1.Python数据结构篇 数据结构篇主要是阅读[Problem Solving with Python]( http://interactivepython.org/courselib/static ...
随机推荐
- JavaScript中call,apply,bind方法的总结。
why?call,apply,bind干什么的?为什么要学这个? 一般用来指定this的环境,在没有学之前,通常会有这些问题. var a = { user:"追梦子", fn:f ...
- Javascript将构造函数扩展为简单工厂
一般而言,在Javascript中创建对象时需要使用关键字new(按构造函数去调用),但是某些时候,开发者希望无论new关键字有没有被显式使用,构造函数都可以被正常调用,即构造函数同时还具备简单工厂的 ...
- Common Issues Which Cause Roles to Recycle
This section lists some of the common causes of deployment problems, and offers troubleshooting tips ...
- navigationView 的使用和布局文件的绑定
今天项目进行到了细化内容的部分啦- 需要美化侧滑菜单,并且填充数据.在博客上看了好久发现大家的都大同小异 而且很少有提到如何绑定内容各处求助终于在一片博客上发现了蛛丝马迹!!上大神的帖子:blog.c ...
- Ceph浅析”系列之四——Ceph的结构
本文将从逻辑结构的角度对Ceph进行分析. Ceph系统的层次结构 Ceph存储系统的逻辑层次结构如下图所示[1]. Ceph系统逻辑层次结构 自下向上,可以将Ceph系统分为四个层次: (1)基础存 ...
- 如何设置让iis服务器支持.apk文件的下载
随着智能手机的普及,越来越多的人使用手机上网,很多网站也应手机上网的需要推出了网站客户端,.apk文件就是安卓(Android)的应用程序后缀名,默认情况下,使用IIS作为Web服务器的无法下载此文件 ...
- 内存溢出OOM与内存泄漏ML
附, 微信团队原创分享:Android内存泄漏监控和优化技巧总结 一.如何避免OOM 异常 想要避免OOM 异常首先我们要知道什么情况下会导致OOM 异常. 1.图片过大导致OOM Android 中 ...
- java中会存在内存泄漏吗,请简单描述。
内存泄露就是指一个不再被程序使用的对象或变量一直被占据在内存中.Java 使用有向图的方式进行垃圾回收管理,可以消除引用循环的问题,例如有两个对象,相互引用,只要它们和根进程不可达的,那么GC也是可以 ...
- Java套接字
前言: 本文补充一下Java关于套接字方面的内容,因为其应用相对比较简单,所以下面介绍两个程序实例. ------------------------------------------------- ...
- C++编译期多态与运行期多态
前言 今日的C++不再是个单纯的"带类的C"语言,它已经发展成为一个多种次语言所组成的语言集合,其中泛型编程与基于它的STL是C++发展中最为出彩的那部分.在面向对象C++编程中, ...