Binary classification - 聊聊评价指标的那些事儿【回忆篇】
在解决分类问题的时候,可以选择的评价指标简直不要太多。但基本可以分成两2大类,我们今分别来说道说道
- 基于一个概率阈值判断在该阈值下预测的准确率
- 衡量模型整体表现(在各个阈值下)的评价指标
在说指标之前,咱先把分类问题中会遇到的所有情况简单过一遍。36度的北京让我们举个凉快一点的例子-我们预测会不会下雨!横轴是预测概率从0-1,红色的部分是没下雨的日子(负样本),蓝色的部分是下雨的日子(正样本)。在真实情况下我们很难找到能对正负样本进行完美分割的分类器,所以我们看到在预测概率靠中间的部分,正负样本存在重合,也就是不管我们阈值卡在哪里都会存在被错误预测的样本。
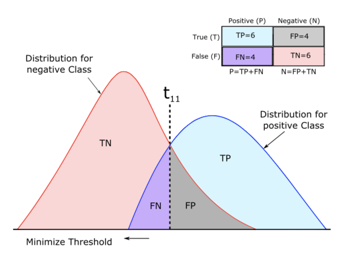
上述分布中的四种情况,可以简单的用confusion matrix来概括

TP:预测为正&真实为正
FP:预测为正&真实为负
TN:预测为负&真实为负
FN:预测为负&真实为正
基于阈值的指标
分类模型输出的是每个样本为正的概率,我们要先把概率转换成0/1预测。给定一个阈值,我们把预测概率大于阈值的样本预测为正,小于的为负。这时就会出现上述confustion matrix里面的四种情况。那我们该如何去评价模型表现呢?
新手视角- Accuracy!
这应该是大多数人第一个知道的评价指标,它把正负样本混在一起去评价整体的分类准确率。
\[Accuracy = \frac{TP + TN}{TP + TN + FN + FP}\]
老手会用一个在所有tutorial里面都能看到的Imbalance Sample的例子来告诉你,如果你的正样本只有1%,那全部预测为负你的准确率就是99%啦 - so simple and naive ~.~
当然Accuracy也不是不能用,和正样本占比放在一起比较也是能看出来一些信息的。但Accuracy确实更适用正负样本55开,且预测不止针对正样本的情况。
Accuracy知道咋算就可以啦,在解决实际问题的时候,往往会使用更有指向性的指标, 而且一般都会同时选用2个以上的指标因为不同指标之间往往都有trade-off
当目标是对正样本进行准确预测 - precision, recall, F1
precision从预测的角度衡量预测为正的准确率,recall从真实分布的角度衡量预测为正的准确率。precision和recall存在trade-off, 想要挑选出更多的正样本,就要承担预测为正准确率下降的风险。例如在飞机过安检时,想要保证危险物品基本都被识别出来,就肯定要承担一定的误判率。不过在这种情境下查不出危险物品显然比让误判乘客多开包检查一遍要重要的多。
\[
\begin{align}
precision &= \frac{TP}{TP+FP} \\
recall &= \frac{TP}{TP+FN}
\end{align}
\]
既然有trade-off,一般就会用可以综合两个指标的复合指标 - F1 Score
\[
F1 =\frac{1}{\frac{1}{precision} + \frac{1}{recall}}= \frac{precision * recall}{precision + recall}
\]
其实简单一点直接对precision,recall求平均也可以作为复合指标,但F1用了先取倒数再求平均的方式来避免precision或recall等于0这种极端情况的出现
当目标是对真实分布进行准确预测 - sensitivity(recall), specifity, fpr
sensitivity, sepcifity都从真实分布的角度,分别衡量正/负样本预测的准确率。这一对搭配最常在医学检验中出现,衡量实际生病/没生病的人分别被正确检验的概率。正确检验出一个人有病很重要,同时正确排除一个人没生病也很重要。
\[
\begin{align}
sensitivity &= recall \\
specifity & =\frac{TN}{TN + FP} \\
\end{align}
\]
如果specifity对很多人来说很陌生的话,它兄弟很多人一定知道fpr。fpr和recall(tpr)一起构成了ROC曲线。这一对的tradeoff同样用医学检验的逻辑来解释就是,医生既不希望遗漏病人的病情(recall),要不希望把本身没病的人吓出病来(fpr)。
\[
fpr = \frac{FP}{TN+FP} = 1- specifity
\]
和阈值相关经常用到的指标差不多就是这些。这些指标的计算依赖于阈值的确定,所以在应用中往往用验证集来找出使F1/accuracy最大的阈值,然后应用于测试集,再用测试集的F1/accuracy来评价模型表现。下面是几个应用上述指标的kaggle比赛
- F1 score
https://www.kaggle.com/c/quora-insincere-questions-classification/overview/evaluation - accuracy
https://www.kaggle.com/c/titanic/overview/evaluation
不过开始用到和阈值相关的评价指标有时是在模型已经确定以后。第一步在确定模型时,往往还是需要一些可以综合衡量模型整体表现的指标。简单!粗暴!别整啥曲线阈值的,你给我个数就完了!
综合评价指标
综合评价指标基本都是对上述指标再加工的产物。对应的kaggle比赛会持续更新。
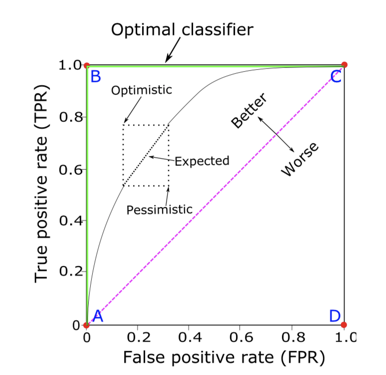
tpr(recall) + fpr = ROC-> AUC
随着阈值从1下降到0,我们预测为正的样本会逐渐变多,被正确筛选出的正样本会逐渐增多,但同时负样本被误判为正的概率也会逐渐上升。
整个遍历阈值的过程可以用ROC曲线来表示,横轴是误判率(fpr),纵轴是准确率(tpr/recall/sensitivity)。但是给你两个分类器想要直接比较谁的ROC曲线会有点困难,所以我们用一个scaler来描述ROC曲线就是AUC - Area under curve。 ROC曲线下的面积越大越接近完美的分类器,而对角线50%是随机猜正负就可以得到的AUC。
Kaggle链接 https://www.kaggle.com/c/santander-customer-transaction-prediction/overview/evaluation
AUC 适用于正负样本相对balance的情况,且分类问题对模型预测概率的准确度没有要求的情况。详见【实战篇】
precision + recall = AUCPR(AP)
和上述ROC-AUC的思路相同。随着阈值从1下降到0,预测为正的样本变多,被正确筛选出的正样本增多,但同时预测为正的准确率会下降。
这样我们得到PR曲线,以及曲线下的面积AUCPR。有时AUCPR也被称作AP,就是对所有recall取值对应的precision求平均。第一眼看上去我也被糊弄了,一直当成两个概念来记。但是式子一写出来,妈呀这俩不是一个东西么。
\[
AUCPR = \sum_1^K\Delta{r(k)} * p(k) = \int_o^1 {p(r) dr} = AP
\]
AP 刚好弥补AUC曲线的不足,适用于正负样本imbalance的情况,或者我们更关心模型在正样本上表现的情况。但AP同样不能保证模型预测概率的准确率。详见【实战篇】
cross-entropy loss
cross-entropy放在这里会有点奇怪,因为本质上它是和这里其他所有指标都不同的存在。其他的评价指标评价的是0/1的分类效果,或者更准确说是对排序效果(根据阈值把预测值从大到小分成0/1两半)进行评价。但是cross-entropy是直接对预测概率是否拟合真实概率进行评价。
\[
L = -\sum_{i=1}^N y_i * log p_i + (1-y_i) * log(1-p_i)
\]
kaggle链接 https://www.kaggle.com/c/statoil-iceberg-classifier-challenge/overview/evaluation
cross-entropy弥补了AP和AUC的不足。如果分类目标其实是获得对真实概率的估计的话,使用cross-entropy应该是你的选择。详见【实战篇】
*Mean F1 Score
kaggle链接 https://www.kaggle.com/c/instacart-market-basket-analysis/overview/evaluation
第一次见到这个指标是在Instacart的kaggle比赛里面。这里的mean不是指的对所有阈值下的F1求平均值而是对每个order_id的多个product_id求F1,再对所有order_id的F1求平均,有点绕...
之所以把这个评价指标也放在这里是因为这个特殊的评价方法会对你如何split训练集/测试集,以及如何选定最优的阈值产生影响。有兴趣的可以来试一试,反正我觉得自己是把能踩的坑都踩了一个遍,欢迎大家一起来踩坑 >_<
Reference
- Alaa Tharwat,Classification assessment methods,Applied Computing and Informatics
- Nan Ye,Kian Ming A. Chai,Wee Sun Lee,Hai Leong Chieu,Optimizing F-Measures: A Tale of Two Approaches,
- https://en.wikipedia.org/wiki/Confusion_matrix
Binary classification - 聊聊评价指标的那些事儿【回忆篇】的更多相关文章
- Binary classification - 聊聊评价指标的那些事儿【实战篇】
分类问题就像披着羊皮的狼,看起来天真无害用起来天雷滚滚.比如在建模前你思考过下面的问题么? 你的分类模型输出的概率只是用来做样本间的相对排序,还是概率本身? 你的训练数据本身分布如何是否存在Imbal ...
- Logistic Regression Using Gradient Descent -- Binary Classification 代码实现
1. 原理 Cost function Theta 2. Python # -*- coding:utf8 -*- import numpy as np import matplotlib.pyplo ...
- 【Linear Models for Binary Classification】林轩田机器学习基石
首先回顾了几个Linear Model的共性:都是算出来一个score,然后做某种变化处理. 既然Linear Model有各种好处(训练时间,公式简单),那如何把Linear Regression给 ...
- 聊聊多线程哪一些事儿(task)之 一
多线程,一个多么熟悉的词汇,作为一名程序员,我相信无论是从事什么开发语言,都能够轻轻松松说出几种实现多线程的方式,并且在实际工作种也一定用到过多线程,比如:定时器.异步作业等等,如果你说你没有用过多线 ...
- 聊聊多线程哪一些事儿(task)之 二 延续操作
hello,又见面啦,昨天我们简单的介绍了如何去创建和运行一个task.如何实现task的同步执行.如何阻塞等待task集合的执行完毕等待,昨天讲的是task的最基本的知识点,如果你没有看昨天的博客, ...
- 聊聊多线程那一些事儿(task)之 三 异步取消和异步方法
hello,咋们又见面啦,通过前面两篇文章的介绍,对task的创建.运行.阻塞.同步.延续操作等都有了很好的认识和使用,结合实际的场景介绍,这样一来在实际的工作中也能够解决很大一部分的关于多线程的业务 ...
- 聊聊多线程哪一些事儿(task)之 三 异步取消和异步方法
hello,咋们又见面啦,通过前面两篇文章的介绍,对task的创建.运行.阻塞.同步.延续操作等都有了很好的认识和使用,结合实际的场景介绍,这样一来在实际的工作中也能够解决很大一部分的关于多线程的业务 ...
- 聊聊多线程那一些事儿 之 五 async.await深度剖析
hello task,咱们又见面啦!!是不是觉得很熟读的开场白,哈哈你哟这感觉那就对了,说明你已经阅读过了我总结的前面4篇关于task的文章,谢谢支持!感觉不熟悉的也没有关系,在文章末尾我会列出前四 ...
- 聊聊RabbitMQ那一些事儿之一基础应用
聊聊RabbitMQ那一些事儿之一基础应用 Hi,各位热爱技术的小伙伴您们好,今年的疫情害人啊,真心祝愿您和您的家人大家都平平安安,健健康康.年前到现在一直没有总结点东西,写点东西,不然久了自己感觉自 ...
随机推荐
- C# Winform在win10里弹出无焦点的窗口
原文:C# Winform在win10里弹出无焦点的窗口 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/wangmy1988/article/det ...
- win10系统应用打不开
可能有一些用户升级Win10之后遇到了应用商店.应用打不开或闪退的问题,此时可尝试通过下面的一些方法来解决. 1.点击任务栏的搜索(Cortana小娜)图标,输入Powershell,在搜索结果中右键 ...
- matlab 二元函数的画法
plot:画线(curve,二维空间以及三维空间) surf:画面(surface,一般在三维空间) 1. surf 绘图函数 surf 是 surface 的缩写,表示表面(显然至少三维图像才会有表 ...
- Qt程序调试之Q_ASSERT断言(条件为真则跳过,否则直接异常+崩溃)
在使用Qt开发大型软件时,难免要调试程序,以确保程序内的运算结果符合我们的预期.在不符合预期结果时,就直接将程序断下,以便我们修改. 这就用到了Qt中的调试断言 - Q_ASSERT. 用一个小例子来 ...
- android自定义View绘制天气温度曲线
原文:android自定义View绘制天气温度曲线 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u012942410/article/detail ...
- 汉顺平html5课程分享:6小时制作经典的坦克大战!
记起自己去年參加的一次面试,在做过Java多年的面试官面前发挥的并不好,但他一听说我会html5,立刻眼睛发亮.无论不顾的想要和我签约.. .所以.如今为工作犯愁的朋友们,学好html5,绝对会为你找 ...
- C++该typeid和dynamic_cast
1.typeid在没有虚拟函数的(不相关的动态绑定),typeid它只返回操作对象的实际类型 2.typeid涉及到动态联编问题时(使用基类指针p或者引用p操作派生类对象),typeid(p)返回基类 ...
- SharePoint 2010 WebPart Web部分 总的膏
SharePoint 2010 WebPart Web部分 总的膏 之前写SharePoint WebPart Web部分相关的博客,我们没有做一个索引.网友在查看的时候非常不方便,于 ...
- DELPHI下多线程编程的几个思维误区(QDAC)
有几个网友私下问我一些有关线程的事情.过节写个东西上来大家交流. 思维误区1,自己新建的THREAD是线程,自己的主程序不是线程. 很多人在多线程编程没有把主线程也当作线程.其实主线程也是线程.看起来 ...
- 获取bing图片并自动设置为电脑桌面背景(使用 URLDownloadToFile API函数)
众所周知,bing搜索网站首页每日会更新一张图片,张张漂亮(额,也有一些不合我口味的),特别适合用来做电脑壁纸. 我们想要将bing网站背景图片设置为电脑桌面背景的通常做法是: 上网,搜索bing 找 ...