MySQL 派生表(Derived Table) Merge Optimization
本文将通过演示告诉你:MySQL中派生表(Derived Table)是什么?以及MySQL对它的优化。
Background
有如下一张表:
mysql> desc city;
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| country | varchar(40) | YES | | NULL | |
| population | int(11) | YES | | NULL | |
| city | varchar(40) | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
例如,如果首先考虑选择人口超过10,000人的城市,然后选择那些位于德国的城市,那么可以写这个SQL:
SELECT *
FROM
(SELECT * FROM city WHERE population > 10*1000) AS big_city
WHERE
big_city.country='Germany';
使用 EXPLAIN 命令查看执行计划:
mysql> EXPLAIN SELECT * FROM (SELECT * FROM city WHERE population > 1*1000) AS big_city WHERE big_city.country='Germany' ;
+----+-------------+------------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+------+---------------+------+---------+------+------+-------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 4068 | Using where |
| 2 | DERIVED | City | ALL | Population | NULL | NULL | NULL | 4079 | Using where |
+----+-------------+------------+------+---------------+------+---------+------+------+-------------+
2 rows in set (0.60 sec)
注意:mysql 5.7 需要设置 derived_merge=off,才会有上面的结果。否则MySQL会把临时表合并到外层查询,具体可参见我的另一篇文章《MySQL中的两种临时表》。
MySQL 的做法是:
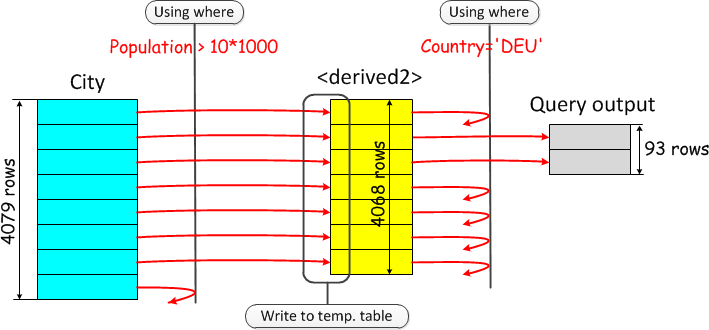
经历如下3个步骤:
- 执行子查询:(SELECT * FROM city WHERE population > 1*1000),正如查询语句中的那样;
- 把子查询的结果写到临时表 big_city ;
- 回读,应用上层SELECT的WHERE条件 big_city.country='Germany' 。
执行这样的子查询是非常低效的,因为扫描基表 city 时没有使用父选择(country ='Germany')的高选择性条件。 我们从City表中读取太多记录,然后我们必须将它们写入一个临时表并再次读取,然后才能过滤掉它们。
Derived table merge in action
如果在MariaDB / MySQL 5.6中运行此查询,则可以得到以下结果:
MariaDB [world]> EXPLAIN SELECT * FROM (SELECT * FROM City WHERE Population > 1*1000) AS big_city WHERE big_city.Country='Germany';
+----+-------------+-------+------+--------------------+---------+---------+-------+------+------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+--------------------+---------+---------+-------+------+------------------------------------+
| 1 | SIMPLE | City | ref | Population,Country | Country | 3 | const | 90 | Using index condition; Using where |
+----+-------------+-------+------+--------------------+---------+---------+-------+------+------------------------------------+
1 row in set (0.00 sec)
从上面的结果可以看出:
- 只有一行输出,说明子查询已经被合并到上级的 SELECT 语句;
- 通过Country列访问City表,Country='Germany' 用来构建表上的 ref 访问;
- 查询将读取大约90行,这是对于之前的4079行读加上4068行临时表读/写的一个很大的改进。
Factsheet
派生表(FROM子句中的子查询)可以在没有 grouping, aggregates, or ORDER BY ... LIMIT 子句时合并到他们的父查询中。这个优化默认开启,可通过如下关闭:
set @@optimizer_switch='derived_merge=OFF'
不支持该优化的Maria和MySQL版本将执行子查询,这可以导致一个著名的Bug(see e.g. MySQL Bug #44802),从MariaDB 5.3+和MySQL 5.6+ 开始,EXPLAIN命令立即执行,无论 derived_merge 如何设置。
Reference:
Derived Table Merge Optimization
MySQL 派生表(Derived Table) Merge Optimization的更多相关文章
- MySQL派生表(derived)优化一例
1.什么是派生表derived 关键字:子查询–>在From后where前的子查询 mysql; +----+-------------+------------+------+-------- ...
- mysql错误:“ Every derived table must have its own alias”(每个派生出来的表都必须有一个自己的别名)
自我感悟: 由此可以延伸,我们得到一个结果集,可以通过as XXX的方式,把结果集给当作一张表来用,以实现子查询: 一般在多表查询时,会出现此错误. 因为,进行嵌套查询的时候子查询出来的的结果是作为一 ...
- MySQL错误:Every derived table must have its own alias
Every derived table must have its own alias 派生表都必须有自己的别名 一般在多表查询时,会出现此错误. 因为,进行嵌套查询的时候子查询出来的的结果是作为一个 ...
- mysql—mysql错误Every derived table must have its own alias解决
Every derived table must have its own alias 这句话的意思是说每个派生出来的表都必须有一个自己的别名. 一般在多表查询时,会出现此错误. 因为,进行嵌套查询的 ...
- MySql 1248 - Every derived table must have its own alias
执行一个sql语句,报错:1248 - Every derived table must have its own alias 提示说每一个衍生出来的表,必须要有自己的别名 执行子查询的时候,外层查询 ...
- 数据库~Mysql派生表注意的几点~关于百万数据的慢查询问题
基础概念 派生表是从SELECT语句返回的虚拟表.派生表类似于临时表,但是在SELECT语句中使用派生表比临时表简单得多,因为它不需要创建临时表的步骤. 术语:*派生表*和子查询通常可互换使用.当SE ...
- mysql 创建表 create table详解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ...
- 修改MYSQL数据库表的字符集
MySQL 乱码的根源是的 MySQL 字符集设置不当的问题,本文汇总了有关查看 MySQL 字符集的命令.包括查看 MySQL 数据库服务器字符集.查看 MySQL 数据库字符集,以及数据表和字段的 ...
- MYSQL优化派生表(子查询)在From语句中的
Mysql 在5.6.3中,优化器更有效率地处理派生表(在from语句中的子查询): 优化器推迟物化子查询在from语句中的子查询,知道子查询的内容在查询正真执行需要时,才开始物化.这一举措提高了性能 ...
随机推荐
- Easyui datagrid 怎么添加操作按钮,rowStyler
说明:本篇文章主要是展示怎么设置easyUI datagrid的格式,包括行样式和列样式,以及添加操作按钮列 开发环境 vs2012 asp.net mvc4 c# 1.效果图 3.HTML代码 & ...
- Vue 单页面应用 SEO SPA single page application advantages and disadvantages
处理 Vue 单页面应用 SEO 的另一种思路 - muwoo - 博客园 https://www.cnblogs.com/tiedaweishao/p/7493971.html SPA网站SEO完美 ...
- Markov and Chebyshev Inequalities and the Weak Law of Large Numbers
https://www.math.wustl.edu/~russw/f10.math493/chebyshev.pdf http://www.tkiryl.com/Probability/Chapte ...
- 解决Windows x64bit环境下无法使用PLSQL Developer连接到Oracle DB中的问题
本文是原创文章,转载请注明出处: http://blog.csdn.net/msdnchina/article/details/46416455 解决Windows x64bit环境下无法使用PLSQ ...
- Impala 安装笔记2一hive和mysql安装
l 安装hive,hive-metastore hive-server $ sudo yum install hive hive-metastore hive-server l 安装mysql ...
- Xmpp学习之Asmack取经-asmack入门(一)
1.XMPPConnection:它主要是用来创建一个跟XMPP服务端的Socket连接.它是与Jabber服务端的默认连接并且已经在RFC 3920中精确定义过了.示例如下: XMPPConnect ...
- [haoi2011]a
一次考试共有n个人参加,第i个人说:“有ai个人分数比我高,bi个人分数比我低.”问最少有几个人没有说真话(可能有相同的分数) 题解:首先,由每个人说的话的内容,我们可以理解为他处在ai+1,n-bi ...
- UVA10561 Treblecross —— SG博弈
题目链接:https://vjudge.net/problem/UVA-10561 题意: 两个人玩游戏,轮流操作:每次往里面添加一个X,第一个得到XXX的获胜. 题解: 详情请看<训练指南&g ...
- 用php描述顺序查找
//顺序查找(数组里查找某个元素) $arr = array(3,55,45,2,67,76,6.7,-65,85,4); function seq_sch($array, $k){ for($i=0 ...
- 【应用】SVG动态 时钟
没有做秒针,只做了分针和时针,5分钟以后来看应该可以看到效果╮(╯-╰)╭ <!DOCTYPE html> <html> <head> <title>& ...