关于urllib、urllib2爬虫伪装的总结
站在网站管理的角度,如果在同一时间段,大家全部利用爬虫程序对自己的网站进行爬取操作,那么这网站服务器能不能承受这种负荷?肯定不能啊,如果严重超负荷则会时服务器宕机(死机)的,对于一些商业型的网站,宕机一秒钟的损失都是不得了的,这不是一个管理员能承担的,对吧?那管理员会网站服务器做什么来优化呢?我想到的是,写一个脚本,当检测到一个IP访问的速度过快,报文头部并不是浏览器的话,那么就拒绝服务,或者屏蔽IP等,这样就可以减少服务器的负担并让服务器正常进行。
那么既然服务器做好了优化,但你知道这是对爬虫程序的优化,如果你是用浏览器来作为一个用户访问的话,服务器是不会拦截或者屏蔽你的,它也不敢拦你,为什么,你现在是客户,它敢拦客户,不想继续经营了是吧?所以对于如果是一个浏览器用户的话,是可以正常访问的。
所以想到方法了吗?是的,把程序伪造成一个浏览器啊,前面说过服务器会检测报文头部信息,如果是浏览器就不正常通行,如果是程序就拒绝服务。
那么报文是什么?头部信息又是什么?详细的就不解释了,这涉及到http协议和tcp/ip三次握手等等的网络基础知识,感兴趣的自己百度或者谷歌吧。
本篇博文不扯远了,只说相关的重点——怎么查看头部信息。
User-Agent
其实我想有些朋友可能有疑惑,服务器是怎么知道我们使用的是程序或者浏览器呢?它用什么来判断的?
我使用的是火狐浏览器,鼠标右键-查看元素(有的浏览器是审查元素或者检查)
网络(有的是network):
出现报文:

双击它, 右边则会出现详细的信息,选择消息头(有的是headers)

找到请求头(request headers),其中的User-Agent就是我们头部信息:
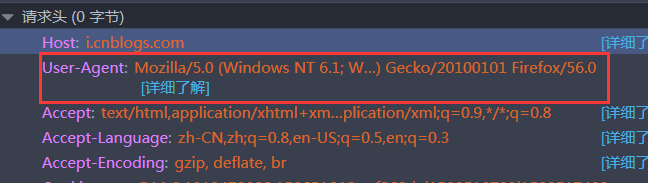
看到是显示的

# -*- coding:utf-8 -*-
import urllib url='http://www.baidu.com' #百度网址
html=urllib.urlopen(url)#利用模块urllib里的urlopen方法打开网页
print(dir(html)) #查看对象html的方法
print(urllib.urlopen) #查看对象urllib.urlopen的方法
print(urllib.urlopen()) #查看对象urllib.urlopen实例化后的方法
Traceback (most recent call last):
File "D:\programme\PyCharm 5.0.3\helpers\pycharm\utrunner.py", line 121, in <module>
modules = [loadSource(a[0])]
File "D:\programme\PyCharm 5.0.3\helpers\pycharm\utrunner.py", line 41, in loadSource
module = imp.load_source(moduleName, fileName)
File "G:\programme\Python\python project\test.py", line 8, in <module>
print(urllib.urlopen())
TypeError: urlopen() takes at least 1 argument (0 given) ['__doc__', '__init__', '__iter__', '__module__', '__repr__', 'close', 'code',
'fileno', 'fp', 'getcode', 'geturl', 'headers', 'info', 'next', 'read', 'readline', 'readlines', 'url'] <function urlopen at 0x0297FD30>
由此,这里就必须注意,只有当urllib.urlopen()实例化后才有其后面的方法,urlopen会返回一个类文件对象,urllib.urlopen只是一个对象,而urllib.urlopen()必须传入一个参数,不然则报错。
urlopen提供了如下方法:
- read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样
- info():返回一个httplib.HTTPMessage 对象,表示远程服务器返回的头信息
- getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到
- geturl():返回请求的url
- headers:返回请求头部信息
- code:返回状态码
- url:返回请求的url
好的,详细的自己去研究了,本篇博文的重点终于来了,伪装一个头部信息
伪造头部信息
由于urllib没有伪造头部信息的方法,所以这里得使用一个新的模块,urllib2
# -*- coding:utf-8 -*-
import urllib2 url='http://www.baidu.com' head={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
} #头部信息,必须是一个字典
html=urllib2.Request(url,headers=head)
result=urllib2.urlopen(html)
print result.read()
或者你也可以这样:
# -*- coding:utf-8 -*-
import urllib2 url='http://www.baidu.com' html=urllib2.Request(url)
html.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0') #此时注意区别格式
result=urllib2.urlopen(html)
print result.read()
结果都一样的,我也就不展示了。
按照上面的方法就可以伪造请求头部信息。
那么你说,我怎么知道伪造成功了?还有不伪造头部信息时,显示的到底是什么呢?介绍一个抓包工具——fidder,用这个工具就可以查看到底报文头部是什么了。这里就不展示了,自己下去常识了。并且我可以确切的保证,确实伪造成功了。
这样,我们就把爬虫代码升级了一下,可以搞定普通的反爬虫限制
关于urllib、urllib2爬虫伪装的总结的更多相关文章
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 人生苦短之Python的urllib urllib2 requests
在Python中涉及到URL请求相关的操作涉及到模块有urllib,urllib2,requests,其中urllib和urllib2是Python自带的HTTP访问标准库,requsets是第三方库 ...
- python urllib urllib2
区别 1) urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL.这意味着,用urllib时不可以伪装User Agent字符串等. 2) u ...
- httplib urllib urllib2 pycurl 比较
最近网上面试看到了有关这方面的问题,由于近两个月这些库或多或少都用过,现在根据自己的经验和网上介绍来总结一下. httplib 实现了HTTP和HTTPS的客户端协议,一般不直接使用,在python更 ...
- python爬虫伪装技术应用
版权声明:本文为博主原创文章,转载 请注明出处: https://blog.csdn.net/sc2079/article/details/82423865 -写在前面 本篇博客主要是爬虫伪装技术的应 ...
- python中urllib, urllib2,urllib3, httplib,httplib2, request的区别
permike原文python中urllib, urllib2,urllib3, httplib,httplib2, request的区别 若只使用python3.X, 下面可以不看了, 记住有个ur ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
随机推荐
- 桥接模式_NAT模式_仅主机模式_模型图.ziw
2017年1月12日, 星期四 桥接模式_NAT模式_仅主机模式_模型图 null
- 你知道吗?衡量 Web 性能的几个关键指标
自网站诞生以来,响应速度/响应时间一直都是大家关心的话题,而速度慢乃是网站的一个杀手,正当大家以为四核和宽带能力的提升能够解决这些问题时,Wi-Fi和移动设备为热点移动互联网又悄然兴起. 在2006年 ...
- 铺地砖|状压DP练习
有一个N*M(N<=5,M<=1000)的棋盘,现在有1*2及2*1的小木块无数个,要盖满整个棋盘,有多少种方式?答案只需要mod1,000,000,007即可. //我也不知道这道题的来 ...
- 【转】E: Sub-process /usr/bin/dpkg returned an error code (1)
原链接: jaryWang:E: Sub-process /usr/bin/dpkg returned an error code (1)错误解决 1.$ sudo mv /var/lib/dpkg/ ...
- Linux下命令lrzsz
lrzsz是什么 在使用Linux的过程中,难免少不了需要上传下载文件,比如往服务器上传一些war包之类的,之前都是使用winSCP,lrzsz是一个更方便的命令,可以直接在Linux中输入命令,弹出 ...
- koa源码阅读[1]-koa与koa-compose
接上次挖的坑,对koa2.x相关的源码进行分析 第一篇.不得不说,koa是一个很轻量.很优雅的http框架,尤其是在2.x以后移除了co的引入,使其代码变得更为清晰. express和koa同为一批人 ...
- docker 升级后,配置 idea 连接 docker
[root@A01-R02-I188-87 ~]# docker version Client: Version: 18.06.1-ce API version: 1.24 Go version: g ...
- 使用正则表达式匹配IP地址
IP地址分为4段,以点号分隔.要对IP地址进行匹配,首先要对其进行分析,分成如下部分,分别进行匹配: 第一步:地址分析,正则初判 1.0-9 \d 进行匹配 2.10-99 [1-9]\d 进行匹 ...
- springboot + swagger2 生成api文档
直接贴代码: <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-sw ...
- 关于angular导入第三方库的问题
angular-cli使用webpack来将模块打包,在这里配置的scripts和styles会被打包成script.bundle.js和styles.bundle.js文件加载到前台页面. 这样就可 ...