Image Captioning 经典论文合辑
Image Caption: Automatically describing the content of an image
domain:CV+NLP
Category:(by myself, you can read the survey for detail.)
- CNN+RNN, with attention mechanisms
- Reinforcement Learning
- GAN
- Compositional Architecture: Review Network, Guiding Network, RFNet (fusion)
- Cross-domain: objects not present in training captions (out-of-domain/cross domain captioning) Peter Anderson has some publications about this. (Show, Adapt and Tell, Constrained Beam Search)
- Stylized Caption: Senticap, StyleNet, SemStyle
- Novel Object-based Image Captioning: NOC(Captioning Images wuth Diverse Objects), Neural Baby Talk
- Diversity(句子的多样性问题)
- Dense Caption: DenseCap
- Image Paragraph: (Maybe another research area, but I still place it here. More difficult than image caption)
数据集:Flickr8k,Flickr30k,MSCOCO,Visual Genome,Conceptual Captions(ACL 2018谷歌收集的数据集)
评测指标:BLEU,METEOR,CIDEr,ROUGE,SPICE
A Comprehensive Survey of Deep Learning for Image Captioning (ACM Computing Surveys, October 2018.)
这是一篇比较新的关于Image Caption的综述文章(Survey).
Learning to Evaluate Image Captioning(CVPR 2018)
learning based evaluation metric. (rule-based metrics)
BLEU, METEOR, ROUGE, CIDEr: mainly measure the world overlap between generated and reference captions.
SPICE: measures the similarity of scene graphs constructed from the candidate and reference sentence, correlates well with human judgments, but fails to capture the syntactic structure of a sentence.
It is worth nothing that all above mentioned metrics rely solely on similarity between candidate and reference captions, without taking the image into consideration.
Propose a novel learning based discriminative evaluation metric that is directly trained to distinguish between human and machine-generated captions.
Critique: a binary classifier that makes a Turing Test type judgment in which it differentiates between human-written and machine-generated captions.


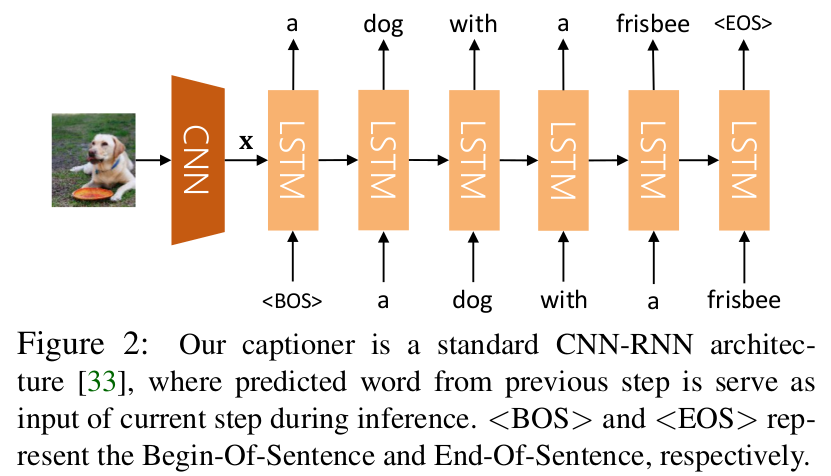
Show and Tell: A Neural Image Caption Generator(CVPR 2015)
directly maximize the probability of the correct description given the image by using the following formulation:

θ are the parameters of our model, I is an image, and S its correct transcription

Encoder:Inception-V2
Decoder:LSTM
Inference:BeamSearch
Attention Mechanism:
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention (ICML 2015)
Highlight:Attention Mechnism(Soft&Hard)
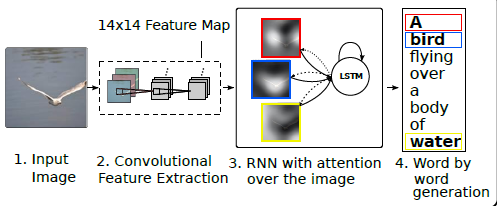
"Soft" attention:different parts,different subregions
"Hard" attention:only one subregion.Random choice
Sumary:
1.Attention involves focus of certain parts of input
2.Soft Attention is Deterministic.Hard attention is Stochastic.
3.Attention is used in NMT, AttnGAN, teaching machines to read.
Image Captioning with Semantic Attention(CVPR 2016)
(Related work)divided Image Caption into two categories:top-down and bottom-up
Bottom-up: the classical ones(templated-based), start with visual concepts, objects, attributes, words and phrases, and combine them into sentences using language models
Top-down: the modern ones(end-to-end), translate from a visual representation to a language counterpart. The visual representation comes from a convolutional neural network which is often pretrained for image classification on large-scale datasets. Translation is accomplished through recurrent neural networks based on language models.

multi-label classifier
SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning(CVPR 2017)
Highlight:Spatial and Channel-Wise Attention


Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning(CVPR 2017)
Hightlight:Adaptive Attention
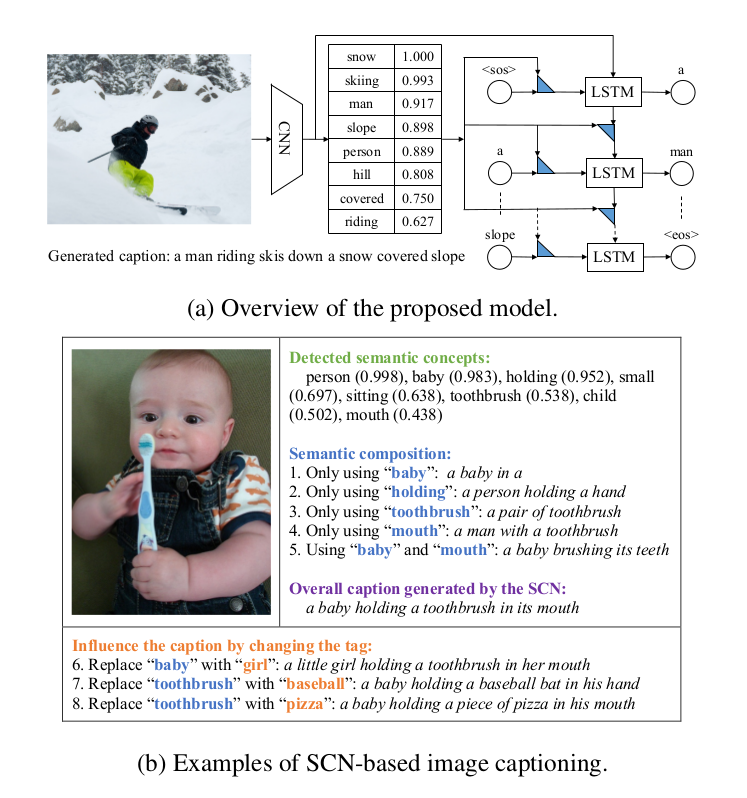
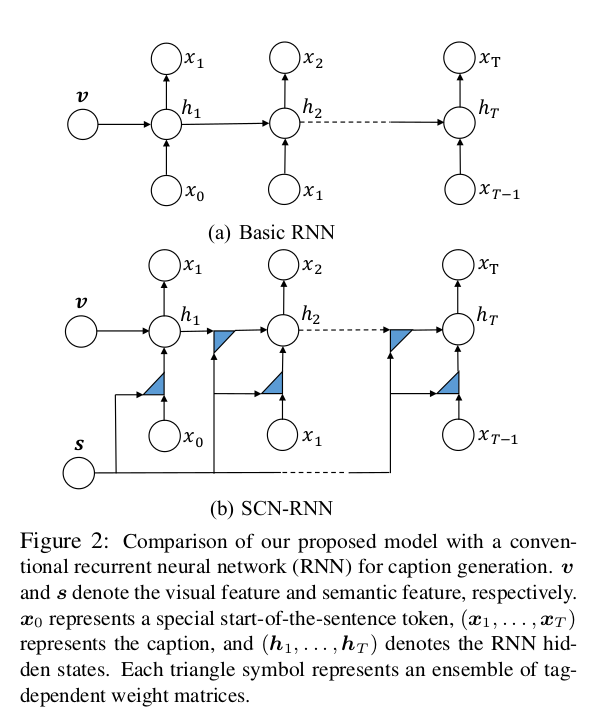
Semantic Compositional Networks for Visual Captioning(CVPR 2017)
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering(CVPR 2018)
In the human visual system, attention can be focused volitionally by top-down signals determined by the current task(e.g.,looking for something), and automatically by bottom-up signals associated with unexpected, novel or salient stimuli.
top-down:attention mechanisms driven by non-visual or task-specific context; feature weights;
bottom-up:purely visual feed-forward attention mechanisms;based on Faster-RCNN proposes image regions (feature vector);



Stylized Caption: SentiCap, StyleNet, SemStyle
SentiCap:Generating Image Descriptions with Sentiments (AAAI 2016)
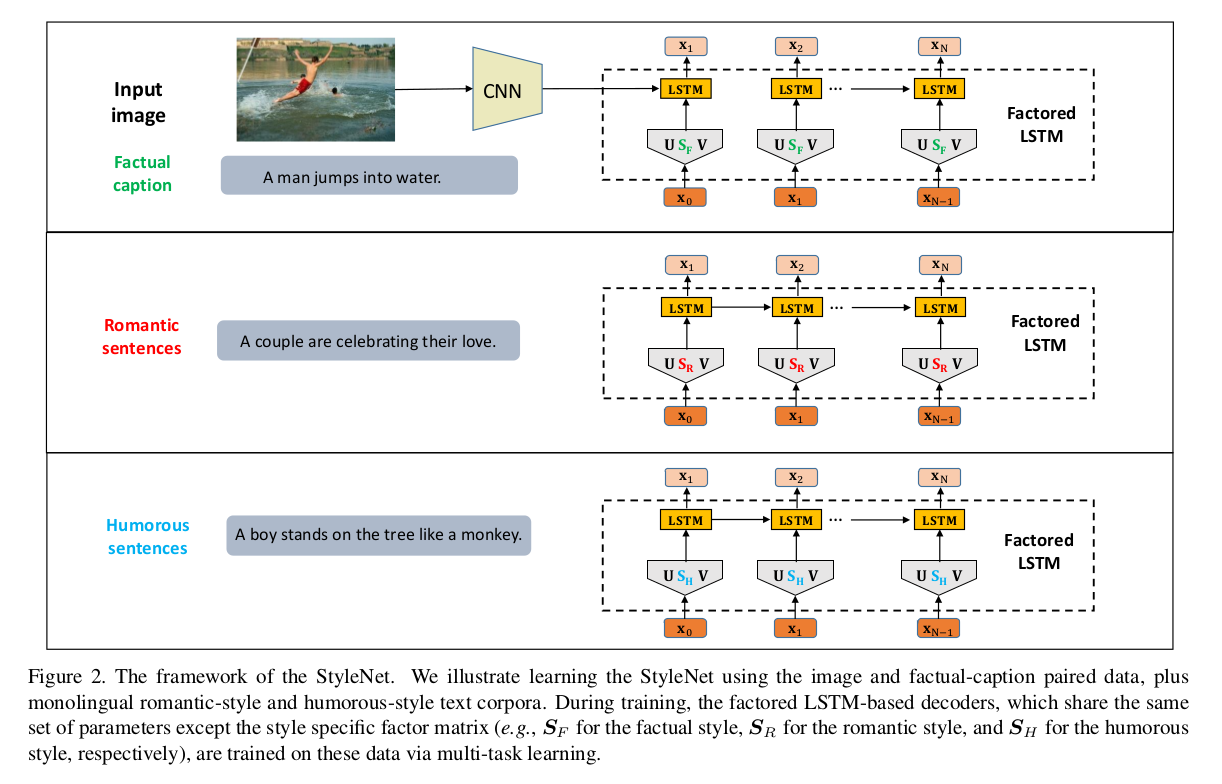
StyleNet: Generating Attractive Visual Captions with Styles (CVPR 2017)
produce attractive visual captions with styles only using monolingual stylized language corpus (without images) and standard factual image/video-caption pairs.
SemStyle: Learning to Generate Stylised Image Captions using Unaligned Text (CVPR 2018)
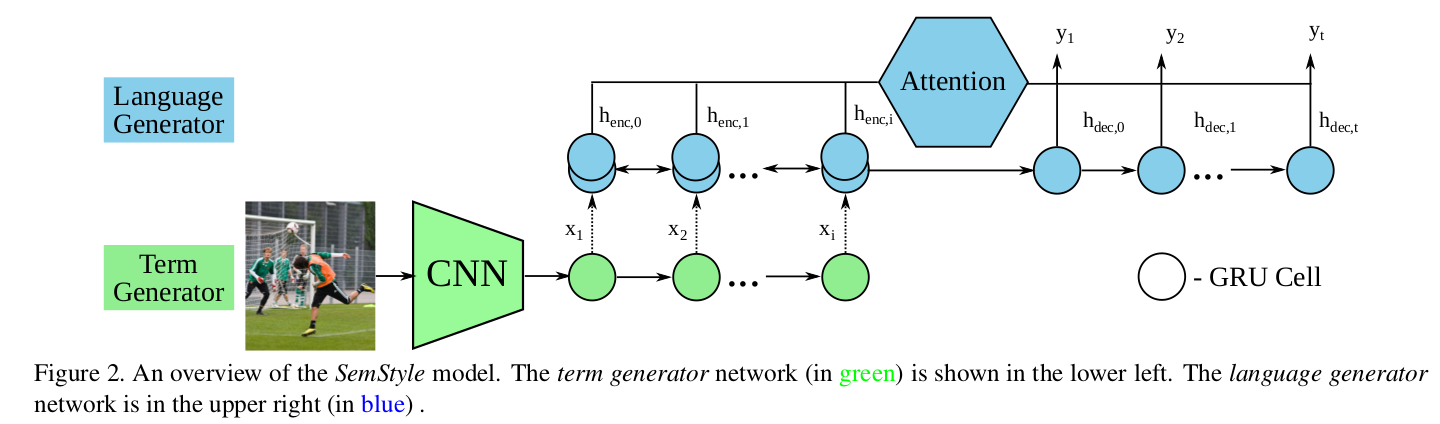
First this model maps the image into a semantic term representation via the term generator, then the language generator uses these terms to generate a caption in the target style.
The term generator takes an image as input, extracts features using a CNN and then generates an ordered term sequence summarising the image semantics.
The language generator takes the term sequences as input, encodes it with an RNN and then using an attention based RNN decodes it into natural language with a specific style.
Two-stage learning strategy: learning the term generator network using only a standard image caption dataset(MSCOCO), learning the language generator network on styled text data(romantic novels)
"Factual" or "Emotional": Stylized Image Captioning with Adaptive Learning and Attention (ECCV 2018)
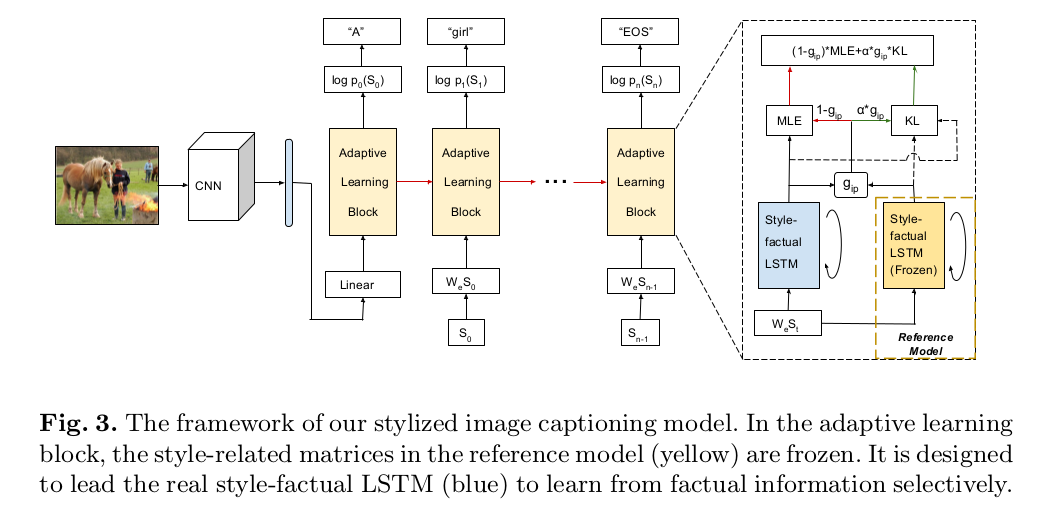
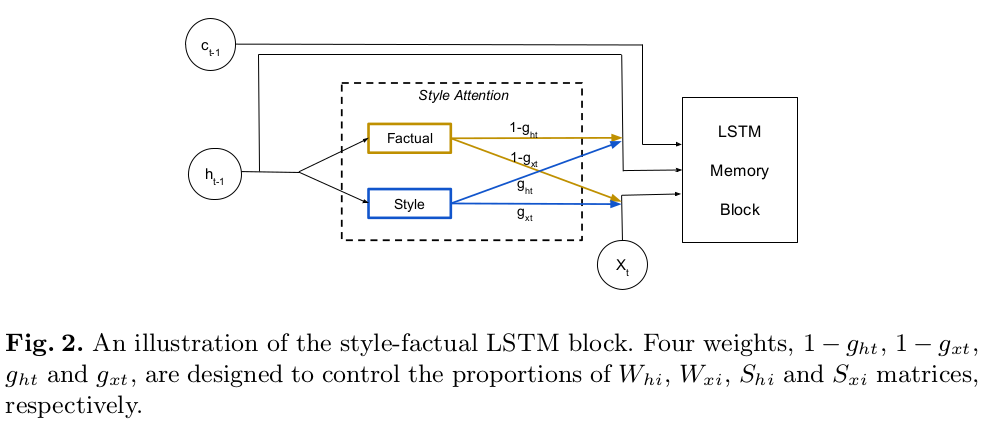
Style-factual LSTM
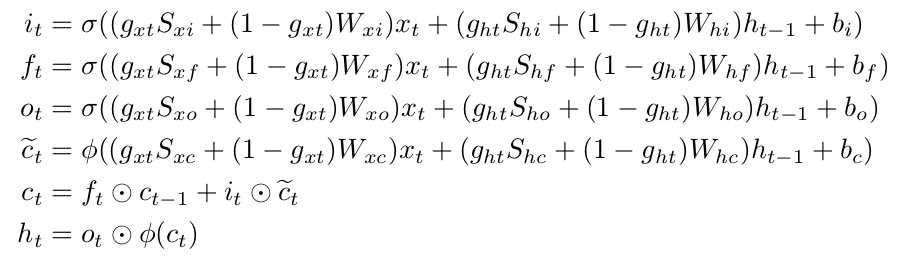
GAN:
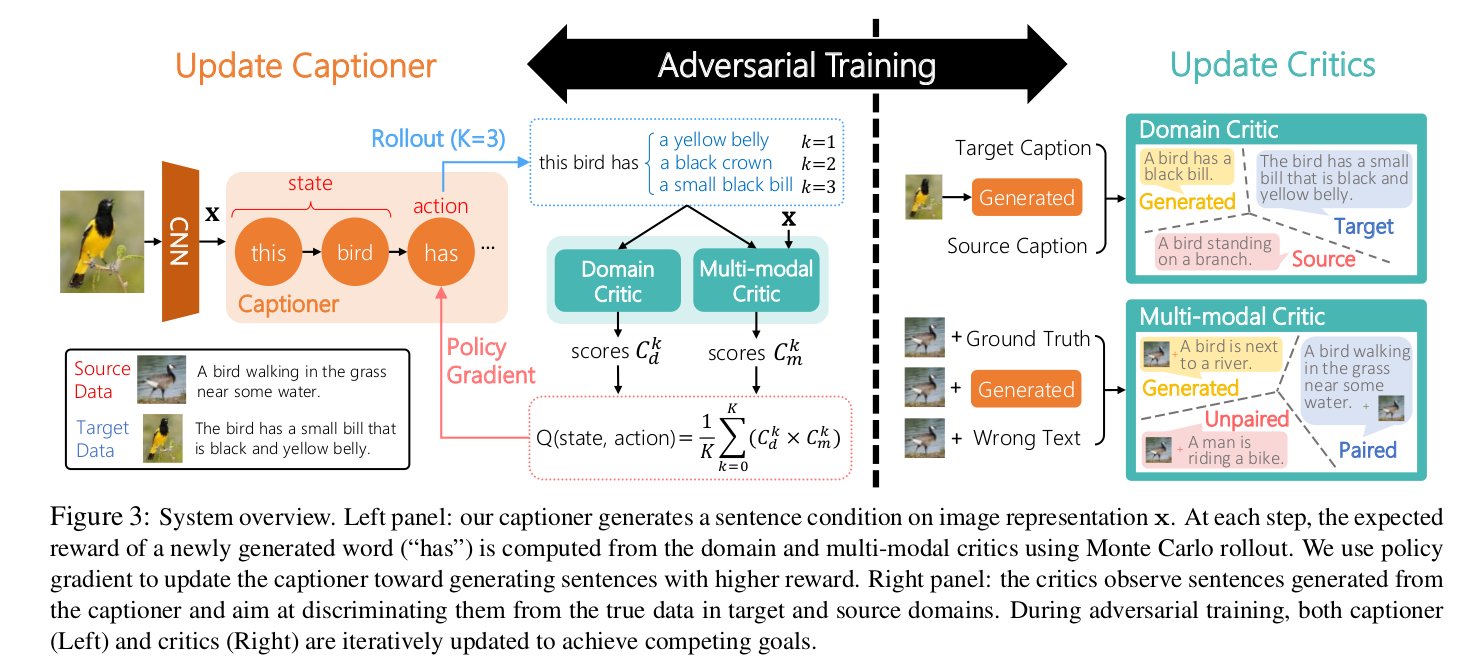
Show, Adapt and Tell: Adversarial Training of Cross-domain Image Captioner (ICCV 2017)
Highlight: Cross-domian
Two New Dataset: CUB-200, TGIF
a "cross-domain" captioner which is trained in a "source" domain with paired data and generalized to other "target" domains with very little cost (e.g., no paired data required)
The domain critic assesses whether the generated captions are indistinguishable from sentences in the target domain.
The multi-modal critic assesses whether an image and its generated caption is a valid pair.
During training, the critics and captioner act as adversaries——captioner aims to generate indistinguishable captions, whereas critics aim at distinguishing them.
Exposure bias: It happens when a model is trained to maximize the likelihood given ground truth words but follow its own predictions during test inference. (curriculum learning, professor forcing, policy gradient)
The first componet is a standard CNN-RNN-based captioner.
The second component consists of two critics to provide reward. One critic assesses the similarity between y and 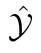 in style. The other critic assesses the relevancy between x and y, given paired data P in the source domain as example pairs.
in style. The other critic assesses the relevancy between x and y, given paired data P in the source domain as example pairs.
compute a reward for each generated sentence y. Both the captioner and two critics are iteratively trained using a novel adversarial training procedure.
Captioner as an Agent
Critics
For cross-domain image captioning, a good caption needs to satisfy two criteria: (1).the generated sentence resembles the sentence drawn from the target domain. (2).the generated sentence is relevant to the input image.
Domain Critic(DC) to classify sentences as "source" domain, "target" domain, or "generated" ones. The DC model consists of an encoder(CNN) and a classifier(a fully connected layer and a softmax layer).
Multi-modal Critic to check the relevance between a sentence y and an image x, MC to classify (x,y) as "paired", "unpaired", "generated" data.
Adversarial Training

Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training (ACM MM 2018)
这篇论文是ACM MM 2018 best paper.
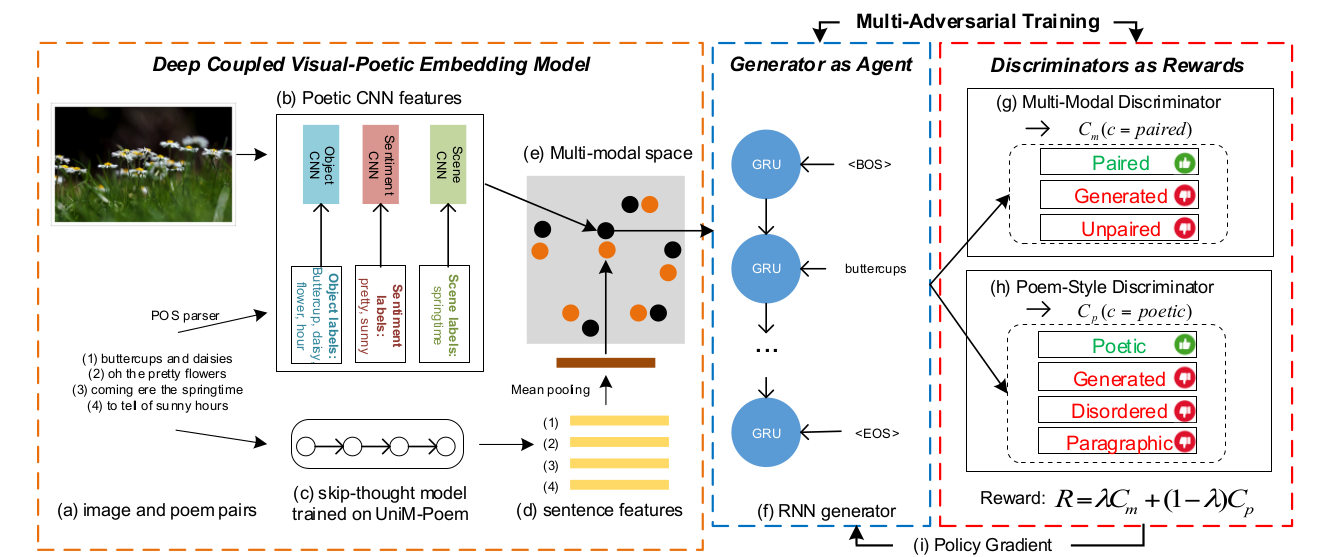
The framework of poetry generation with multi-adversarial training. A deep coupled visual-poetic model(e) is trained by human annotated image-poem pairs(a). The image features (b) are poetic multi-CNN features obtained by fine-tuning CNNs with the extracted poetic symbols (e.g, objects, scenes and sentiments) by a POS parser from poems. The sentence features(d) of poems are extracted from a skip-thought model(c) trained on the largest public poem corpus (UniM-Poem). A RNN-based sentence generator(f) is trained as agent and two discriminators considering multi-modal (g) and poem-style (h) critics of a generated poem to a given image provide rewards to policy gradient(i). POS parser extracts Part-Of-Speech words from poems.
The framework consists of several parts: (1) a deep coupled visual-poetic embedding model to learn poetic representations from images, and (2) a multi-adversarial training procedure optimized by policy gradient.
image embedding :
poem embedding: 
The image and poem are embedded together by minimizing a pairwise ranking loss with dot-product similarity:

mk is a contrastive(irrelevant unpaired) poem for image embedding x, and vice-versa with xk .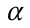 denotes the constrastive margin.
denotes the constrastive margin.
RL:
Self-critical Sequence Training for Image Captioning (CVPR 2017)
FC models
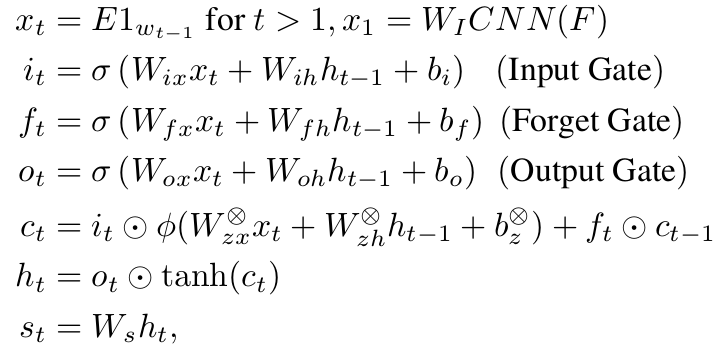
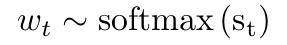
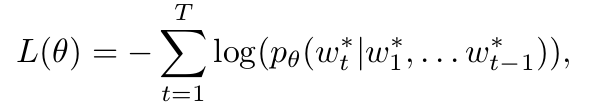
Attention Model (Att2in)
Attention Model (Att2all)
Reinforcement Learning
Sequence Generation as an RL problem
agent, environment, action, state, reward
the goal of training is to minimize the negtive expected reward:
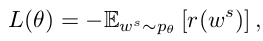
typical: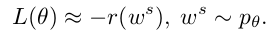
Policy Gradient with Reinforce
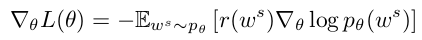
In practice the expected gradient can be approximated using a single Monto-Carlo sample
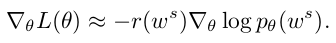
Reinforce with a Baseline
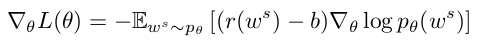
The baseline b can be arbitrary function, as long as it does not depend on the "action" ws
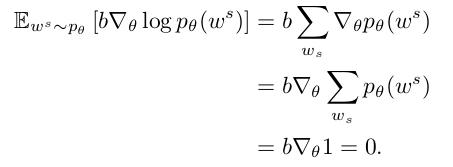
The baseline does not change the expected gradient, but importantly, it can reduce the variance of the gradient esimate.
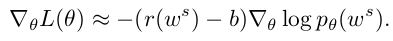
Final Gradient Expression
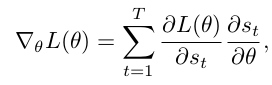
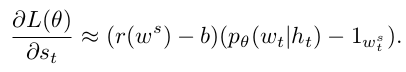
Self-critical sequence training (SCST)
The central idea of the SCST approach is to baseline the REINFORCE algorithm with the reward obtained by the current model under the inference algorithm used at test time.
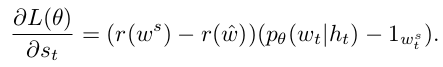
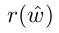 is the reward obtained by the current model under the inference algorithm used at test time.
is the reward obtained by the current model under the inference algorithm used at test time.
Deep Reinforcement Learning-based Image Captioning with Embedding Reward (CVPR 2017)
A decision-making framework for image captioning.
A "policy network" and a "value network" to collaboratively generate captions.
Compositional Architecture:
Review Networks for Caption Generation (NIPS 2016)
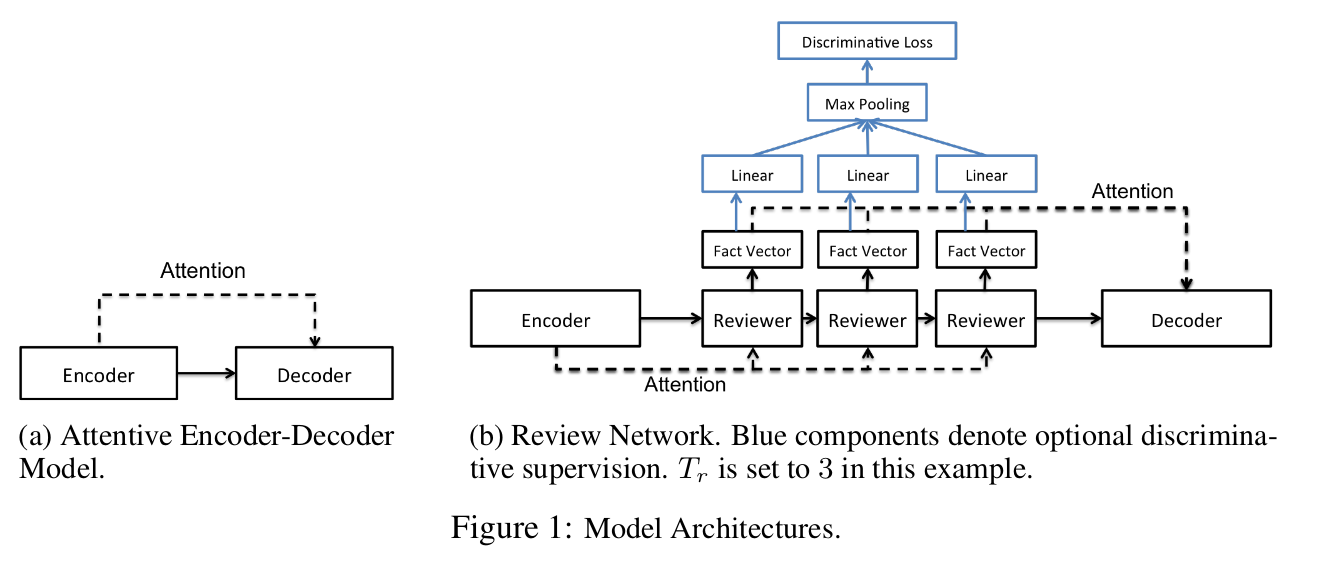

Reviewer
Tr: a hyperparameter that specifies the number of review steps
The intuition behind the reviewer module is to review all the information encoded by the encoder and learn thought vectors that are a more compact, abstractive, and global representation than the original encoder hidden states.
The reviewer performs Tr review steps on the encoder hidden states H and outputs a thought vector ft after each step. 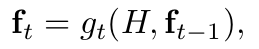
Attentive Input Reviewer(common setting in RNNs)
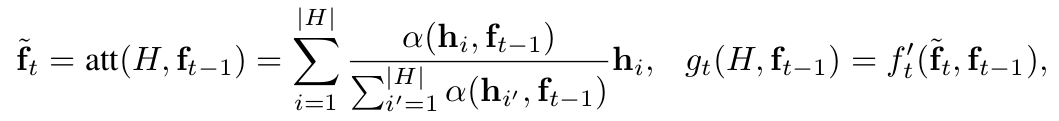
Attentive Output Reviewer()
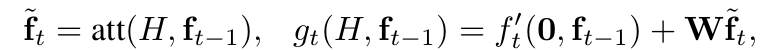
Weight Tying
Recurrent Fusion Network for Image Captioning (ECCV 2018)
All existing models employ only one encoder, so the performance heavily depends on the expressive ability of the deployed CNN.
To exploit complementary information from multiple encoders, propose a Recurrent Fusion Network(RFNet) for image captioning.
Ensemble and Fusion: The combining process can occur at the input, intermediate, and output stage of the target model. RFNet can be regarded as a kind of intermediate fusion methods.
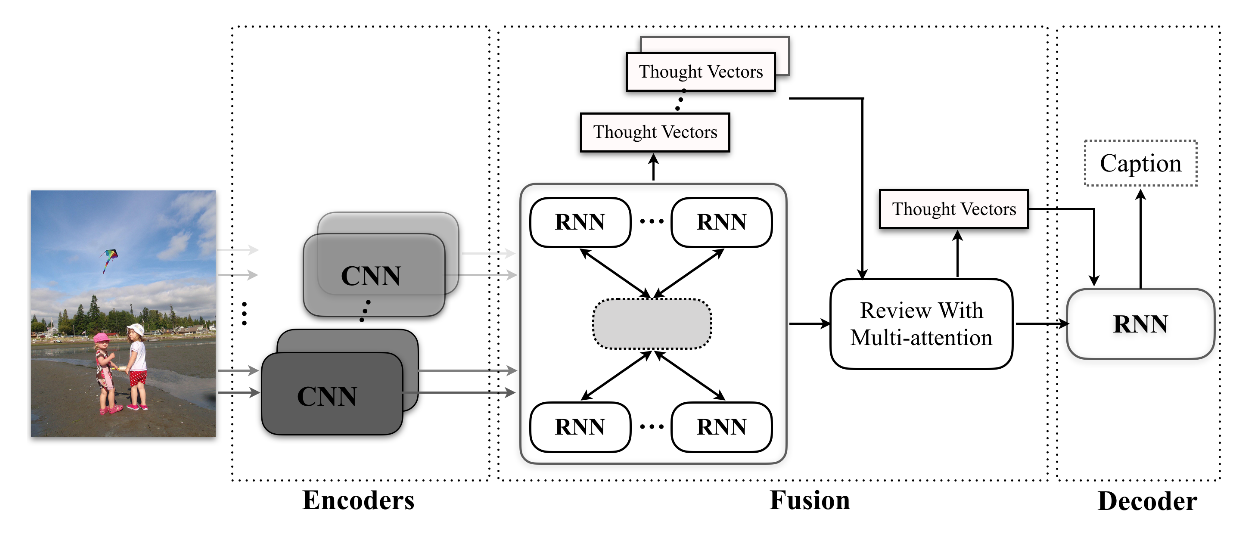
Multiple CNNs are employed as the encoders and a recurrent fusion procedure is inserted after the encoders to form better representations for the decoder. The fusion procedure consists of two stages.
The first stage exploits interactions among the representations from multiple CNNs to generate multiple sets of thought vectors.
The second stage performs multi-attention on the sets of thought vectors from the first stage, and generates a new set of thought vectors for the decoder.
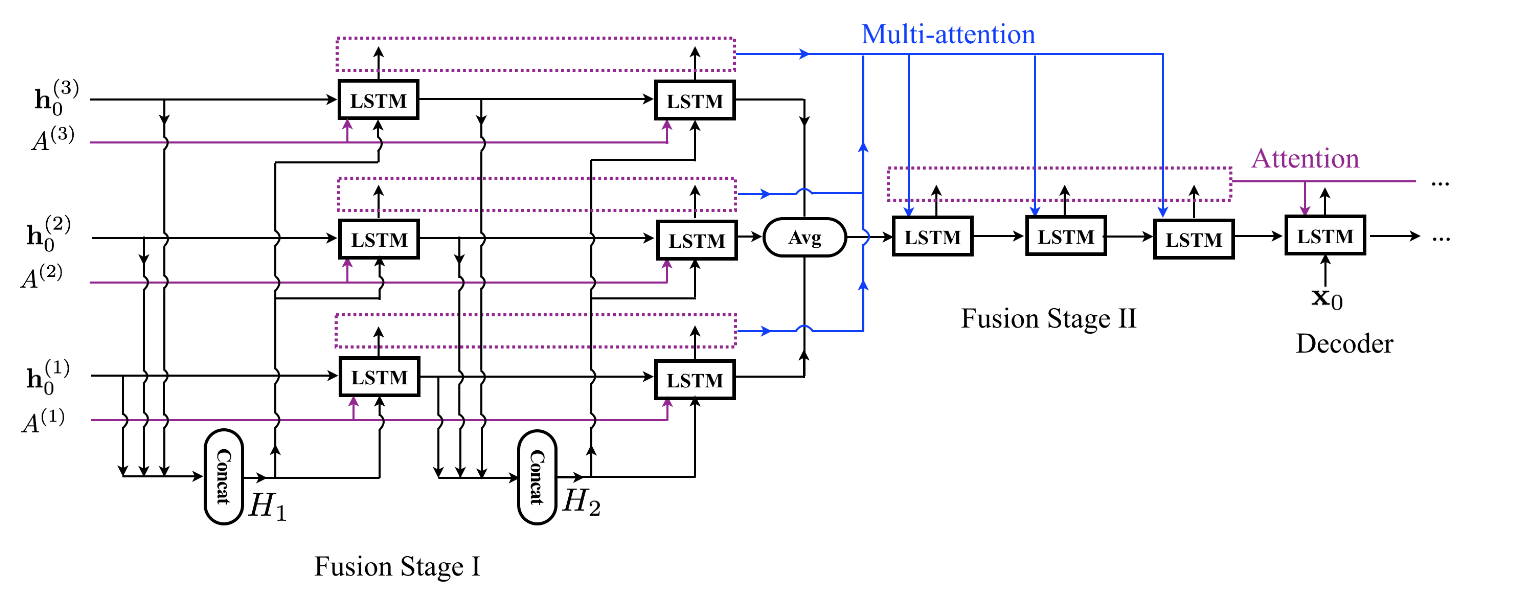
M(上图M=3) CNNs serve as the encoders. The numbers of steps in stages I and II are denoted as T1(T1=2) abd T2(T2=3)
The hidden states from stage I and II are regarded as the thought vectors.
The fusion stage I contains M review componets. The input of each review component at each time step is the concatenation of hidden states from all components at the previous time step. Each review component outputs the hidden state as a thought vector.
The fusion stage II is a review component that performs the multi-attention mechanism on the multiple sets of thought vectors from the fusion stage I.
Fusion Stage I
At time step t, the transition of the m-th review compoent is computed as
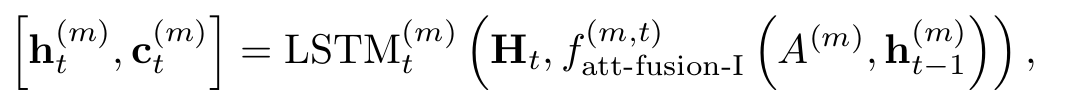

 is the attention model for the m-th review component at time step t.
is the attention model for the m-th review component at time step t.
Stage I can be regarded as a grid LSTM with independent attention mechanisms. M x T1 LSTMs are used in fusion stage I.
The set of thought vectors generated from the m-th component is denoted as :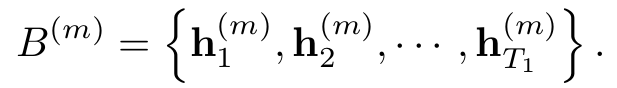
Fusion Stage II


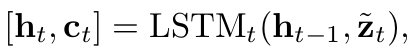
The hidden states of fusion stage II are collected to form the thought vector set:
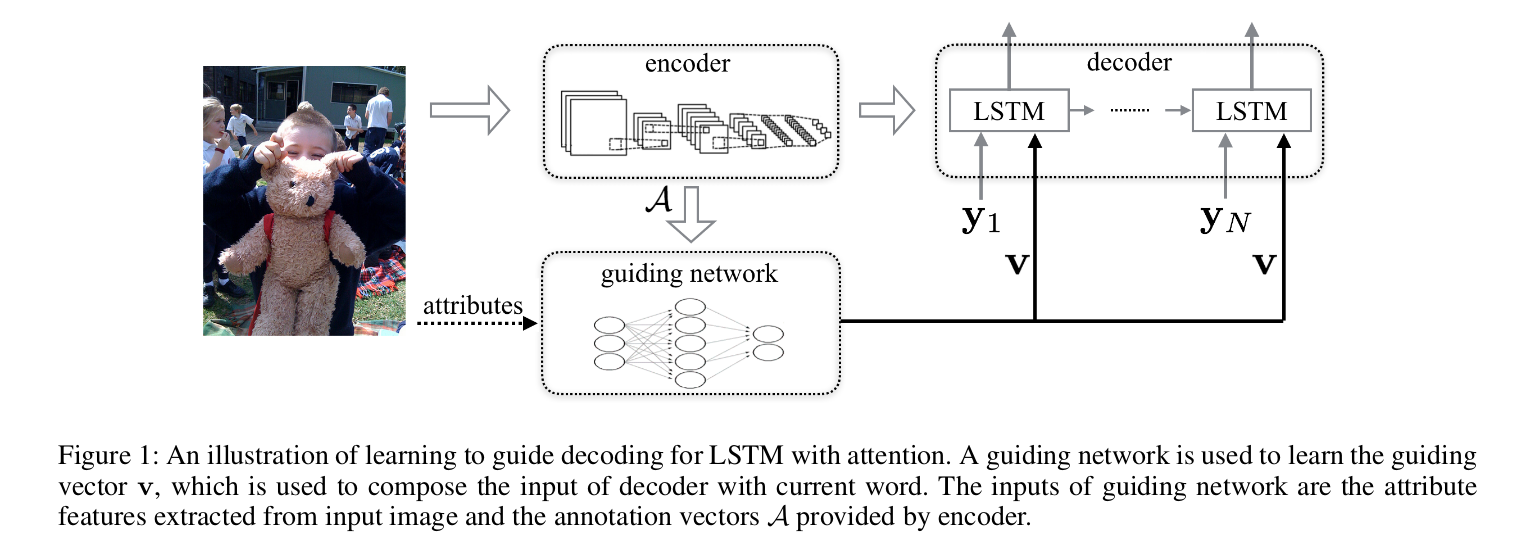
Learning to Guide Decoding for Image Captioning (AAAI 2018)
这篇和之前的RFNet是同一个作者, 文章的风格也极其相似.
Convolutional Image Captioning (CVPR 2018)
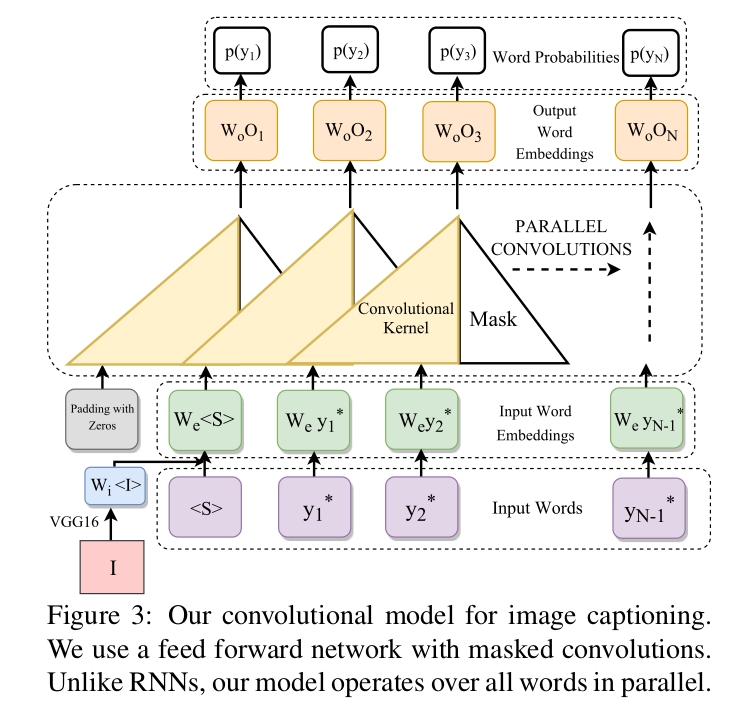
As the figure illustrates, our technique contains three main components similar to the RNN technique. The first and the last components are word embeddings in both cases. Masked convolutions are employed in CNN-based approach. This component, unlike the RNN, is feed-forward without any recurrent function.
Inference. a simple feed-forward deep net,fw for modeling  Prediction of a word yi relies on past words y<i or their representations:
Prediction of a word yi relies on past words y<i or their representations: 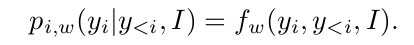
To disallow convolution operations from using information of future word tokens, we use masked convolutional layers that operate omly on 'past' data.
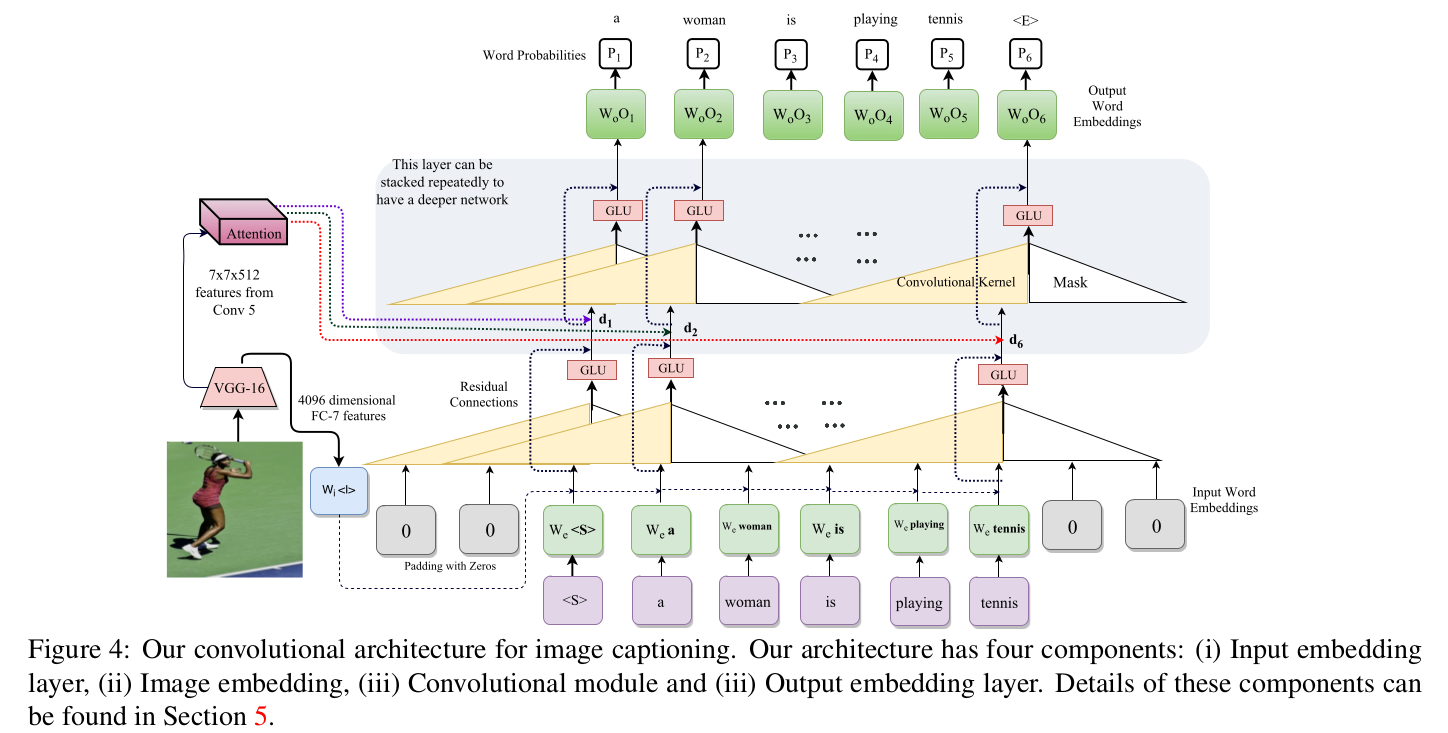
A Neural Compositional Paradigm for Image Captioning (NIPS 2018)
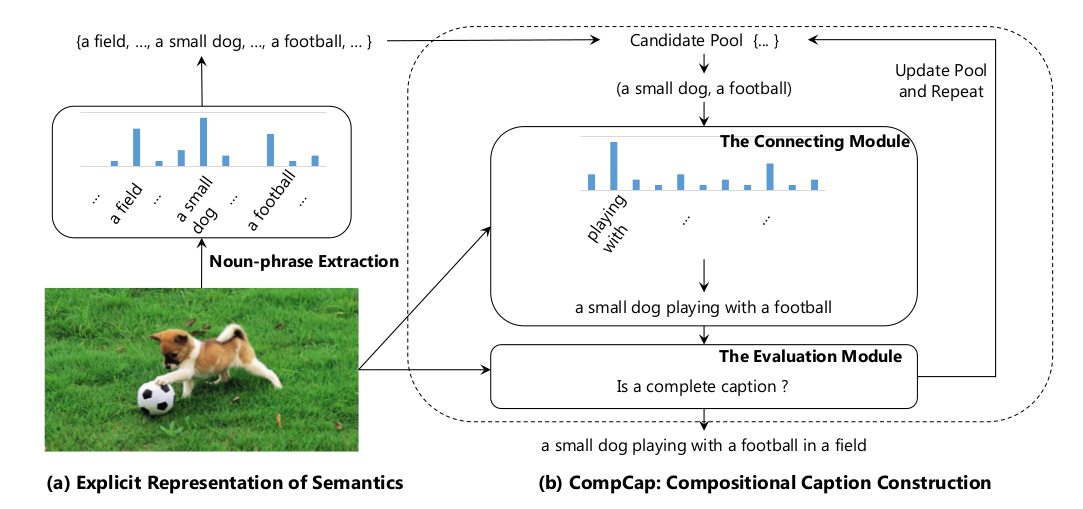
Image Captioning 经典论文合辑的更多相关文章
- Image Caption论文合辑2
说明: 这个合辑里面的论文不全是Image Caption, 但大多和Image Caption相关, 同时还有一些Workshop论文. Guiding Long-Short Term Memory ...
- Image Paragraph论文合辑
A Hierarchical Approach for Generating Descriptive Image Paragraphs (CPVR 2017) Li Fei-Fei. 数据集地址: h ...
- Medical Image Report论文合辑
Learning to Read Chest X-Rays:Recurrent Neural Cascade Model for Automated Image Annotation (CVPR 20 ...
- 【OpenCV入门教程之十四】OpenCV霍夫变换:霍夫线变换,霍夫圆变换合辑
http://blog.csdn.net/poem_qianmo/article/details/26977557 本系列文章由@浅墨_毛星云 出品,转载请注明出处. 文章链接:http://blog ...
- 给力Mac下的思维整理软件,思维导图软件合辑
给力Mac下的思维整理软件,思维导图软件合辑 1.Mindjet MindManager for mac 10.0.211 经典的头脑风暴思维导图软件 最新破解Mindjet MindManager ...
- 【OpenCV新手教程之十四】OpenCV霍夫变换:霍夫线变换,霍夫圆变换合辑
本系列文章由@浅墨_毛星云 出品,转载请注明出处. 文章链接:http://blog.csdn.net/poem_qianmo/article/details/26977557 作者:毛星云(浅墨) ...
- 【Tips】史上最全H1B问题合辑——保持H1B身份终级篇
[Tips]史上最全H1B问题合辑——保持H1B身份终级篇 2015-04-10留学小助手留学小助手 留学小助手 微信号 liuxue_xiaozhushou 功能介绍 提供最真实全面的留学干货,帮您 ...
- SSH三大框架合辑的搭建步骤
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- 【OpenCV新手教程之十二】OpenCV边缘检測:Canny算子,Sobel算子,Laplace算子,Scharr滤波器合辑
本系列文章由@浅墨_毛星云 出品,转载请注明出处. 文章链接:http://blog.csdn.net/poem_qianmo/article/details/25560901 作者:毛星云(浅墨) ...
随机推荐
- [React] Recompose: Override Styles & Elements Types in React
When we move from CSS to defining styles inside components we lose the ability to override styles wi ...
- 5.7-基于Binlog+Position的复制搭建
基本环境 Master Slave MySQL版本 MySQL-5.7.16-X86_64 MySQL-5.7.16-X86_64 IP 192.168.56.156 192.168.56.157 ...
- 开源库Fab-Transformation简单使用解析
转载请注明出处王亟亟的大牛之路 相似于IPhone的悬浮按钮的操作,仅仅只是是固定的,当然经过自己的改动也能够动.这边仅仅是给伸手党一个福祉,外加加上一些自己的理解.让大家能够拿来就用.看了就懂,废话 ...
- SQL生成n位随机字符串
--1.随着newid() go --创建一个视图(因为不能在功能直接用于newid()) create view vnewid as select newid() N'MacoId'; go --创 ...
- ANT下载与安装--windows
原文:ANT下载与安装--windows 1.下载地址 http://ant.apache.org/bindownload.cgi: 2.版本信息 1.10.2 .zip archive 对应jdk ...
- CodeBlocks提供了预编译的WxWidgets模块,并预置TDM
Miscellaneous For Windows, we also provide the pre-compiled wxWidgets, version 2.8.12 used to compil ...
- java获取本机IP地址,非127.0.0.1
综合了网上找的代码,整理的,Windows和Linux都可以用. private static String getHostIp(){ try{ Enumeration<NetworkInter ...
- Scrollbox的滚动条事件scrollbar事件的处理(Lazarus)
没办法,改源代码: 找到:Forms单元中scrollbox的父类: TScrollingWinControl = class(TCustomControl) 改: { TScrollingWi ...
- 正割函数(sec)
1. 定义 正割与余弦互为倒数,余割与正弦互为倒数.即: ⎧⎩⎨⎪⎪⎪⎪secθ=1cosθcscθ=1sinθ 也即在几何上,设 △ABC,∠C=90°,AC=b,BC=a,AB=c, 正割函数:s ...
- 在当前页获取父窗口中母版页中的服务器控件的ID
parent.document.getElementById("ctl00_ContentPlaceHolder1_txt_name").value=""; A ...