lucene_01_入门程序
索引和搜索流程图:
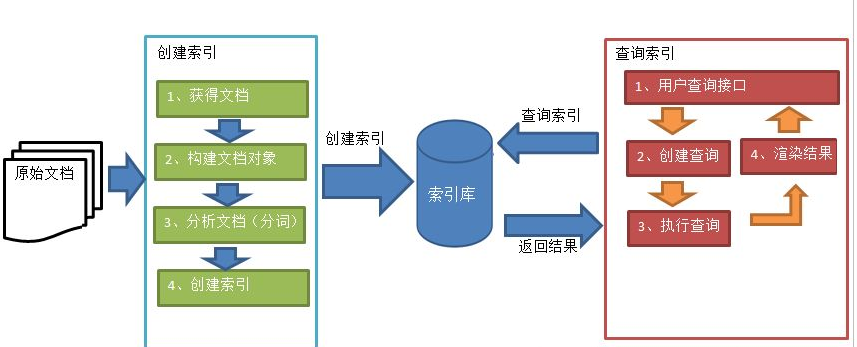
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容->采集文档->创建文档->分析文档->素引文档
2、红色表示搜索过程,从索弓库中搜索内容,
搜索过程包括:
用户通过搜索界面->创建查询子执行搜索,从索引库搜索->渲染搜索结果
索引和搜索操作的对象为:索引库。
索引库中包含的部分:索引、原始文档。
原始文档:要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
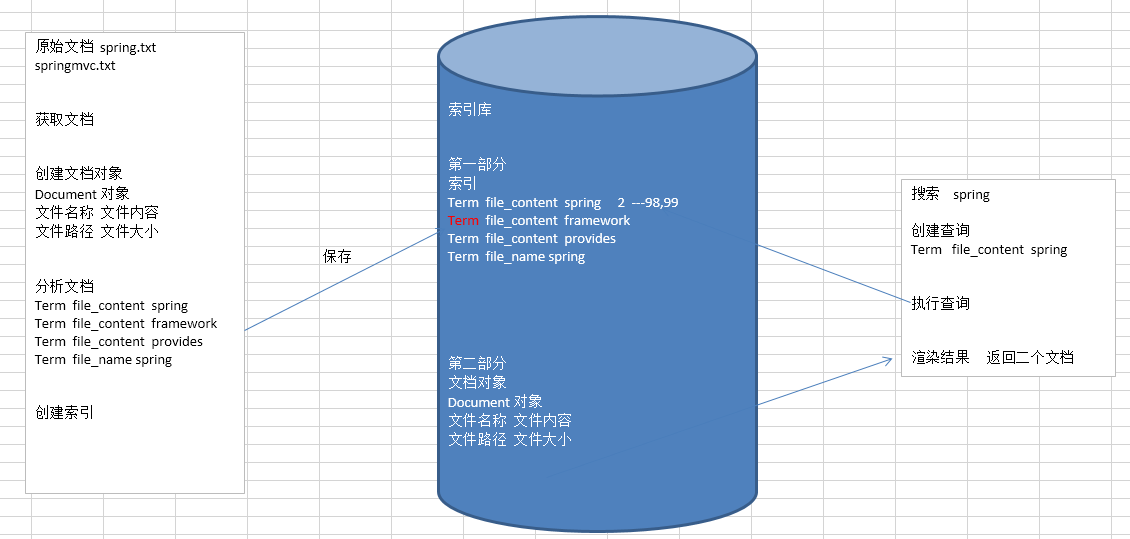
创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始內容创建成文档(Document),
文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的-一个文件当成一个document,Document 中包括-一些Field
(file_mame文件名称、file_path文件路径、file_size 文件大小、file_content文件内容),如下图:

注意:
每个文档可以有多个Field,
不同的文档可以有不同的Field, —— 对于数据库办不到,每一行看作是一个document(文档),每一列看作是一个Filed.数据库的每一行的字段是固定的。
同一个 文档可以有相同的Field (域名和域值都相同)。—— 数据库中也不能有重复的字段
每个文档都有一个唯一的编号,就是文档id。—— 不同数据库的 id,该id不是域(对应于数据库的字段),无法进行操作,由系统维护。
域:是可以被我们操作的。
分析文档
分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过
程生成最终的语汇单元, 可以将语汇单元理解为一个一个的单词。
原文档内容:
Lucene is a Java full-text search engine.Lucene is not a completer
application,but rather a code library and API that can easily be used
to add search capabilities to applications.
分析后得到的语汇单元。
lucene、java、full、search、engine。。。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。
含两部分一部分是文档的域名,另一部分是单词的内容。。
例如: 文件名中包含apache和文件内容中包含的apache是不同的term.
注意: 创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺
序扫描方法,数据量大、搜索慢。
倒排索引结构是通过内容找文档,如下图:
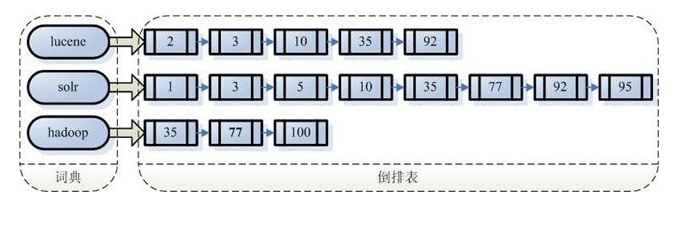
倒排索引结构也叫反向索引结构,包括索引和文档两个部分,索引即词汇表,它的规模较小,而文档集合较大。
入门代码实现
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.chen</groupId>
<artifactId>lucene</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging> <name>lucene</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.2.1</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.2.1</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.2.1</version>
</dependency> <!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency> </dependencies> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
创建索引
Field类
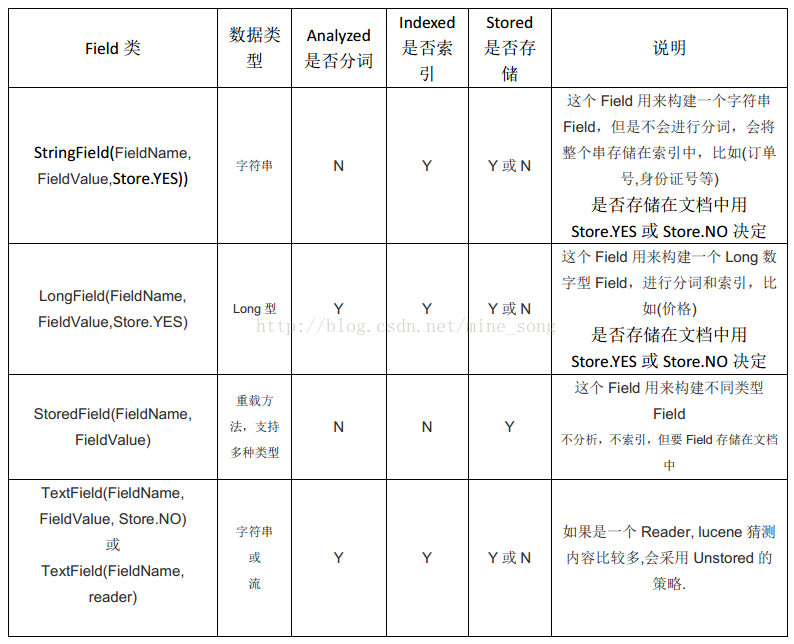
注在该版本中已经抛弃了LongField方法
@Test
public void createIndex() throws Exception{
// 第一步; 创建一个java工程,并导入jar包。
// 第二步: 创建一个indexwriter对象。
// 1) 指定索引库的存放位置Directory对象 Directory directory = FSDirectory.open(Paths.get("F:\\lucene\\indexDatabase")); // 2) 指定一个分听器,对文档内容进行分析。
IndexWriterConfig config = new IndexWriterConfig(new StandardAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory,config);
// 第四步: 创建field对象,将field添加到document对象中。
File filedir = new File("F:\\lucene\\document");
if(filedir.exists() && filedir.isDirectory()){
File[] files = filedir.listFiles();
for (File file:files) {
// 第三步,创|建document对象。
Document document = new Document();
//获取文件的名称
String fileName = file.getName();
//创建textfield,保存文件名(key,value,是否存储)
TextField fileNameField = new TextField("fileName",fileName, Field.Store.YES);
//文件大小
long fileSize = FileUtils.sizeOf(file);
// new NumericDocValuesField("fileSize",fileSize);
SortedNumericDocValuesField fileSizeField = new SortedNumericDocValuesField("fileSize", fileSize);
//文件路径
String filePath = file.getPath();
StoredField filePathField = new StoredField("filePath", filePath);
//文件内容
String fileContent = FileUtils.readFileToString(file,"gbk");
TextField fileContentField = new TextField("fileContent", fileContent, Field.Store.YES);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField); // 第五步: 使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写) 索引库。
indexWriter.addDocument(document);
}
}
// 第六步: 关闭IndexWriter对象。
indexWriter.close(); }
查询索引
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档链表。
比如搜索语法为“fileName:lucee 表示搜索出fileName 域中包含Lucene 的文档。
搜索过程就是在索引上查找域为fileName,并且关键字为Llucene 的term,并根据term 找到文档id 列表。
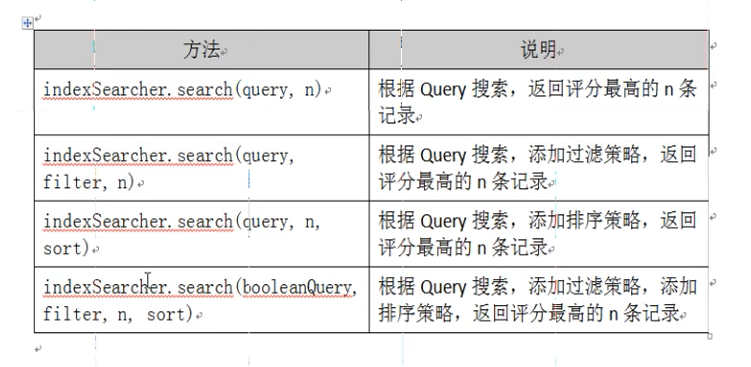
@Test
public void testSearcher() throws IOException {
// 第一步: 创建一个Directory 对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(Paths.get("F:\\lucene\\indexDatabase"));
// 第二步: 创建一个indexReader 对象,需要指定Directory 对象。
IndexReader indexReader = DirectoryReader.open(directory);
// 第三步: 创建一个indexsearcher 对象,需要指定InclexReader 对象。
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步: 创建一个TermQuery对象,指定查询的域和查询的关键词。
// Term term = new Term("fileName", "java");
Term term = new Term("fileContent", "store");
Query query = new TermQuery(term);
// 第五步: 执行查询。
TopDocs topDocs = indexSearcher.search(query, 13);
// 第六步: 返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc doc : scoreDocs) {
int docIndex = doc.doc;
Document document = indexSearcher.doc(docIndex);
String fileName = document.get("fileName");
System.out.println(fileName);
String fileSize = document.get("fileSize");
System.out.println(fileSize);
String filePath = document.get("filePath");
System.out.println(filePath);
String fileContent = document.get("fileContent");
System.out.println(fileContent);
System.out.println("==========================");
}
// 第七步: 关闭IndexReader 对象。
indexReader.close(); }
lucene_01_入门程序的更多相关文章
- mybatis入门_mybatis基本原理以及入门程序
一.传统jdbc存在的问题 1.创建数据库的连接存在大量的硬编码, 2.执行statement时存在硬编码. 3.频繁的开启和关闭数据库连接,会严重影响数据库的性能,浪费数据库的资源. 4.存在大量的 ...
- 1.struts2原理和入门程序
Struts2是一个MVC的Web应用框架,是在Struts1和WebWork发展起来的,以WebWork为核心,采取拦截器机制来处理用户请求. 原理图: 分析步骤: 1.用户发送一个请求 2.请求的 ...
- springMVC2 1入门程序
1入门程序 .1需求 实现商品列表查询 .2需要的jar包 使用spring3.2.0(带springwebmvc模块) .1前端控制器 在web.xml中配置: <?xml version=& ...
- struts2入门程序
struts2入门程序 1.示例 搭建编程环境就先不说了,这里假设已经搭建好了编程环境,并且下好了strut2的jar包,接下来程序. 1.1 新建web项目 点击File->New->D ...
- Spring+SpringMVC+MyBatis深入学习及搭建(十二)——SpringMVC入门程序(一)
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/6999743.html 前面讲到:Spring+SpringMVC+MyBatis深入学习及搭建(十一)——S ...
- springmvc(一) springmvc框架原理分析和简单入门程序
springmvc这个框架真的非常简单,感觉比struts2还更简单,好好沉淀下来学习~ --WH 一.什么是springmvc? 我们知道三层架构的思想,并且如果你知道ssh的话,就会更加透彻的理解 ...
- python web入门程序
python2.x web入门程序 #!/usr/bin/python # -*- coding: UTF-8 -*- # 只在python2.x 有效 import os #Python的标准库中的 ...
- Maven01——简介、安装配置、入门程序、项目构建和依赖管理
1 Maven的简介 1.1 什么是maven 是apache下的一个开源项目,是纯java开发,并且只是用来管理java项目的 Svn eclipse maven量级 1.2 Maven好处 同 ...
- ssm整合快速入门程序(一)
整合基础说明 spring 是一个开放源代码的设计层面框架,他解决的是业务逻辑层和其他各层的松耦合问题,因此它将面向接口的编程思想贯穿整个系统应用.Spring是于2003 年兴起的一个轻量级的Jav ...
随机推荐
- P1043 数字游戏
P1043 数字游戏 题目描述 丁丁最近沉迷于一个数字游戏之中.这个游戏看似简单,但丁丁在研究了许多天之后却发觉原来在简单的规则下想要赢得这个游戏并不那么容易.游戏是这样的,在你面前有一圈整数(一共n ...
- Java之POI读取Excel的Package should contain a content type part [M1.13]] with root cause异常问题解决
Java之POI读取Excel的Package should contain a content type part [M1.13]] with root cause异常问题解决 引言: 在Java中 ...
- C# datagridview 删除行(转 学会、放弃博客)
原文引入:http://zhangyanyansy.blog.163.com/blog/static/13530509720106171252978/ datagridview 删除行 2010-07 ...
- 1tb等于多少g 1TB和500G有什么区别
转自:http://www.a207.com/article/view_39392 移动硬盘.U盘是生活中常见的用品,他们的内存大小是什么标准.很多人对于1tb等于多少g和1tb和500g有什么区别不 ...
- 关于MFC控件删除出现“具有该ID的控件已存在”这样的情况的解决方案,详细,网上都没有这么详细的,我是“深受其害”,所以想将详细的方法分享出去。
网上关于MFC控件删除出现“具有该ID的控件已存在”这样的情况,在网上找了很多关于这方面的东西,但是都不是很全,也不容易弄明白.现在问我直接通过一个项目和图片的形式和大家一块分享一个这个解决方法(如有 ...
- [转]RDLC报表——动态添加列
本文转自:http://www.cnblogs.com/pszw/archive/2012/07/19/2599937.html 前言 最近接到一个需求:在给定的数据源中,某(些)列,可能需要单独统计 ...
- sql学习--update
两种修改形式 第一种:静态插入 ,notes='began career selling ...balabala' where jc='johnny ca' 第二种: --注意别名和on后边的表连接不 ...
- 酷派 5267 刷入第三方 recovery教程 刷机 ROOT
准备工作: 一台电脑: 酷派5267手机: 一张内存卡: 下载好刷机资料: http://pan.baidu.com/s/1i4LoVh7 备用下载: http://pan.baidu.com/s/ ...
- view在使用shape属性加圆角的同时,用代码修改其他background属性(例如颜色)不生效
项目中一个TextView控件设置了shape属性,给其加了圆角,如下: houlder.mtxtGovernmentType.setBackgroundResource(R.drawable.tv_ ...
- MYSQL 45道练习题
学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四个表的结构分别如表1-1的表(一)~表(四)所示,数据如表1-2的表(一)~表(四)所示.用S ...